概述
本文牵涉的概念是候选区域(Region Proposal ),用于物体检测算法的输入。无论是机器学习算法还是深度学习算法,候选区域都有用武之地。
本文的来源是翻译参考资料里的《Selective Search for Object Detection (C++ / Python)》,这是国外一个大神的博客,讲的是择性搜索(Selective Search)这一种产生候选区域的算法。这个算法并不是那个博主的原创,原创是2013年的一篇论文,我发现国内很多博客都做了介绍。
由于本人想系统的把从机器学习到深度学习的物体检测算法捋一遍,所以在此把国外大神的博客翻译一下,另外加一些自己的理解。
物体检测和物体识别
物体识别是要分辨出图片中有什么物体,输入是图片,输出是类别标签和概率。物体检测算法不仅要检测图片中有什么物体,还要输出物体的外框(x, y, width, height)来定位物体的位置。
物体检测的核心就是物体识别。
为了定位物体,我们需要选择一些子区域并在子区域上运行物体识别算法。物体的位置就是物体识别算法返回最高概率的子区域内。

产生候选子区域的最直接的方法就是滑窗法,但是这种办法效率比较低,一般使用‘候选区域’算法,而择性搜索(Selective Search)就是最流行的候选区域产生算法之一(个人理解:这个最流行可能是针对论文那两年说的,现在深度学习都是使用网络产生候选区域,不用算法生成了)。
滑窗法
在滑窗方案中,我们要使用一个小窗口遍历搜索整张图片,在每个位置上对滑窗内的图片做物体识别算法。不仅要搜索不同的位置,还要遍历不同的大小,工作量可想而知。
问题还没完,对于人脸和人体这种长宽比基本固定的物体还好,对于长宽不固定的物体,搜索起来简直就是噩梦,计算量直接飙升。
候选区域(Region Proposal)算法
滑窗法的问题可以使用候选区域产生算法解决。这些算法输入整张图片,然后输出可能有物体的候选区域位置,这些候选区域可以有噪声或者重叠,或者和物体的重合度不是很好,这都不要紧,只要这些区域里有一个和实际物体的位置足够接近就行。因为不好的候选区域会被物体识别算法过滤掉。
候选区域算法用分割不同区域的办法来识别潜在的物体。在分割的时候,我们要合并那些在某些方面(如颜色、纹理)类似的小区域。相比滑窗法在不同位置和大小的穷举,候选区域算法将像素分配到少数的分割区域中。所以最终候选区域算法产生的数量比滑窗法少的多,从而大大减少运行物体识别算法的次数。同时候选区域算法所选定的范围天然兼顾了不同的大小和长宽比。
候选区域算法比较重要的特征就是要有较高的召回率。我们要通过这种方法保证拥有物体的区域就在候选区域列表里。所以我们不介意有很多区域什么都有,这都没关系,物体检测算法会过滤掉他们,虽然会浪费一点时间。
目前已有不少成熟的后续区域产生算法:
- Objectness
- Constrained Parametric Min-Cuts for Automatic Object Segmentation
- Category Independent Object Proposals
- Randomized Prim
- Selective Search
由于Selective Search又快召回率又高,这个方法是最常用的。说了这么多,终于牵出本文的主角了。
物体检测之选择性搜索(Selective Search)
选择性搜索算法用于为物体检测算法提供候选区域,它速度快,召回率高。
选择性搜索算法需要先使用《Efficient Graph-Based Image Segmentation》论文里的方法产生初始的分割区域,然后使用相似度计算方法合并一些小的区域。
下列两张图分别是原图和原始分割图:


我们不能使用原始分割图的区域作为候选区域,原因如下:
1. 大部分物体在原始分割图里都被分为多个区域
2. 原始分割图无法体现物体之间的遮挡和包含。
如果我们试图通过进一步合并相邻的区域来解决第一个问题,我们最终会得到一个包含两个对象的分段区域。
我们不要需要完美的的分割区域,我们只想要和实际物体高度重合的区域就行了。
选择性搜索算法使用《Efficient Graph-Based Image Segmentation》论文里的方法产生初始的分割区域作为输入,通过下面的步骤进行合并:
1. 首先将所有分割区域的外框加到候选区域列表中
2. 基于相似度合并一些区域
3. 将合并后的分割区域作为一个整体,跳到步骤1
通过不停的迭代,候选区域列表中的区域越来越大。可以说,我们通过自底向下的方法创建了越来越大的候选区域。表示效果如下:
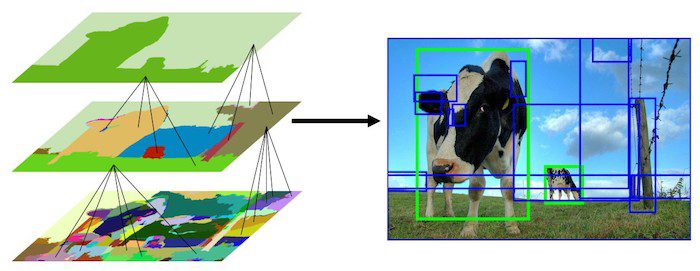
相似度
选择性搜索算法如何计算两个区域的像素度的呢?
主要是通过以下四个方面:颜色、纹理、大小和形状交叠
最终的相似度是这四个值取不同的权重相加
效果
opencv实现了选择性搜索算法,可以给出上千个根据有物体的可能性降序排列的候选区域。
下图是画出了前面200~250个候选区域的效果。一般来说。1000~1200个候选区域基本能胜任物体检测的任务了。


opencv中的实现-python版本
代码主要参考《Selective Search for Object Detection (C++ / Python)》
#!/usr/bin/env python
'''
Usage:
./ssearch.py input_image (f|q)
f=fast, q=quality
Use "l" to display less rects, 'm' to display more rects, "q" to quit.
'''
import sys
import cv2
if __name__ == '__main__':
# speed-up using multithreads
cv2.setUseOptimized( True );
cv2.setNumThreads( 4 );
# read image
im = cv2.imread( './test.jpg' )
# resize image
newHeight = 200
newWidth = int( im.shape[1] * 200 / im.shape[0] )
im = cv2.resize( im, (newWidth, newHeight) )
# create Selective Search Segmentation Object using default parameters
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
# set input image on which we will run segmentation
ss.setBaseImage( im )
if 1:
# Switch to fast but low recall Selective Search method
ss.switchToSelectiveSearchFast()
else:
# Switch to high recall but slow Selective Search method
ss.switchToSelectiveSearchQuality()
# run selective search segmentation on input image
rects = ss.process()
print( 'Total Number of Region Proposals: {}'.format( len( rects ) ) )
# number of region proposals to show
numShowRects = 100
# increment to increase/decrease total number
# of reason proposals to be shown
increment = 50
while True:
# create a copy of original image
imOut = im.copy()
# itereate over all the region proposals
for i, rect in enumerate( rects ):
# draw rectangle for region proposal till numShowRects
if (i < numShowRects):
x, y, w, h = rect
cv2.rectangle( imOut, (x, y), (x + w, y + h), (0, 255, 0), 1, cv2.LINE_AA )
else:
break
# show output
cv2.imshow( "Output", imOut )
# record key press
k = cv2.waitKey( 0 ) & 0xFF
# m is pressed
if k == 109:
# increase total number of rectangles to show by increment
numShowRects += increment
# l is pressed
elif k == 108 and numShowRects > increment:
# decrease total number of rectangles to show by increment
numShowRects -= increment
# q is pressed
elif k == 113:
break
# close image show window
cv2.destroyAllWindows()测试的效果也一般般,还是要靠深度。