1. 简介
深度学习(Deep Learning)因其计算复杂度或参数冗余,在一些场景和设备上限制了相应的模型部署,需要借助模型压缩、优化加速、异构计算等方法突破瓶颈。
- 模型压缩算法能够有效降低参数冗余,从而减少存储占用、通信带宽和计算复杂度,有助于深度学习的应用部署,具体可划分为如下几种方法(后续重点介绍剪枝与量化):
- 线性或非线性量化:1/2bits, int8 和 fp16等;
- 结构或非结构剪枝:deep compression, channel pruning 和 network slimming等;
- 其他:权重矩阵的低秩分解,知识蒸馏与网络结构简化(squeeze-net, mobile-net, shuffle-net)等;
- 模型优化加速能够提升网络的计算效率,具体包括:
- Op-level的快速算法:FFT Conv2d (7x7, 9x9), Winograd Conv2d (3x3, 5x5) 等;
- Layer-level的快速算法:Sparse-block net [1] 等;
- 优化工具与库:TensorRT (Nvidia), Tensor Comprehension (Facebook) 和 Distiller (Intel) 等;
- 异构计算方法借助协处理硬件引擎(通常是PCIE加速卡、ASIC加速芯片或加速器IP),完成深度学习模型在数据中心或边缘计算领域的实际部署,包括GPU、FPGA或DSA (Domain Specific Architecture) ASIC等。异构加速硬件可以选择定制方案,通常能效、性能会更高,目前市面上流行的AI芯片或加速器可参考 [2]。针对数据中心部署应用,通常选择通用方案,会有较完善的生态支持,例如NVIDIA GPU的CUDA生态,或者Xilinx即将推出的xDNN生态:

2. TensorRT基础
TensorRT是NVIDIA推出的深度学习优化加速工具,采用的原理如下图所示,具体可参考[3] [4]:
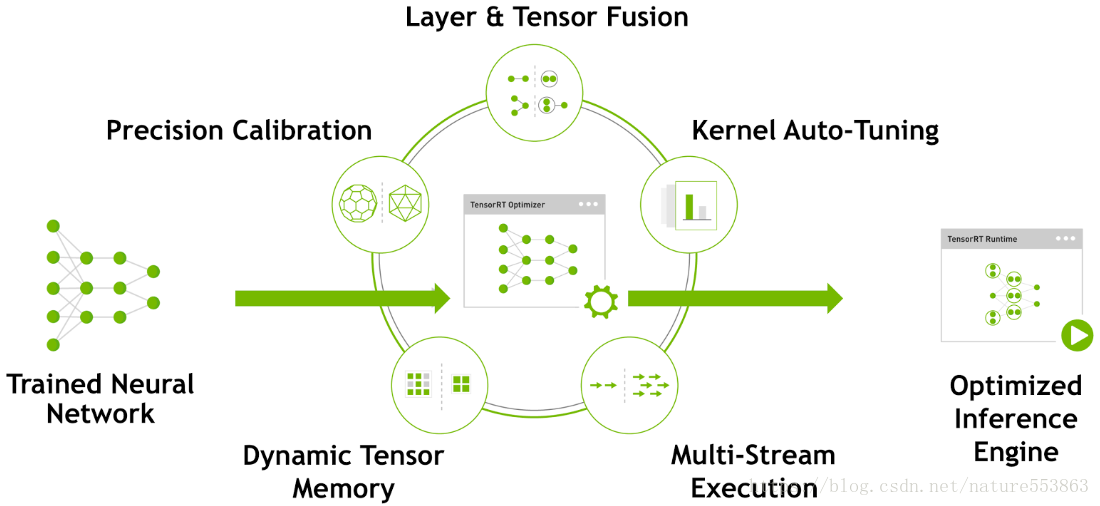
TensorRT能够优化重构由不同深度学习框架训练的深度学习模型:
- 对于Caffe与TensorFlow训练的模型,若包含的操作都是TensorRT支持的,则可以直接由TensorRT优化重构;
- 对于MXnet, PyTorch或其他框架训练的模型,若包含的操作都是TensorRT支持的,可以采用TensorRT API重建网络结构,并间接优化重构;
- 若训练的网络模型包含TensorRT不支持的操作:
- TensorFlow模型可通过tf.contrib.tensorrt转换,其中不支持的操作会保留为TensorFlow计算节点;
- 不支持的操作可通过Plugin API实现自定义并添加进TensorRT计算图;
- 将深度网络划分为两个部分,一部分包含的操作都是TensorRT支持的,可以转换为TensorRT计算图。另一部则采用其他框架实现,如MXnet或PyTorch;
- TensorRT的int8量化需要校准(calibration)数据集,一般至少包含1000个样本(反映真实应用场景),且要求GPU的计算功能集sm >= 6.1;
在TitanX (Pascal)平台上,TensorRT对大型分类网络的优化加速效果如下:
| Network | Precision | Framework / GPU: TitanX (P) | Avg. Time (Batch=8, unit: ms) | Top1 Val. Acc. (ImageNet-1k) |
| Resnet50 | fp32 | TensorFlow | 24.1 | 0.7374 |
| Resnet50 | fp32 | MXnet | 15.7 | 0.7374 |
| Resnet50 | fp32 | TRT4.0.1 | 12.1 | 0.7374 |
| Resnet50 | int8 | TRT4.0.1 | 6 | 0.7226 |
| Resnet101 | fp32 | TensorFlow | 36.7 | 0.7612 |
| Resnet101 | fp32 | MXnet | 25.8 | 0.7612 |
| Resnet101 | fp32 | TRT4.0.1 | 19.3 | 0.7612 |
| Resnet101 | int8 | TRT4.0.1 | 9 | 0.7574 |
3. 网络剪枝
深度学习模型因其稀疏性,可以被裁剪为结构精简的网络模型,具体包括结构性剪枝与非结构性剪枝:
- 非结构剪枝:通常是连接级、细粒度的剪枝方法,精度相对较高,但依赖于特定算法库或硬件平台的支持,如Deep Compression [5], Sparse-Winograd [6] 算法等;
