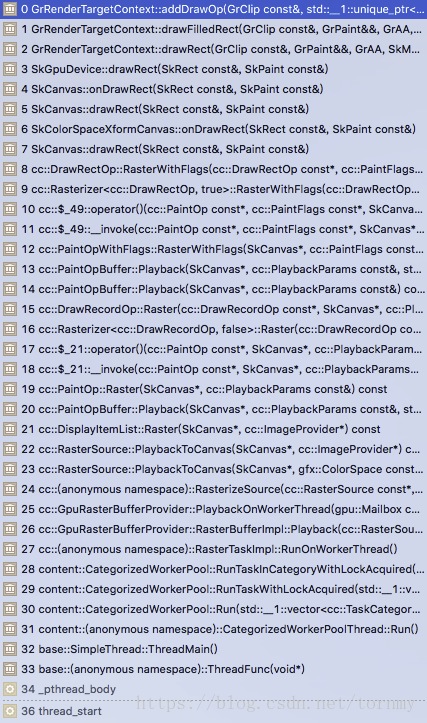
站在老罗的肩膀上:https://blog.csdn.net/luoshengyang/article/details/51348829
CC Layer Tree 的绘制指令存储在displayitem的paint_op_buffer_中,要将绘制指令打包送入GPU,如下:
开始准备光栅化的条件
bool SchedulerStateMachine::ShouldPrepareTiles() const {
// In full-pipeline mode, we need to prepare tiles ASAP to ensure that we
// don't get stuck.
if (settings_.wait_for_all_pipeline_stages_before_draw)
return needs_prepare_tiles_;
// Do not prepare tiles if we've already done so in commit or impl side
// invalidation.
if (did_prepare_tiles_)
return false;
// Limiting to once per-frame is not enough, since we only want to prepare
// tiles _after_ draws.
if (begin_impl_frame_state_ != BeginImplFrameState::INSIDE_DEADLINE)
return false;
return needs_prepare_tiles_;
}开始准备光栅化:
void ProxyImpl::ScheduledActionPrepareTiles() {
host_impl_->PrepareTiles();
}
bool LayerTreeHostImpl::PrepareTiles() {
if (!tile_priorities_dirty_)
return false;
client_->WillPrepareTiles();
bool did_prepare_tiles = tile_manager_.PrepareTiles(global_tile_state_);
if (did_prepare_tiles)
tile_priorities_dirty_ = false;
client_->DidPrepareTiles();
return did_prepare_tiles;
}
bool TileManager::PrepareTiles(
const GlobalStateThatImpactsTilePriority& state) {
++prepare_tiles_count_;
...
signals_ = Signals();
global_state_ = state;
...
// update completed tasks, useful in updating Task Graph in later scheduling
if (!did_check_for_completed_tasks_since_last_schedule_tasks_) {
tile_task_manager_->CheckForCompletedTasks();
did_check_for_completed_tasks_since_last_schedule_tasks_ = true;
}
...
PrioritizedWorkToSchedule prioritized_work = AssignGpuMemoryToTiles();
client_->SetIsLikelyToRequireADraw(
!prioritized_work.tiles_to_raster.empty() &&
prioritized_work.tiles_to_raster.front().tile()->required_for_draw());
// Schedule tile tasks.
ScheduleTasks(std::move(prioritized_work));
}TileManager类的成员函数ManageTiles主要是做两件事情:
1. 调用成员函数AssignGpuMemoryToTiles根据优先级对网页中的分块进行排序,根据上述排序以及GPU内存策略获取当前需要执行光栅化操作的分块。
2. 调用成员函数ScheduleTasks对第2步获得的分块执行光栅化操作。
TileManager::PrioritizedWorkToSchedule TileManager::AssignGpuMemoryToTiles() {
...
// build priorities and sort for tiles
std::unique_ptr<RasterTilePriorityQueue> raster_priority_queue(
client_->BuildRasterQueue(global_state_.tree_priority,
RasterTilePriorityQueue::Type::ALL));
std::unique_ptr<EvictionTilePriorityQueue> eviction_priority_queue;
PrioritizedWorkToSchedule work_to_schedule;
for (; !raster_priority_queue->IsEmpty(); raster_priority_queue->Pop()) {
const PrioritizedTile& prioritized_tile = raster_priority_queue->Top();
Tile* tile = prioritized_tile.tile();
TilePriority priority = prioritized_tile.priority();
bool tile_is_needed_now = priority.priority_bin == TilePriority::NOW;
if (!tile->is_solid_color_analysis_performed() &&
tile->use_picture_analysis() && kUseColorEstimator) {
tile->set_solid_color_analysis_performed(true);
SkColor color = SK_ColorTRANSPARENT;
bool is_solid_color =
prioritized_tile.raster_source()->PerformSolidColorAnalysis(
tile->enclosing_layer_rect(), &color);
if (is_solid_color) {
tile->draw_info().set_solid_color(color);
client_->NotifyTileStateChanged(tile);
continue;
}
}
// Prepaint tiles that are far away are only processed for images.
if (tile->is_prepaint() && prioritized_tile.is_process_for_images_only()) {
work_to_schedule.tiles_to_process_for_images.push_back(prioritized_tile);
continue;
}
if (!tile->draw_info().NeedsRaster()) {
AddCheckeredImagesToDecodeQueue(
prioritized_tile, raster_color_space.color_space,
CheckerImageTracker::DecodeType::kRaster,
&work_to_schedule.checker_image_decode_queue);
continue;
}
// We won't be able to schedule this tile, so break out early.
if (work_to_schedule.tiles_to_raster.size() >=
scheduled_raster_task_limit_) {
all_tiles_that_need_to_be_rasterized_are_scheduled_ = false;
break;
}
MemoryUsage memory_required_by_tile_to_be_scheduled;
if (!tile->raster_task_.get()) {
memory_required_by_tile_to_be_scheduled = MemoryUsage::FromConfig(
tile->desired_texture_size(), DetermineResourceFormat(tile));
}
// This is the memory limit that will be used by this tile. Depending on
// the tile priority, it will be one of hard_memory_limit or
// soft_memory_limit.
MemoryUsage& tile_memory_limit =
tile_is_needed_now ? hard_memory_limit : soft_memory_limit;
const MemoryUsage& scheduled_tile_memory_limit =
tile_memory_limit - memory_required_by_tile_to_be_scheduled;
eviction_priority_queue =
FreeTileResourcesWithLowerPriorityUntilUsageIsWithinLimit(
std::move(eviction_priority_queue), scheduled_tile_memory_limit,
priority, &memory_usage);
bool memory_usage_is_within_limit =
!memory_usage.Exceeds(scheduled_tile_memory_limit);
// If we couldn't fit the tile into our current memory limit, then we're
// done.
if (!memory_usage_is_within_limit) {
if (tile_is_needed_now)
had_enough_memory_to_schedule_tiles_needed_now = false;
all_tiles_that_need_to_be_rasterized_are_scheduled_ = false;
break;
}
if (tile->HasRasterTask()) {
if (tile->raster_task_scheduled_with_checker_images() &&
prioritized_tile.should_decode_checkered_images_for_tile()) {
AddCheckeredImagesToDecodeQueue(
prioritized_tile, raster_color_space.color_space,
CheckerImageTracker::DecodeType::kRaster,
&work_to_schedule.checker_image_decode_queue);
}
} else {
// Creating the raster task here will acquire resources, but
// this resource usage has already been accounted for above.
auto raster_task = CreateRasterTask(
prioritized_tile, client_->GetRasterColorSpace(), &work_to_schedule);
if (!raster_task) {
continue;
}
tile->raster_task_ = std::move(raster_task);
}
tile->scheduled_priority_ = schedule_priority++;
memory_usage += memory_required_by_tile_to_be_scheduled;
work_to_schedule.tiles_to_raster.push_back(prioritized_tile);
}
eviction_priority_queue = FreeTileResourcesUntilUsageIsWithinLimit(
std::move(eviction_priority_queue), hard_memory_limit, &memory_usage);
if (!had_enough_memory_to_schedule_tiles_needed_now &&
num_of_tiles_with_checker_images_ > 0) {
for (; !raster_priority_queue->IsEmpty(); raster_priority_queue->Pop()) {
const PrioritizedTile& prioritized_tile = raster_priority_queue->Top();
if (prioritized_tile.priority().priority_bin > TilePriority::NOW)
break;
if (!prioritized_tile.should_decode_checkered_images_for_tile())
continue;
Tile* tile = prioritized_tile.tile();
if (tile->draw_info().is_checker_imaged() ||
tile->raster_task_scheduled_with_checker_images()) {
AddCheckeredImagesToDecodeQueue(
prioritized_tile, raster_color_space.color_space,
CheckerImageTracker::DecodeType::kRaster,
&work_to_schedule.checker_image_decode_queue);
}
}
}
...
}首先计算剩余可用的光栅化内存字节数以及光栅化资源个数。CC模块限制了光栅化内存字节数上限和光栅化资源个数(Num Resources Limit)。其中,光栅化内存字节数又分为软限制(Soft Memory Limit)和硬限制(Hard Memory Limit)两种,它们的作用如图2所示:
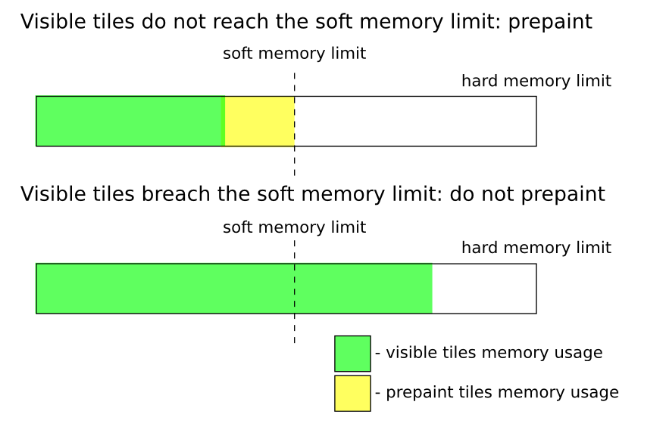
图2 Soft Memory Limit和Hard Memory Limit
当前可见的分块,也就是处于NOW_BIN中的分块,它们的可用的内存上限是Hard Memory Limit,其余的分块可用的内存上限是Soft Memory Limit。通过这种策略一方面可以最大程度保证可见分块都可以得到光栅化,另一方面又可以在可见分块占用内存不多的情况下,对其它的分块提前进行光栅化,这样等到它们变为可见时,就可以马上显示出来。
Soft Memory Limit、Hard Memory Limit和Num Resources Limit值分别保存在global_state_.soft_memory_limit_in_bytes、global_state_.hard_memory_limit_in_bytes和global_state_.num_resources_limit。其中,global_state_.num_resources_limit的值设置为10000000(没找到,不确定)。
当网页使用硬件加速方式渲染时,global_state_.hard_memory_limit_in_bytes的值可以通过启动选项force-gpu-mem-available-mb指定,但是会被限制在16M到256M之间。当网页使用软件方式渲染时,global_state_.hard_memory_limit_in_bytes的值会被设置为128M。
在当前的实现中,global_state_.soft_memory_limit_in_bytes的值与global_state_.hard_memory_limit_in_bytes是相等的。
目前分块正在使用的光栅化内存字节数可以通过调用TileManager类的成员变量resource_pool_指向的一个ResourcePool::resource_count获得。另外,也可以获得当前正在使用的光栅化资源个数。
有了上述数据之后,本来就可以计算出剩余可用的光栅化内存字节数和光栅化资源个数。例如,剩余可用的Soft类型的光栅化内存字节数就等于(global_state_.soft_memory_limit_in_bytes - resource_pool_->memory_usage_bytes())。不过我们看到,按照前面的方式计算出来的字节数,再加上TileManager类的成员变量bytes_releasable_的值,才是接下来使用的剩余可用的Soft类型的光栅化内存字节数soft_bytes_left。剩余可用的Hard类型的光栅化内存字节数hard_bytes_left和光栅化资源个数resources_left的计算过程也是类似的。
TileManager类的成员变量bytes_releasable_和resources_releasable_记录了当前可回收但是还没有回收的分块光栅化内存字节数和光栅化资源个数。注意,这里说的可回收资源,是指已经光栅化完成的分块占用的资源。当一个已经光栅化完成的分块不再需要时,它占用的资源就会被回收。将TileManager类的成员变量bytes_releasable_和resources_releasable_的值计入到剩余可用的光栅化内存字节数soft_bytes_left、hard_bytes_left和光栅化资源个数resources_left中去是冗余的。不过,接下来要遍历每一个分块时,会考虑剔除这些值。
然后计算所有tiles(所有tiling下的所有tiles)的priorities,调用栈如下
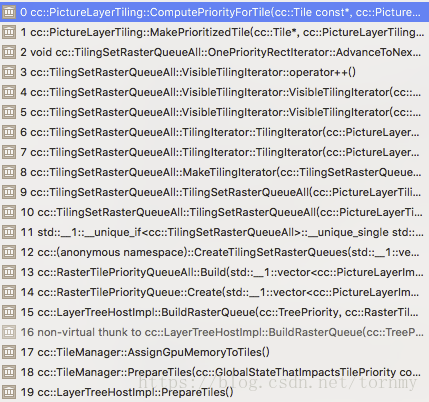
具体计算函数:PictureLayerTiling::ComputePriorityForTile
TilePriority PictureLayerTiling::ComputePriorityForTile(
const Tile* tile,
PriorityRectType priority_rect_type) const {
TilePriority::PriorityBin priority_bin = client_->HasValidTilePriorities()
? TilePriority::NOW
: TilePriority::EVENTUALLY;
switch (priority_rect_type) {
case VISIBLE_RECT:
case PENDING_VISIBLE_RECT:
return TilePriority(resolution_, priority_bin, 0);
case SKEWPORT_RECT:
case SOON_BORDER_RECT:
if (priority_bin < TilePriority::SOON)
priority_bin = TilePriority::SOON;
break;
case EVENTUALLY_RECT:
priority_bin = TilePriority::EVENTUALLY;
break;
}
gfx::Rect tile_bounds =
tiling_data_.TileBounds(tile->tiling_i_index(), tile->tiling_j_index());
DCHECK_GT(current_content_to_screen_scale_, 0.f);
float distance_to_visible =
current_content_to_screen_scale_ *
current_visible_rect_.ManhattanInternalDistance(tile_bounds);
return TilePriority(resolution_, priority_bin, distance_to_visible);
}然后构使用std::make_heap构建优先队列
void CreateTilingSetRasterQueues(
const std::vector<PictureLayerImpl*>& layers,
TreePriority tree_priority,
std::vector<std::unique_ptr<TilingSetRasterQueueAll>>* queues) {
for (auto* layer : layers) {
if (!layer->HasValidTilePriorities())
continue;
PictureLayerTilingSet* tiling_set = layer->picture_layer_tiling_set();
bool prioritize_low_res = tree_priority == SMOOTHNESS_TAKES_PRIORITY;
std::unique_ptr<TilingSetRasterQueueAll> tiling_set_queue =
std::make_unique<TilingSetRasterQueueAll>(
tiling_set, prioritize_low_res,
layer->contributes_to_drawn_render_surface());
// Queues will only contain non empty tiling sets.
if (!tiling_set_queue->IsEmpty())
queues->push_back(std::move(tiling_set_queue));
}
std::make_heap(queues->begin(), queues->end(),
RasterOrderComparator(tree_priority));
}
TilingSetRasterQueueAll::TilingSetRasterQueueAll(
PictureLayerTilingSet* tiling_set,
bool prioritize_low_res,
bool is_drawing_layer)
: tiling_set_(tiling_set),
current_stage_(0),
is_drawing_layer_(is_drawing_layer) {
DCHECK(tiling_set_);
// Early out if the tiling set has no tilings.
if (!tiling_set_->num_tilings())
return;
const PictureLayerTilingClient* client = tiling_set->client();
WhichTree tree = tiling_set->tree();
// Find high and low res tilings and initialize the iterators.
PictureLayerTiling* high_res_tiling = nullptr;
PictureLayerTiling* low_res_tiling = nullptr;
PictureLayerTiling* active_non_ideal_pending_high_res_tiling = nullptr;
for (size_t i = 0; i < tiling_set_->num_tilings(); ++i) {
PictureLayerTiling* tiling = tiling_set_->tiling_at(i);
if (tiling->resolution() == HIGH_RESOLUTION)
high_res_tiling = tiling;
if (prioritize_low_res && tiling->resolution() == LOW_RESOLUTION)
low_res_tiling = tiling;
if (tree == ACTIVE_TREE && tiling->resolution() != HIGH_RESOLUTION) {
const PictureLayerTiling* twin =
client->GetPendingOrActiveTwinTiling(tiling);
if (twin && twin->resolution() == HIGH_RESOLUTION)
active_non_ideal_pending_high_res_tiling = tiling;
}
}然后遍历所创建的raster_priority_queue按优先级计算所有的tiles所需要的memory,然后创建raster_task,并转移到work_to_schedule.tiles_to_raster中(其中有部分tiles被添加到decode queue,不太清楚是干什么到),等待下一步分发,进行光栅化。
TileManager::PrioritizedWorkToSchedule TileManager::AssignGpuMemoryToTiles() {
...
for (; !raster_priority_queue->IsEmpty(); raster_priority_queue->Pop()) {
const PrioritizedTile& prioritized_tile = raster_priority_queue->Top();
Tile* tile = prioritized_tile.tile();
TilePriority priority = prioritized_tile.priority();
...
if (tile->HasRasterTask()) {
if (tile->raster_task_scheduled_with_checker_images() &&
prioritized_tile.should_decode_checkered_images_for_tile()) {
AddCheckeredImagesToDecodeQueue(
prioritized_tile, raster_color_space.color_space,
CheckerImageTracker::DecodeType::kRaster,
&work_to_schedule.checker_image_decode_queue);
}
} else {
// Creating the raster task here will acquire resources, but
// this resource usage has already been accounted for above.
auto raster_task = CreateRasterTask(
prioritized_tile, client_->GetRasterColorSpace(), &work_to_schedule);
if (!raster_task) {
continue;
}
tile->raster_task_ = std::move(raster_task);
}
tile->scheduled_priority_ = schedule_priority++;
memory_usage += memory_required_by_tile_to_be_scheduled;
work_to_schedule.tiles_to_raster.push_back(prioritized_tile);
}
}其中通过eviction_priority_queue会尽可能释放LOW_PRIORITY的tiles的resource,保证TilePriority::NOW的tiles能分配到光栅化所需要的resource
eviction_priority_queue =
FreeTileResourcesWithLowerPriorityUntilUsageIsWithinLimit(
std::move(eviction_priority_queue), scheduled_tile_memory_limit,
priority, &memory_usage);
eviction_priority_queue = FreeTileResourcesUntilUsageIsWithinLimit(
std::move(eviction_priority_queue), hard_memory_limit, &memory_usage);TileManager::CreateRasterTask的实现如下所示
scoped_refptr<TileTask> TileManager::CreateRasterTask(
const PrioritizedTile& prioritized_tile,
const RasterColorSpace& raster_color_space,
PrioritizedWorkToSchedule* work_to_schedule) {
TRACE_EVENT0(TRACE_DISABLED_BY_DEFAULT("cc.debug"),
"TileManager::CreateRasterTask");
Tile* tile = prioritized_tile.tile();
TRACE_EVENT1(TRACE_DISABLED_BY_DEFAULT("cc.debug"),
"TileManager::CreateRasterTask", "Tile", tile->id());
// Get the resource.
ResourcePool::InUsePoolResource resource;
uint64_t resource_content_id = 0;
gfx::Rect invalidated_rect = tile->invalidated_content_rect();
if (UsePartialRaster() && tile->invalidated_id()) {
resource = resource_pool_->TryAcquireResourceForPartialRaster(
tile->id(), tile->invalidated_content_rect(), tile->invalidated_id(),
&invalidated_rect);
}
bool partial_tile_decode = false;
if (resource) {
resource_content_id = tile->invalidated_id();
DCHECK_EQ(DetermineResourceFormat(tile), resource.format());
partial_tile_decode = true;
} else {
resource = resource_pool_->AcquireResource(tile->desired_texture_size(),
DetermineResourceFormat(tile),
raster_color_space.color_space);
DCHECK(resource);
}
// For LOW_RESOLUTION tiles, we don't draw or predecode images.
RasterSource::PlaybackSettings playback_settings;
const bool skip_images =
prioritized_tile.priority().resolution == LOW_RESOLUTION;
playback_settings.use_lcd_text = tile->can_use_lcd_text();
// Create and queue all image decode tasks that this tile depends on. Note
// that we need to store the images for decode tasks in
// |scheduled_draw_images_| since the tile might have been destroyed by the
// time the raster task finishes.
TileTask::Vector decode_tasks;
std::vector<DrawImage>& sync_decoded_images =
scheduled_draw_images_[tile->id()];
sync_decoded_images.clear();
std::vector<PaintImage> checkered_images;
base::flat_map<PaintImage::Id, size_t> image_id_to_current_frame_index;
if (!skip_images) {
PartitionImagesForCheckering(
prioritized_tile, raster_color_space.color_space, &sync_decoded_images,
&checkered_images, partial_tile_decode ? &invalidated_rect : nullptr,
&image_id_to_current_frame_index);
}
// Get the tasks for the required images.
ImageDecodeCache::TracingInfo tracing_info(
prepare_tiles_count_, prioritized_tile.priority().priority_bin,
ImageDecodeCache::TaskType::kInRaster);
bool has_at_raster_images = false;
image_controller_.GetTasksForImagesAndRef(
&sync_decoded_images, &decode_tasks, &has_at_raster_images, tracing_info);
const bool has_checker_images = !checkered_images.empty();
tile->set_raster_task_scheduled_with_checker_images(has_checker_images);
if (has_checker_images)
num_of_tiles_with_checker_images_++;
// Don't allow at-raster prepaint tiles, because they could be very slow
// and block high-priority tasks.
if (has_at_raster_images && tile->is_prepaint()) {
work_to_schedule->extra_prepaint_images.insert(
work_to_schedule->extra_prepaint_images.end(),
sync_decoded_images.begin(), sync_decoded_images.end());
// This will unref the images, but ScheduleTasks will schedule them
// right away anyway.
OnRasterTaskCompleted(tile->id(), std::move(resource),
true /* was_canceled */);
return nullptr;
}
PaintImageIdFlatSet images_to_skip;
for (const auto& image : checkered_images) {
DCHECK(!image.ShouldAnimate());
images_to_skip.insert(image.stable_id());
// This can be the case for tiles on the active tree that will be replaced
// or are occluded on the pending tree. While we still need to continue
// skipping images for these tiles, we don't need to decode them since
// they will not be required on the next active tree.
if (prioritized_tile.should_decode_checkered_images_for_tile()) {
work_to_schedule->checker_image_decode_queue.emplace_back(
image, CheckerImageTracker::DecodeType::kRaster);
}
}
std::unique_ptr<RasterBuffer> raster_buffer =
raster_buffer_provider_->AcquireBufferForRaster(
resource, resource_content_id, tile->invalidated_id());
base::Optional<PlaybackImageProvider::Settings> settings;
if (!skip_images) {
settings.emplace();
settings->images_to_skip = std::move(images_to_skip);
settings->image_to_current_frame_index =
std::move(image_id_to_current_frame_index);
}
PlaybackImageProvider image_provider(image_controller_.cache(),
raster_color_space.color_space,
std::move(settings));
playback_settings.raster_color_space = raster_color_space;
return base::MakeRefCounted<RasterTaskImpl>(
this, tile, std::move(resource), prioritized_tile.raster_source(),
playback_settings, prioritized_tile.priority().resolution,
invalidated_rect, prepare_tiles_count_, std::move(raster_buffer),
&decode_tasks, use_gpu_rasterization_, std::move(image_provider),
active_url_);
}TileManager类的成员函数CreateRasterTask首先是调用成员变量resource_pool_描述的一个ResourcePool对象的成员函数AcquireResource为参数tile描述的分块创建纹理资源。
TileManager类的成员函数CreateRasterTask接下来又检查这个分块是否依赖了其它的图片资源。如果是的话,就会调用TileManager类的成员函数CreateImageDecodeTask为每一个依赖的图片都创建一个解码任务。每一个解码任务都是通过一个ImageDecodeTaskImpl对象描述的。通过ImageController::GetTasksForImagesAndRef完成。
TileManager类的成员函数CreateRasterTask最后将前面创建的纹理资源、参数tile描述的分块的信息,以及前面创建的图片解码任务,封装在一个RasterTaskImpl对象中,并且返回给调用者。
这个RasterTaskImpl对象描述的就是一个光栅化任务,它负责对参数tile描述的分块进行光栅化。光栅化的结果就保存在前面创建的纹理资源中。注意,如果参数tile描述的分块依赖了其它的图片资源,那么上述光栅化任务就在会被依赖的图片的解码任务执行完成之后才会执行。
这个RasterTaskImpl对象描述的光栅化任务还绑定了TileManager类的成员函数OnRasterTaskCompleted,表示当光栅化任务执行完成后,调用TileManager类的成员函数OnRasterTaskCompleted进行后续处理。
接下来我们分析它的成员函数ScheduleTasks的实现,以便了解分块的光栅化过程,如下所示:
void TileManager::ScheduleTasks(PrioritizedWorkToSchedule work_to_schedule) {
const std::vector<PrioritizedTile>& tiles_that_need_to_be_rasterized =
work_to_schedule.tiles_to_raster;
...
size_t priority = kTileTaskPriorityBase;
...
scoped_refptr<TileTask> required_for_activation_done_task =
CreateTaskSetFinishedTask(
&TileManager::DidFinishRunningTileTasksRequiredForActivation);
scoped_refptr<TileTask> required_for_draw_done_task =
CreateTaskSetFinishedTask(
&TileManager::DidFinishRunningTileTasksRequiredForDraw);
scoped_refptr<TileTask> all_done_task =
CreateTaskSetFinishedTask(&TileManager::DidFinishRunningAllTileTasks);
// Build a new task queue containing all task currently needed. Tasks
// are added in order of priority, highest priority task first.
for (auto& prioritized_tile : tiles_that_need_to_be_rasterized) {
Tile* tile = prioritized_tile.tile();
TileTask* task = tile->raster_task_.get();
if (tile->required_for_activation()) {
required_for_activate_count++;
graph_.edges.emplace_back(task, required_for_activation_done_task.get());
}
if (tile->required_for_draw()) {
required_for_draw_count++;
graph_.edges.emplace_back(task, required_for_draw_done_task.get());
}
all_count++;
graph_.edges.emplace_back(task, all_done_task.get());
// A tile should use a foreground task cateogry if it is either blocking
// future compositing (required for draw or required for activation), or if
// it has a priority bin of NOW for another reason (low resolution tiles).
bool use_foreground_category =
tile->required_for_draw() || tile->required_for_activation() ||
prioritized_tile.priority().priority_bin == TilePriority::NOW;
InsertNodesForRasterTask(&graph_, task, task->dependencies(), priority++,
use_foreground_category);
}
const std::vector<PrioritizedTile>& tiles_to_process_for_images =
work_to_schedule.tiles_to_process_for_images;
std::vector<DrawImage> new_locked_images;
for (const PrioritizedTile& prioritized_tile : tiles_to_process_for_images) {
std::vector<DrawImage> sync_decoded_images;
std::vector<PaintImage> checkered_images;
PartitionImagesForCheckering(prioritized_tile, raster_color_space,
&sync_decoded_images, &checkered_images,
nullptr);
// Add the sync decoded images to |new_locked_images| so they can be added
// to the task graph.
new_locked_images.insert(
new_locked_images.end(),
std::make_move_iterator(sync_decoded_images.begin()),
std::make_move_iterator(sync_decoded_images.end()));
// For checkered-images, send them to the decode service.
for (auto& image : checkered_images) {
work_to_schedule.checker_image_decode_queue.emplace_back(
std::move(image), CheckerImageTracker::DecodeType::kPreDecode);
}
}
new_locked_images.insert(new_locked_images.end(),
work_to_schedule.extra_prepaint_images.begin(),
work_to_schedule.extra_prepaint_images.end());
// TODO(vmpstr): SOON is misleading here, but these images can come from
// several diffent tiles. Rethink what we actually want to trace here. Note
// that I'm using SOON, since it can't be NOW (these are prepaint).
ImageDecodeCache::TracingInfo tracing_info(
prepare_tiles_count_, TilePriority::SOON,
ImageDecodeCache::TaskType::kInRaster);
std::vector<scoped_refptr<TileTask>> new_locked_image_tasks =
image_controller_.SetPredecodeImages(std::move(new_locked_images),
tracing_info);
work_to_schedule.extra_prepaint_images.clear();
for (auto& task : new_locked_image_tasks) {
auto decode_it = std::find_if(graph_.nodes.begin(), graph_.nodes.end(),
[&task](const TaskGraph::Node& node) {
return node.task == task.get();
});
// If this task is already in the graph, then we don't have to insert it.
if (decode_it != graph_.nodes.end())
continue;
InsertNodeForDecodeTask(&graph_, task.get(), false, priority++);
all_count++;
graph_.edges.emplace_back(task.get(), all_done_task.get());
}
// The old locked images tasks have to stay around until past the
// ScheduleTasks call below, so we do a swap instead of a move.
// TODO(crbug.com/647402): Have the tile_task_manager keep a ref on the tasks,
// since it makes it awkward for the callers to keep refs on tasks that only
// exist within the task graph runner.
locked_image_tasks_.swap(new_locked_image_tasks);
// We must reduce the amount of unused resources before calling
// ScheduleTasks to prevent usage from rising above limits.
resource_pool_->ReduceResourceUsage();
image_controller_.ReduceMemoryUsage();
// Insert nodes for our task completion tasks. We enqueue these using
// NONCONCURRENT_FOREGROUND category this is the highest prioirty category and
// we'd like to run these tasks as soon as possible.
InsertNodeForTask(&graph_, required_for_activation_done_task.get(),
TASK_CATEGORY_NONCONCURRENT_FOREGROUND,
kRequiredForActivationDoneTaskPriority,
required_for_activate_count);
InsertNodeForTask(&graph_, required_for_draw_done_task.get(),
TASK_CATEGORY_NONCONCURRENT_FOREGROUND,
kRequiredForDrawDoneTaskPriority, required_for_draw_count);
InsertNodeForTask(&graph_, all_done_task.get(),
TASK_CATEGORY_NONCONCURRENT_FOREGROUND,
kAllDoneTaskPriority, all_count);
// Schedule running of |raster_queue_|. This replaces any previously
// scheduled tasks and effectively cancels all tasks not present
// in |raster_queue_|.
tile_task_manager_->ScheduleTasks(&graph_);
// Schedule running of the checker-image decode queue. This replaces the
// previously scheduled queue and effectively cancels image decodes from the
// previous queue, if not already started.
checker_image_tracker_.ScheduleImageDecodeQueue(
std::move(work_to_schedule.checker_image_decode_queue));
did_check_for_completed_tasks_since_last_schedule_tasks_ = false;
TRACE_EVENT_ASYNC_STEP_INTO1("cc", "ScheduledTasks", this, "running", "state",
ScheduledTasksStateAsValue());
}从前面的调用过程可以知道,参数queue描述的队列保存一系列的光栅化任务,并且这些光栅化是按照优先级从高到低的顺序排序的。由graph_指向的一个TaskGraph对象描述。

创建完graph_后就根据优先级run那些ready_to_active的task,同时更新garph_。
void TaskGraphWorkQueue::ScheduleTasks(NamespaceToken token, TaskGraph* graph) {
TaskNamespace& task_namespace = namespaces_[token];
// First adjust number of dependencies to reflect completed tasks.
for (const scoped_refptr<Task>& task : task_namespace.completed_tasks) {
for (DependentIterator node_it(graph, task.get()); node_it; ++node_it) {
TaskGraph::Node& node = *node_it;
DCHECK_LT(0u, node.dependencies);
node.dependencies--;
}
}
// Build new "ready to run" queue and remove nodes from old graph.
for (auto& ready_to_run_tasks_it : task_namespace.ready_to_run_tasks) {
ready_to_run_tasks_it.second.clear();
}
for (const TaskGraph::Node& node : graph->nodes) {
// Remove any old nodes that are associated with this task. The result is
// that the old graph is left with all nodes not present in this graph,
// which we use below to determine what tasks need to be canceled.
TaskGraph::Node::Vector::iterator old_it = std::find_if(
task_namespace.graph.nodes.begin(), task_namespace.graph.nodes.end(),
[&node](const TaskGraph::Node& other) {
return node.task == other.task;
});
if (old_it != task_namespace.graph.nodes.end()) {
std::swap(*old_it, task_namespace.graph.nodes.back());
// If old task is scheduled to run again and not yet started running,
// reset its state to initial state as it has to be inserted in new
// |ready_to_run_tasks|, where it gets scheduled.
if (node.task->state().IsScheduled())
node.task->state().Reset();
task_namespace.graph.nodes.pop_back();
}
// Task is not ready to run if dependencies are not yet satisfied.
if (node.dependencies)
continue;
// Skip if already finished running task.
if (node.task->state().IsFinished())
continue;
// Skip if already running.
if (std::any_of(task_namespace.running_tasks.begin(),
task_namespace.running_tasks.end(),
[&node](const CategorizedTask& task) {
return task.second == node.task;
}))
continue;
node.task->state().DidSchedule();
task_namespace.ready_to_run_tasks[node.category].emplace_back(
node.task, &task_namespace, node.category, node.priority);
}
// Rearrange the elements in each vector within |ready_to_run_tasks| in such a
// way that they form a heap.
for (auto& it : task_namespace.ready_to_run_tasks) {
auto& ready_to_run_tasks = it.second;
std::make_heap(ready_to_run_tasks.begin(), ready_to_run_tasks.end(),
CompareTaskPriority);
}
// Swap task graph.
task_namespace.graph.Swap(graph);
// Determine what tasks in old graph need to be canceled.
for (TaskGraph::Node::Vector::iterator it = graph->nodes.begin();
it != graph->nodes.end(); ++it) {
TaskGraph::Node& node = *it;
// Skip if already finished running task.
if (node.task->state().IsFinished())
continue;
// Skip if already running.
if (std::any_of(task_namespace.running_tasks.begin(),
task_namespace.running_tasks.end(),
[&node](const CategorizedTask& task) {
return task.second == node.task;
}))
continue;
DCHECK(std::find(task_namespace.completed_tasks.begin(),
task_namespace.completed_tasks.end(),
node.task) == task_namespace.completed_tasks.end());
node.task->state().DidCancel();
task_namespace.completed_tasks.push_back(node.task);
}
// Build new "ready to run" task namespaces queue.
for (auto& ready_to_run_namespaces_it : ready_to_run_namespaces_) {
ready_to_run_namespaces_it.second.clear();
}
for (auto& namespace_it : namespaces_) {
auto& task_namespace = namespace_it.second;
for (auto& ready_to_run_tasks_it : task_namespace.ready_to_run_tasks) {
auto& ready_to_run_tasks = ready_to_run_tasks_it.second;
uint16_t category = ready_to_run_tasks_it.first;
if (!ready_to_run_tasks.empty()) {
ready_to_run_namespaces_[category].push_back(&task_namespace);
}
}
}
// Rearrange the task namespaces in |ready_to_run_namespaces| in such a
// way that they form a heap.
for (auto& it : ready_to_run_namespaces_) {
uint16_t category = it.first;
auto& task_namespace = it.second;
std::make_heap(task_namespace.begin(), task_namespace.end(),
CompareTaskNamespacePriority(category));
}
}其中
// This enum provides values for TaskGraph::Node::category, which is a uint16_t.
// We don't use an enum class here, as we want to keep TaskGraph::Node::category
// generic, allowing other consumers to provide their own of values.
enum TaskCategory : uint16_t {
TASK_CATEGORY_NONCONCURRENT_FOREGROUND,
TASK_CATEGORY_FOREGROUND,
TASK_CATEGORY_BACKGROUND,
};根据不同TaskCatergory会创建2个ForeGround和1个BackGroud的thread(tile worker)用于后面执行光栅化task
void CategorizedWorkerPool::Start(int num_threads) {
DCHECK(threads_.empty());
// Start |num_threads| threads for foreground work, including nonconcurrent
// foreground work.
std::vector<cc::TaskCategory> foreground_categories;
foreground_categories.push_back(cc::TASK_CATEGORY_NONCONCURRENT_FOREGROUND);
foreground_categories.push_back(cc::TASK_CATEGORY_FOREGROUND);
for (int i = 0; i < num_threads; i++) {
std::unique_ptr<base::SimpleThread> thread(new CategorizedWorkerPoolThread(
base::StringPrintf("CompositorTileWorker%d", i + 1).c_str(),
base::SimpleThread::Options(), this, foreground_categories,
&has_ready_to_run_foreground_tasks_cv_));
thread->StartAsync();
threads_.push_back(std::move(thread));
}
// Start a single thread for background work.
std::vector<cc::TaskCategory> background_categories;
background_categories.push_back(cc::TASK_CATEGORY_BACKGROUND);
// Use background priority for background thread.
base::SimpleThread::Options thread_options;
#if !defined(OS_MACOSX)
thread_options.priority = base::ThreadPriority::BACKGROUND;
#endif
auto thread = std::make_unique<CategorizedWorkerPoolThread>(
"CompositorTileWorkerBackground", thread_options, this,
background_categories, &has_ready_to_run_background_tasks_cv_);
if (backgrounding_callback_) {
thread->SetBackgroundingCallback(std::move(background_task_runner_),
std::move(backgrounding_callback_));
}
thread->StartAsync();
threads_.push_back(std::move(thread));
}其中线程创建时绑定了ThreadFunc
bool CreateThread(size_t stack_size,
bool joinable,
PlatformThread::Delegate* delegate,
PlatformThreadHandle* thread_handle,
ThreadPriority priority) {
...
pthread_t handle;
int err = pthread_create(&handle, &attributes, ThreadFunc, params.get());
...
}
启动光栅化handle函数。
void* ThreadFunc(void* params) {
...
delegate->ThreadMain();
...
}每一个Task Graph都关联有一个Namespace。DirectRasterWorkerPool类的成员变量graph_描述的Task Graph关联的Namespace由另外一个成员变量namespace_token_描述。TaskGraphRunner类的成员函数ScheduleTasks在执行一个Task Graph的光栅化任务的时候,需要指定这些光栅化任务所属的Namesapce。 namespace_按不同 token(一个task_graph_runner_绑定一个namespace_token_) 存储了不同的Namespace,某个具体的Namespace下面按不同的TaskCategory(TaksGraph中的节点具有不同的TaskCategory)存储了不同的ready_to_run_tasks。最终对ready_to_run_namespaces_按TaskCategory进行排序。
token通过以下产生
cc::NamespaceToken CategorizedWorkerPool::GenerateNamespaceToken() {
base::AutoLock lock(lock_);
return work_queue_.GenerateNamespaceToken();
}
NamespaceToken TaskGraphWorkQueue::GenerateNamespaceToken() {
NamespaceToken token(next_namespace_id_++);
DCHECK(namespaces_.find(token) == namespaces_.end());
return token;
}1、根据参数token在TaskGraphRunner类的成员变量namespaces_中找到一个TaskNamepspace对象task_namespace。这个TaskNamepspace对象保存了另外一个参数graph描述的Task Graph的状态信息,下面将会使用到。
2、前面获得的TaskNamepspace对象task_namespace的成员变量completed_tasks保存了参数graph描述的Task Graph中已经执行完成了的Task。这段代码检查在参数graph描述的Task Graph中,有哪些Task依赖了这些已经执行完成了的Task。对于依赖了这些已经执行完成了的Task的Task,相应地减少它们的dependencies值。当一个Task的dependencies值等于0的时候,就表示它所依赖的Task均已经完成,于是它自己就可以执行了。
3、检查参数graph描述的Task Graph中的Task。对于经过2的更新dependencies值等于0,并且还没有执行的Task,将会保存在前面获得的TaskNamepspace对象task_namespace的成员变量ready_to_run_tasks描述的一个Vector中,表示它们接下来将会被调度执行。
4、这段代码对从3收集到的dependencies值等于0的Task按照它们的Prioirty值组织成一个最小堆,并且将参数graph描述的Task Graph保存在前面获得的TaskNamepspace对象task_namespace的成员变量graph中。
5、取消旧的schedual的中可以取消的task
6、遍历TaskGraphRunner类内部管理的所有Namespace。对于那些成员变量ready_to_run_tasks描述的Vector不为空的Namespace,将会被保存在TaskGraphRunner类的另外一个成员变量ready_to_run_namespaces_描述的一个Vector中,也就是将那些接下来有Task可执行的Namespace收集起来,再将这些Namespace组织成一个最小堆。
这一步执行完成之后,光栅化任务就按照最小堆的方式排列好了。开始执行这些光栅化任务。(入口在哪?添加调用栈)

void CategorizedWorkerPool::RunTaskInCategoryWithLockAcquired(
cc::TaskCategory category) {
auto prioritized_task = work_queue_.GetNextTaskToRun(category);
// There may be more work available, so wake up another worker thread.
SignalHasReadyToRunTasksWithLockAcquired();
{
base::AutoUnlock unlock(lock_);
prioritized_task.task->RunOnWorkerThread();
}
auto* task_namespace = prioritized_task.task_namespace;
work_queue_.CompleteTask(std::move(prioritized_task));
// If namespace has finished running all tasks, wake up origin threads.
if (work_queue_.HasFinishedRunningTasksInNamespace(task_namespace))
has_namespaces_with_finished_running_tasks_cv_.Signal();
}
其中获取要执行的高优先级task
TaskGraphWorkQueue::PrioritizedTask TaskGraphWorkQueue::GetNextTaskToRun(
uint16_t category) {
TaskNamespace::Vector& ready_to_run_namespaces =
ready_to_run_namespaces_[category];
DCHECK(!ready_to_run_namespaces.empty());
// Take top priority TaskNamespace from |ready_to_run_namespaces|.
std::pop_heap(ready_to_run_namespaces.begin(), ready_to_run_namespaces.end(),
CompareTaskNamespacePriority(category));
TaskNamespace* task_namespace = ready_to_run_namespaces.back();
ready_to_run_namespaces.pop_back();
PrioritizedTask::Vector& ready_to_run_tasks =
task_namespace->ready_to_run_tasks[category];
DCHECK(!ready_to_run_tasks.empty());
// Take top priority task from |ready_to_run_tasks|.
std::pop_heap(ready_to_run_tasks.begin(), ready_to_run_tasks.end(),
CompareTaskPriority);
PrioritizedTask task = std::move(ready_to_run_tasks.back());
ready_to_run_tasks.pop_back();
// Add task namespace back to |ready_to_run_namespaces| if not empty after
// taking top priority task.
if (!ready_to_run_tasks.empty()) {
ready_to_run_namespaces.push_back(task_namespace);
std::push_heap(ready_to_run_namespaces.begin(),
ready_to_run_namespaces.end(),
CompareTaskNamespacePriority(category));
}
// Add task to |running_tasks|.
task.task->state().DidStart();
task_namespace->running_tasks.push_back(
std::make_pair(task.category, task.task));
return task;
}1. 从TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中取出优先级最高的Namesapce,并且将这个Namespace从Vector中删除。
2. 从第1步取出的Namepsace的成员变量ready_to_run_tasks描述的Vector中取出优先级最高的Task,并且将这个Task从Vector中删除。
3. 经过第2步操作之后 ,如果第1步取出的Namespace的成员变量ready_to_run_tasks描述的Vector不等于空,那么需要重新将它压入到TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中,并且重新对这个Vector进行最小堆排序。
4. 将第2步取出的Task保存在第1步取出的Namespace的成员变量running_tasks描述的Vector中,表示这个Task现在当前执行。
然后调用它的成员函数RunOnWorkerThread执行光栅化任务。
void TaskGraphWorkQueue::CompleteTask(PrioritizedTask completed_task) {
TaskNamespace* task_namespace = completed_task.task_namespace;
scoped_refptr<Task> task(std::move(completed_task.task));
// Remove task from |running_tasks|.
auto it = std::find_if(task_namespace->running_tasks.begin(),
task_namespace->running_tasks.end(),
[&task](const CategorizedTask& categorized_task) {
return categorized_task.second == task;
});
DCHECK(it != task_namespace->running_tasks.end());
std::swap(*it, task_namespace->running_tasks.back());
task_namespace->running_tasks.pop_back();
// Now iterate over all dependents to decrement dependencies and check if they
// are ready to run.
bool ready_to_run_namespaces_has_heap_properties = true;
for (DependentIterator it(&task_namespace->graph, task.get()); it; ++it) {
TaskGraph::Node& dependent_node = *it;
DCHECK_LT(0u, dependent_node.dependencies);
dependent_node.dependencies--;
// Task is ready if it has no dependencies and is in the new state, Add it
// to |ready_to_run_tasks_|.
if (!dependent_node.dependencies && dependent_node.task->state().IsNew()) {
PrioritizedTask::Vector& ready_to_run_tasks =
task_namespace->ready_to_run_tasks[dependent_node.category];
bool was_empty = ready_to_run_tasks.empty();
dependent_node.task->state().DidSchedule();
ready_to_run_tasks.push_back(
PrioritizedTask(dependent_node.task, task_namespace,
dependent_node.category, dependent_node.priority));
std::push_heap(ready_to_run_tasks.begin(), ready_to_run_tasks.end(),
CompareTaskPriority);
// Task namespace is ready if it has at least one ready to run task. Add
// it to |ready_to_run_namespaces_| if it just become ready.
if (was_empty) {
TaskNamespace::Vector& ready_to_run_namespaces =
ready_to_run_namespaces_[dependent_node.category];
DCHECK(!base::ContainsValue(ready_to_run_namespaces, task_namespace));
ready_to_run_namespaces.push_back(task_namespace);
}
ready_to_run_namespaces_has_heap_properties = false;
}
}
// Rearrange the task namespaces in |ready_to_run_namespaces_| in such a way
// that they yet again form a heap.
if (!ready_to_run_namespaces_has_heap_properties) {
for (auto& it : ready_to_run_namespaces_) {
uint16_t category = it.first;
auto& ready_to_run_namespaces = it.second;
std::make_heap(ready_to_run_namespaces.begin(),
ready_to_run_namespaces.end(),
CompareTaskNamespacePriority(category));
}
}
// Finally add task to |completed_tasks|.
task->state().DidFinish();
task_namespace->completed_tasks.push_back(std::move(task));
}1. 将上面第2步取出的Task从第1步取出的Namespace的成员变量running_tasks描述的Vector中删除,表示这个Task已经停止执行。
2. 在上面第1步取出的Namespace中检查有哪些Task依赖了第2步取出的Task。对于每一个依赖了的Task,都会将它的dependencies值减少1。当一个Task的dependencies值减少至0的时候,就说明它所有依赖的Task均已执行完成,于是就轮到它执行了。这时候需要将它压入到第1步取出的Namespace的成员变量ready_to_run_tasks描述的Vector中,并且重新对这个Vector进行最小堆排序。
3. 如果上面第1步取出的Namespace的成员变量ready_to_run_tasks描述的Vector在第7步中压入新的Task之前是空的,就说明这个Namespace之前已经从TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中删除了。现在由于它有了新的可以执行的Task,因此就需要重新将它压入到TaskGraphRunner类的成员变量ready_to_run_namespaces_描述的Vector中,并且对这个Vector进行最小堆排序。
4. 将第上面2步取出的Task保存在第1步取出的Namespace的成员变量completed_tasks描述的Vector中,表示这个Task已经执行完成。
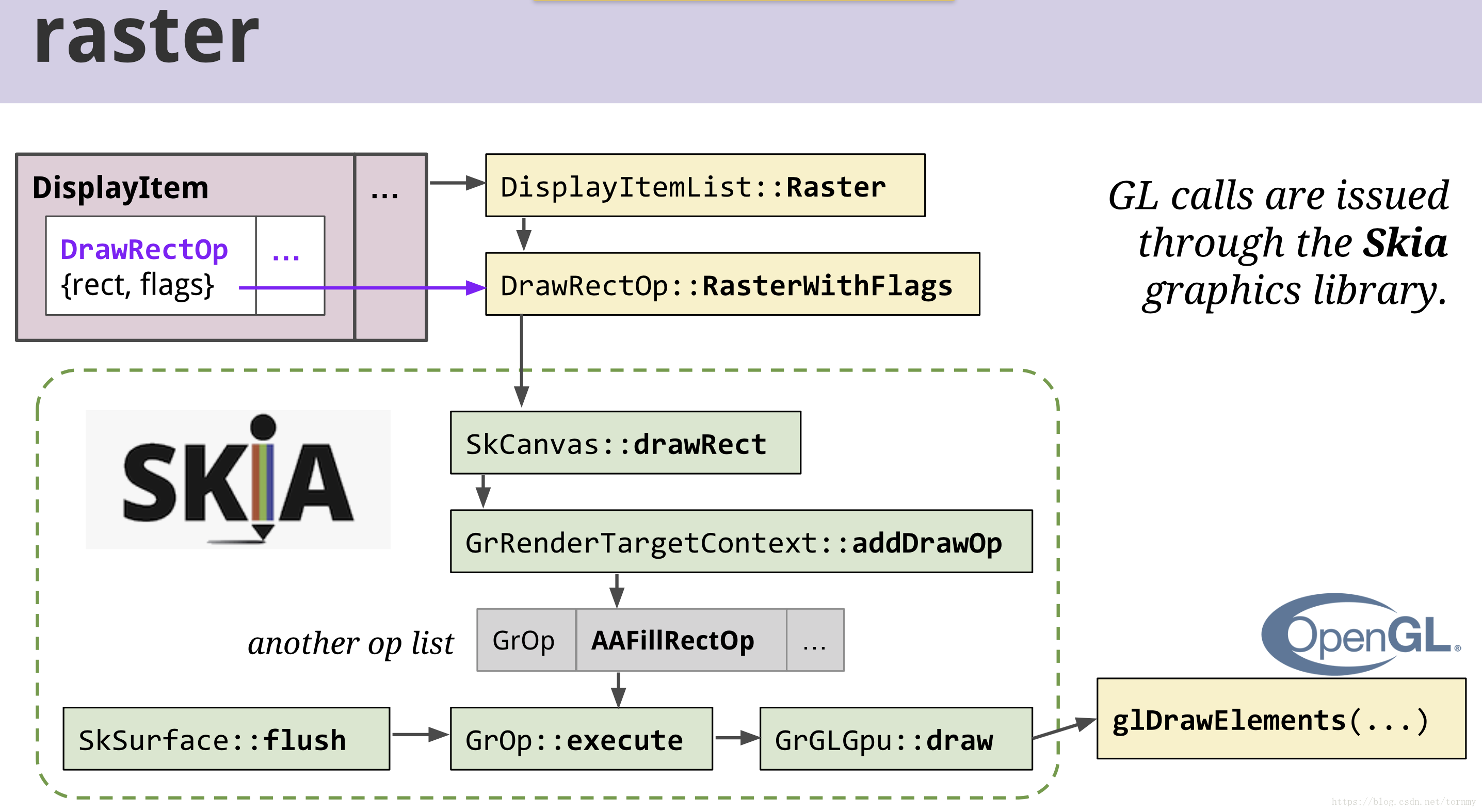
然后创建canvas,类似于GPU提供了一块缓冲区,要把绘制指令画到这个缓冲区,
static void RasterizeSource(
const RasterSource* raster_source,
...,
const gfx::Size& max_tile_size) {
gpu::raster::RasterInterface* ri = context_provider->RasterInterface();
GLuint texture_id = ri->CreateAndConsumeTexture(
texture_is_overlay_candidate, gfx::BufferUsage::SCANOUT, resource_format,
mailbox.name);
if (!texture_storage_allocated) {
viz::TextureAllocation alloc = {texture_id, texture_target,
texture_is_overlay_candidate};
viz::TextureAllocation::AllocateStorage(
ri, context_provider->ContextCapabilities(), resource_format,
resource_size, alloc, color_space);
}
{
ScopedGrContextAccess gr_context_access(context_provider);
base::Optional<viz::ClientResourceProvider::ScopedSkSurface> scoped_surface;
base::Optional<ScopedSkSurfaceForUnpremultiplyAndDither>
scoped_dither_surface;
SkSurface* surface;
if (!unpremultiply_and_dither) {
scoped_surface.emplace(context_provider->GrContext(), texture_id,
texture_target, resource_size, resource_format,
playback_settings.use_lcd_text, msaa_sample_count);
surface = scoped_surface->surface();
} else {
scoped_dither_surface.emplace(
context_provider, playback_rect, raster_full_rect, max_tile_size,
texture_id, resource_size, playback_settings.use_lcd_text,
msaa_sample_count);
surface = scoped_dither_surface->surface();
}
// Allocating an SkSurface will fail after a lost context. Pretend we
// rasterized, as the contents of the resource don't matter anymore.
if (!surface) {
DLOG(ERROR) << "Failed to allocate raster surface";
return;
}
SkCanvas* canvas = surface->getCanvas();
...
gfx::Size content_size = raster_source->GetContentSize(transform.scale());
raster_source->PlaybackToCanvas(canvas, color_space, content_size,
raster_full_rect, playback_rect, transform,
playback_settings);
}
}