我们在前面的章节中介绍的所有技术都是光栅化算法的基础。 不过,我们只是以非常基本的方式实现了这些技术。 GPU 渲染管道和其他基于光栅化的生产渲染器使用相同的概念,但它们使用这些算法的高度优化版本。 展示用于加速算法的所有不同技巧远远超出了介绍的范围。 我们现在将快速回顾其中的一些内容,但我们计划将来专门针对该主题开设一课。
NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎
1、抗锯齿
首先,让我们考虑 3D 渲染的一个基本问题。 如果放大我们在上一章中渲染的三角形图像,你会发现三角形的边缘并不规则(实际上,它不是特定于三角形的边缘,你还可以看到 棋盘图案在正方形的边缘是不规则的)。 你可以在图 1 中轻松看到的台阶称为锯齿(jaggies):

图 1:使用抗锯齿功能可以减少锯齿状边缘像素伪影
这些锯齿状边缘或阶梯状边缘(取决于你喜欢如何称呼它们)并不是人工制品,这只是三角形被分解为像素的结果。 我们对光栅化过程所做的是将连续表面(三角形)分解为离散元素(像素),这是我们在渲染简介中已经提到的过程。 这个问题类似于尝试用乐高积木表示连续的曲线或曲面。 这根本做不到,你总是会看到砖块(图 2):
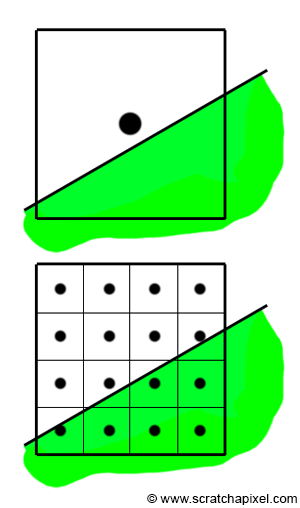
图 2:当使用一个样本时,三角形会丢失。 但通过使用子像素,我们可以检测到该像素至少部分与三角形重叠。 像素颜色等于子像素颜色的总和除以子像素或样本的总数(在本例中为 16 个样本)。
渲染中解决此问题的方法称为抗锯齿(也表示为 AA:AntiAlias)。 我们不是每个像素仅渲染 1 个样本(通过测试像素中心的点是否覆盖三角形来检查像素是否与三角形重叠),而是将像素拆分为子像素并对每个子像素重复覆盖测试 。 当然,每个子像素只不过是另一个砖块,因此这并不能完全解决问题。 尽管如此,它仍然可以更精确地捕捉物体的边缘。 大多数情况下,像素被划分为 N × N 个子像素,其中 N 通常是 2 的幂(2、4、8 等),尽管从技术上讲它可以采用任何大于或等于 1 的值( 1、2、3、4、5 等)。 有多种方法可以解决此别名问题。 我们描述的方法属于基于采样的抗锯齿方法的范畴。
像素最终颜色的计算方式为所有子像素颜色的总和除以子像素总数。 让我们举一个例子(与像素一样,如果子像素或样本覆盖了一个三角形,那么它就会呈现该三角形的颜色,否则它就会呈现通常为黑色的背景颜色)。 想象一下三角形是白色的。 如果只有 2 或 4 个样本与三角形重叠,则最终像素颜色将等于 (0+0+1+1)/4=0.5。 像素不会是全白的,但也不会是全黑的。 因此,该过渡更加渐进,而不是在三角形边缘和背景之间具有“二元”过渡,这减少了阶梯式像素伪影。 这就是我们所说的抗锯齿。 要了解抗锯齿,你需要研究信号处理理论,这本身也是一个非常庞大且相当复杂的主题。
之所以最好选择N作为2的幂,是因为现在大多数处理器都可以并行运行多条指令,并且并行运行的指令数一般也是2的幂。你可以看一下 Web 适用于 CPU 特有的 SSE 指令集等事物,但 GPU 使用相同的概念。 SSE 是大多数现代 CPU 上都提供的一项功能,通常可用于同时(在一个周期内)运行 4 或 8 个浮点计算。 所有这一切意味着,以 1 次浮点运算的价格,你可以免费获得 3 或 7 次浮点运算。 理论上,这可以将渲染时间加快 4 或 8 倍(尽管永远无法达到该性能水平,因为你需要为设置这些指令付出一些代价)。 例如,你可以使用 SSE 指令以计算 1 像素的成本来渲染 2x2 超像素,因此,可以“免费”获得更平滑的边缘(阶梯状边缘不太明显)。
2、渲染像素块
加速光栅化的另一种常见技术是渲染像素块(blocks of pixels),但我们不是测试块中包含的所有像素,而是首先开始测试块角处的像素。 GPU 算法可以使用 8x8 像素块。 所使用的技术更加复杂,并且基于图块的概念,但我们在这里不做详细介绍。
如果该 8x8 网格的所有四个角都覆盖了三角形,那么网格的其他像素也必然会覆盖矩形(如图 7 所示):
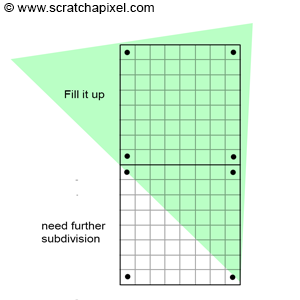
图 7:如果 8x8 像素网格的 4 个角与三角形重叠,则网格的所有剩余像素也会覆盖该三角形
在这种情况下,无需测试所有其他像素,从而节省时间。 它们可以用三角形的颜色填充。 如果顶点属性需要跨像素块进行插值,这也很简单,因为如果你在块的角点计算了它们,那么需要做的就是在两个方向(水平和垂直)上线性插值它们。 此优化仅在三角形靠近屏幕且屏幕空间较大时才有效。 小三角形不会从这种技术中受益。
3、优化边缘函数
边缘函数也可以被优化。 我们再看一下函数的实现:
int orient2d(const Point2D& a, const Point2D& b, const Point2D& c)
{
return (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x - a.x);
}回想一下,该函数中的 a 和 b 是三角形顶点,c 是像素坐标(在光栅空间中)。 需要注意的一件有趣的事情是,将为三角形边界框中包含的每个像素调用此函数。 尽管当我们迭代多个像素时,只有 c 发生变化。 变量 a 和 b 保持不变。 假设我们对方程求值一次并得到结果 w0:
w0 = (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x - a.x);然后 c.x 增加一个量 s(每像素步长)。 w0 的新值将是:
w0_new = (b.x - a.x) * (c.y - a.y) - (b.y - a.y) * (c.x + s - a.x);用第二个方程减去第一个方程,我们得到:
w0_new - w0 = -(b.y - a.y) * s;项 -(b.y - a.y) * s 是给定三角形的常数值,因为 s 每次都是相同的量(一个像素),并且已经提到的 a 和 b 也是常数。 我们可以计算一次并将其存储在变量中(称为 w0_step),然后计算减少为:
w0_new = w0 + w0step;你可以对 w1 和 w2 执行此操作,也可以对 c.y 步骤执行类似的操作。
边缘函数使用 2 个乘数和 5 个子数,但通过这个技巧,它可以简化为简单的加法(当然你需要计算初始值)。 这种技术在互联网上有详细记录。 我们不会在本课程中使用它,但我们将更详细地研究它,并在另一节专门介绍高级光栅化技术的课程中实现它。
4、使用定点坐标
最后,作为本节的总结,我们将简要讨论在光栅化阶段之前将最初以浮点格式定义的顶点坐标转换为定点格式的技术。 定点(fixed point)是整数的花哨词(实际上是正确的技术术语)。
当顶点坐标从 NDC 转换为栅格空间时,它们也会从浮点数转换为定点数。 我们为什么要这么做? 这个问题没有简单快速的答案。 但简而言之,我们只能说 GPU 使用定点运算,因为从计算的角度来看,操作整数比操作浮点数或双精度数更容易、更快(它只需要逻辑位运算)。 同样,这只是一个非常通用的解释。 从浮点到整数坐标的转换以及如何使用整数坐标实现光栅化过程是一个庞大而复杂的主题,在互联网上没有记录(你会发现关于这个主题的信息很少,考虑到这个过程是现代 GPU 工作方式的核心,就会感到非常奇怪)。
转换步骤涉及将顶点坐标四舍五入到最接近的整数。 不过,如果只这样做,那么你就会将顶点坐标捕捉到最近的像素角坐标。 当渲染静态图像时,这并不是什么大问题,但它会产生动画的视觉伪影(顶点在帧与帧之间被捕捉到不同的像素)。 解决方法是将数字转换为最小整数值,但同时保留一些位来编码顶点的子像素位置(顶点位置的小数部分)。
GPU 通常使用 4 位来编码子像素精度(你可以在图形 API 文档中搜索术语sub-pixel precision)。 换句话说,在 32 位整数上,1 位可能用于编码数字的符号,27 位用于编码顶点整数位置,4 位用于编码像素内顶点的小数位置。 这意味着顶点位置“捕捉”到 16x16 子像素网格的最近角,如图 8 所示(使用 4 位,可以表示 [1:15] 范围内的任何整数):
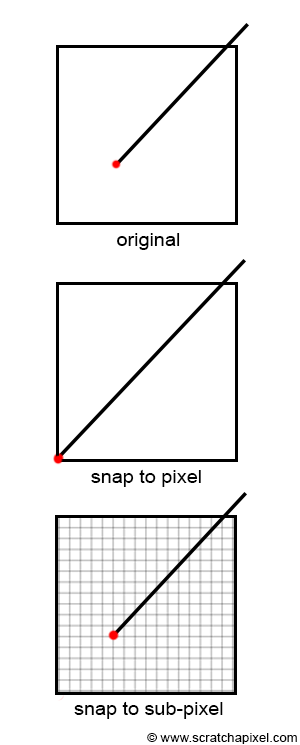
图 8:定点坐标
不知何故,顶点位置仍然会捕捉到某个网格角,但在这种情况下,捕捉的问题比顶点捕捉到像素坐标时的问题要小。 此转换过程会导致许多其他问题,其中之一是整数溢出(当算术运算的结果产生的数字大于可用位数编码的数字时,就会发生溢出)。 发生这种情况的原因是整数比浮点数覆盖的值范围更小。 当抗锯齿混入其中时,事情也会变得有点复杂。 详细探讨这个主题本身就需要一堂课。
固定点坐标可以进一步加速光栅化过程和边缘函数。 这就是将顶点坐标转换为整数的原因之一。 这些优化技术将在另一节课中介绍。
5、关于光栅化算法实现的注意事项
最后,我们将快速回顾一下源代码章节中提供的代码。 以下是其主要组件的描述:
我们将使用函数 computeScreenCooperatives 来计算屏幕坐标,使用针孔相机模型课程中详细介绍的方法。 这本质上是为了确保我们的渲染输出可以与同样使用基于物理的相机模型的 Maya 渲染进行比较:
float t, b, l, r;
computeScreenCoordinates(
filmApertureWidth, filmApertureHeight,
imageWidth, imageHeight,
kOverscan,
nearClippingPLane,
focalLength,
t, b, l, r); 函数 convertToRaster()是我们将三角形顶点坐标从相机空间转换到光栅空间的地方。 该函数类似于我们在上一课中实现的函数 computePixelCooperatives()。 请记住,在本课的第二章中,我们学习了一种将坐标从屏幕空间转换到 NDC 空间的方法(请记住,在 GPU 世界中,NDC 空间中的坐标在 [-1,1] 范围内)。 我们将在此函数中使用相同的重新映射方法。
另一件需要记住的重要事情是,直到上一课,投影点都是二维点。 从现在开始,它们将需要是 3D 点。 在这些点的 x 和 y 坐标中,我们将存储投影点在屏幕空间中的坐标。 在 z 坐标中,我们将存储顶点相机空间 z 坐标。 需要 z 坐标来解决可见性问题,如本课程第四章中所述:
convertToRaster(v0, worldToCamera, l, r, t, b, nearClippingPLane, imageWidth, imageHeight, v0Raster);
convertToRaster(v1, worldToCamera, l, r, t, b, nearClippingPLane, imageWidth, imageHeight, v1Raster);
convertToRaster(v2, worldToCamera, l, r, t, b, nearClippingPLane, imageWidth, imageHeight, v2Raster);不要忘记,与三角形顶点关联的所有顶点属性也需要被这些顶点的 z 坐标“预除”(这是透视正确插值所需要的)。 它通常在三角形渲染之前完成(就在迭代像素的循环之前)。 但要小心,因为在代码中顶点 z 坐标设置为其倒数(以加快样本深度的计算)。 因此,我们将使用乘法而不是除法:
// precompute reciprocal of the vertex z-coordinate
v0Raster.z = 1 / v0Raster.z,
v1Raster.z = 1 / v1Raster.z,
v2Raster.z = 1 / v2Raster.z;
Vec2f st0 = st[stindices[i * 3]];
Vec2f st1 = st[stindices[i * 3 + 1]];
Vec2f st2 = st[stindices[i * 3 + 2]];
// This is needed for perspective correct interpolation
st0 *= v0Raster.z, st1 *= v1Raster.z, st2 *= v2Raster.z;该函数包含两个循环。 第一个迭代场景中的所有三角形(外部循环),第二个迭代与正在渲染的三角形重叠的边界框中包含的所有像素(内部循环)。 请注意,内循环中的一些变量是恒定的,因此可以预先计算。 例如,三角形顶点的 z 坐标的倒数就是这种情况,对于覆盖三角形的每个像素(以及需要除以它们各自的 z 坐标的顶点属性)进行线性插值:
// Outer loop. Loop over triangles
for (uint32_t i = 0; i < ntris; ++i) {
...
// Inner loop. Loop over pixels
for (uint32_t y = y0; y <= y1; ++y) {
for (uint32_t x = x0; x <= x1; ++x) {
...
}
}
}程序的其余部分很简单。 使用边缘函数技术测试每个像素的覆盖范围。 如果一个像素覆盖一个三角形,我们就计算像素的重心坐标。 然后我们使用这些坐标来计算样本的深度。 如果我们通过了深度缓冲区测试,我们就会使用新的深度值更新缓冲区,并使用三角形颜色更新帧缓冲区:
Vec3f pixelSample(x + 0.5, y + 0.5, 0);
float w0 = edgeFunction(v1Raster, v2Raster, pixelSample);
float w1 = edgeFunction(v2Raster, v0Raster, pixelSample);
float w2 = edgeFunction(v0Raster, v1Raster, pixelSample);
if (w0 >= 0 && w1 >= 0 && w2 >= 0) {
w0 /= area;
w1 /= area;
w2 /= area;
// linearly interpolate sample depth
float oneOverZ = v0Raster.z * w0 + v1Raster.z * w1 + v2Raster.z * w2;
float z = 1 / oneOverZ;
// do we pass the depth buffer test?
if (z < depthBuffer[y * imageWidth + x]) {
depthBuffer[y * imageWidth + x] = z;
// update frame buffer
...
}
}为了使其在视觉上更有趣,我们将使用多种着色技术。 我们使用的模型只有一个顶点属性:st 或纹理坐标。 纹理坐标可用于创建棋盘图案,然后将其与称为面比的简单着色技巧相结合。 面向比采用三角形法线(我们可以通过三角形任意两条边之间的简单叉积来计算)和视图方向之间的点积。 视图方向只是由正在着色的三角形上的点 P 和相机位置 E 定义的向量。由于程序中该点的所有点都是在相机空间中定义的,因此相机位置(或眼睛位置)为 简单的 E=(0,0,0)。 因此,视图方向可以简单地计算为 -P,然后需要对其进行归一化。 点积可能为负,因此我们需要限制它(我们只需要正值):
Vec3f n = (v1Cam - v0Cam).crossProduct(v2Cam - v0Cam);
n.normalize();
Vec3f viewDirection = -pt;
viewDirection.normalize();
// facing ratio
float nDotView = std::max(0.f, n.dotProduct(viewDirection));// Get triangle vertices in camera space.
Vec3f v0Cam, v1Cam, v2Cam;
worldToCamera.multVecMatrix(v0, v0Cam);
worldToCamera.multVecMatrix(v1, v1Cam);
worldToCamera.multVecMatrix(v2, v2Cam);
// Divide them by the respective z-coordinate as with any other vertex attribute and interpolate using
// barycentric coordinates.
float px = (v0Cam.x/-v0Cam.z) * w0 + (v1Cam.x/-v1Cam.z) * w1 + (v2Cam.x/-v2Cam.z) * w2;
float py = (v0Cam.y/-v0Cam.z) * w0 + (v1Cam.y/-v1Cam.z) * w1 + (v2Cam.y/-v2Cam.z) * w2;
// P in camera space
Vec3f pt(px * z, py * z, -z);最后,帧缓冲区的内容存储在PPM文件中。
这是程序应该产生的结果。 在左侧,可以看到 Maya 中对象的渲染。 右边是我们的渲染。 正如你所看到的,结果在对象位置和阴影方面是相同的。 Maya 使用一种称为随机采样的技术,该技术可以使锯齿伪像比我们的渲染中稍微不那么明显,但差异很微妙:

正如你所看到的,渲染并没有什么神奇之处。 当了解规则后,你可以重现专业应用程序生成的图像。
作为奖励,我们导出了图像中每个像素重叠的三角形上的点在世界空间中的位置。 然后我们在 3D 查看器中显示所有点。 您可以在下面看到结果。 毫不奇怪,点仅出现在相机直接可见的对象部分上。 这表明深度缓冲技术按预期工作。 对象背面被另一个三角形隐藏的每个三角形都不会被渲染。 右图显示了同一点集的特写:

6、结束语
光栅化的主要优点是简单和速度。 主要缺点是它仅对解决可见性问题有用。 请记住,渲染涉及两个步骤:可见性和着色。 该算法在着色方面没有用处。
在本课中,我们已经介绍了有关光栅化算法所需了解的所有信息。 你可以从中学到的其他内容并不是关于技术本身,而是更多关于优化它(如何并行运行它、如何使其高效、如何在 GPU 上运行它等)。
本系列教程的源码可以从这里下载。
原文链接:光栅化算法优化 - BimAnt