- 结构剪枝:是filter级或layer级、粗粒度的剪枝方法,精度相对较低,但剪枝策略更为有效,不需要特定算法库或硬件平台的支持,能够直接在成熟深度学习框架上运行。如局部方式的、通过layer by layer方式的、最小化输出FM重建误差的Channel pruning [7];全局方式的、通过训练期间对BN层Gamma系数施加L1正则约束的Network Slimming [8];全局方式的、按Taylor准则对Filter作重要性排序的Neuron Pruning [9];全局方式的、可动态重新更新pruned filters参数的剪枝方法 [10];
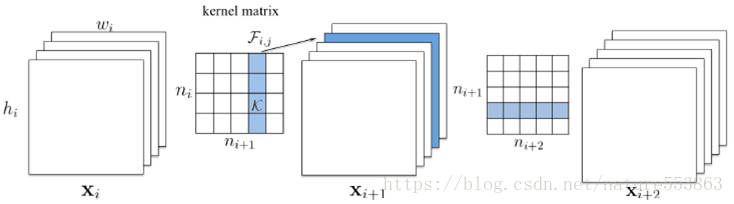
结构性剪枝的规整操作如下图所示:
4. 模型量化
模型量化是指权重或激活输出可以被聚类到一些离散、低精度的数值点上,通常依赖于特定算法库或硬件平台的支持:
- 二值化网络:XNORnet [11], ABCnet with Multiple Binary Bases [12], Bin-net with High-Order Residual Quantization [13];
- 三值化网络:Trained Ternary Quantization [14];
- W1-A8 或 W2-A8量化: Learning Symmetric Quantization [15];
- INT8量化:TensorFlow-lite [16], TensorRT [17];
- 其他(非线性):Intel INQ [18], log-net, CNNPack [19] 等;
模型压缩、优化加速算法可以集成使用,进而可获得更为极致的压缩比与加速比。例如结合Network Slimming与TensorRT,在TitanX Pascal平台上,Resnet101在压缩比为2倍时可获得约1.74倍的加速比(Batch=8, 26.1ms -> 15ms)。

References
[1] https://arxiv.org/abs/1801.02108, Github: https://github.com/uber/sbnet
[2] https://basicmi.github.io/Deep-Learning-Processor-List/
[3] https://devblogs.nvidia.com/tensorrt-3-faster-tensorflow-inference/
[4] https://devblogs.nvidia.com/int8-inference-autonomous-vehicles-tensorrt/
[5] https://arxiv.org/abs/1510.00149
[6] https://arxiv.org/abs/1802.06367, https://ai.intel.com/winograd-2/, Github: https://github.com/xingyul/Sparse-Winograd-CNN
[7] https://arxiv.org/abs/1707.06168, Github: https://github.com/yihui-he/channel-pruning
[8] https://arxiv.org/abs/1708.06519, Github: https://github.com/foolwood/pytorch-slimming
[9] https://arxiv.org/abs/1611.06440, Github: https://github.com/jacobgil/pytorch-pruning
[10] http://xuanyidong.com/publication/ijcai-2018-sfp/
[11] https://arxiv.org/abs/1603.05279, Github: https://github.com/ayush29feb/Sketch-A-XNORNet
[12] https://arxiv.org/abs/1711.11294, Github: https://github.com/layog/Accurate-Binary-Convolution-Network
[13] https://arxiv.org/abs/1708.08687
[14] https://arxiv.org/abs/1612.01064, Github: https://github.com/czhu95/ternarynet
[15] http://phwl.org/papers/syq_cvpr18.pdf, Github: https://github.com/julianfaraone/SYQ
[16] https://arxiv.org/abs/1712.05877
[17] http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf