目标检测系列:
目标检测(object detection)系列(一) R-CNN:CNN目标检测的开山之作
目标检测(object detection)系列(二) SPP-Net:让卷积计算可以共享
目标检测(object detection)系列(三) Fast R-CNN:end-to-end的愉快训练
目标检测(object detection)系列(四) Faster R-CNN:有RPN的Fast R-CNN
目标检测(object detection)系列(五) YOLO:目标检测的另一种打开方式
目标检测(object detection)系列(六) SSD:兼顾效率和准确性
目标检测(object detection)系列(七) R-FCN:位置敏感的Faster R-CNN
目标检测(object detection)系列(八) YOLOv2:更好,更快,更强
目标检测(object detection)系列(九) YOLOv3:取百家所长成一家之言
目标检测(object detection)系列(十) FPN:用特征金字塔引入多尺度
目标检测(object detection)系列(十一) RetinaNet:one-stage检测器巅峰之作
目标检测(object detection)系列(十二) CornerNet:anchor free的开端
目标检测扩展系列:
目标检测(object detection)扩展系列(一) Selective Search:选择性搜索算法
目标检测(object detection)扩展系列(二) OHEM:在线难例挖掘
目标检测(object detection)扩展系列(三) Faster R-CNN,YOLO,SSD,YOLOv2,YOLOv3在损失函数上的区别
简介
在Faster R-CNN算法之前,R-CNN,SPP-Net和Faster R-CNN这些方法中,都用到了SS(Selective Search)算法,它其实是一种区域建议算法为后续的检测任务提供候选框,SS的论文是《Selective Search for Object Recognition》,即便是这篇论文自己的任务最后都是目标识别:

如果我们再把时间往前推移一段,在HOG行人检测任务里,也在做类似的事情,只是HOG用的是滑动窗遍历,这就比较尴尬,图像中的目标总会以不同的尺寸,位置出现,滑动窗的大小和步长是个不好选择的参数,所以在RPN和one stage的检测方法没有出来的时候,类似SS的区域建议方法是个不错的选择。
Selective Search原理
选择性搜索算法使用基于图的分割算法(Graph-Based Segmentation)生成初始区域,随后使用一系列的相似度判别规则决定哪些区域应该被合并到一起,再次合并后最终实现区域建议生成。
基于图的分割算法
基于图的图像分割算法其实是一个独立经典的图像分割的方法,它更加古老,是一篇2004年的论文《Efficient Graph-Based Image Segmentation》,不过,目前直接用它做分割的应该比较少,很多算法用它作预处理过程,比如Selective Search。
最小生成树(MST)
基于图的分割算法将图像用加权图的形式抽象化表示,一个无向图
由顶点集
与边集
组成,那么图
可以表示为
,连接一对顶点
的边
具有权重
,无向图指顶点间的边没有方向,下面这张图就是一个无向图的示例,其中数字表示边
的权重
,比如边
的权重是4 。

树结构是一种特殊的图,树中的点的集合互不交叉,这意味着在图中将不存在使集合产生回路的边。上图中实线表示的边与其连接的点组成的就是一棵树。
而最小生成树(minimun spanning tree,MST)又是一种特殊的树结构,给定需要连接的顶点,选择边的权重之和最小时的树结构就是最小生成树,我们假设上面的树结构就是最小生成树。
分割策略
在基于图的分割算法中,将每一个像素点做为图中一个顶点,然后将顶点逐步合并为一个区域。合并区域是以最小生成树作为依据连接,保证整个无向图中没有重叠的区域,而且每个区域的权重和都是最小的。那么在图像中,顶点间的权重应该怎么表示?
对于一对像素点
的边
,其权值
用两点灰度值的欧氏距离来表示,当图像为RGB三通道时,权值的公式为:
表示像素点
的
通道的灰度值,其余的同理。权重
可以做为衡量两个像素点间差异的标准,即两点间的不相似度。两个区域间的不相似度同样依照该方法求取,对于两个区域
和
,其连接方式如下图。

其中,像素点
,
,
构成区域
,像素点
,
,
构成区域
,图中虚线为可能使
和
合并的连接方式。根据MST定义,如果
和
w(G_{1},G_{2})
e(G_{1},G_{2})$,定义其为类间差异
,并与设定阈值的比较决定是否合并这两个区域。
下面的问题就是,阈值是什么?
基于图的分割算法使用一种局部自适应阈值的方式,避免了全局阈值带来的分割过细或过粗糙的问题。阈值选择为区域的类内差异
:
其中
为
的边集,类内差异为边集中每个边的不相似度的最大值。最终两个区域是否合并的条件是类间差异是不是小于类内差异:
这样一来,就解决了两个区域是否要合并的问题,但是问题是,在一张图像开始的时候用最小生成树生成区域,它会有只剩下一个像素点的情况,这就是区域的特殊情况,一个像素点就是一个区域。单个像素点的类内差异是0,想要让上面的公式成立,就要类间的差异也是0,这显然不可能,这样一来,就会造成过分割。
为了解决这个问题,要为每个像素点分配一个初始的类内差异
,
是像素点的个数,
是一个人为设定的超参数。当区域内像素点个数逐渐增多,
的作用将越来越小,而对于单个的像素点,
将保持初始值不变。增加初始值后的类间差异为:
相似度判别原理
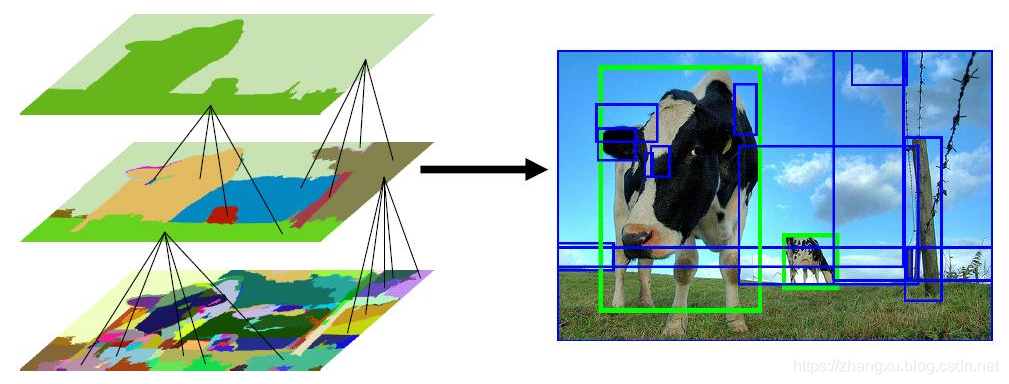
经过初始分割之后,效果就像下图中左侧最下方那张图,分割的效果过细,无法作为区域建议使用。在此基础上,SS算法根据颜色,纹理,尺寸和空间交叠率四个方面衡量区域间的相似度,对分割后的结果进行再一次的合并。
颜色相似度
颜色的相似度计算选用HSV颜色空间中的色调,对于RGB图像中的每个区域
中单个通道的色调在bin=25的直方图上进行投票,其结果用
表示,所以三通道情况下bin=75。区域之间颜色相似度,通过归一化后直方图交叉核式子来计算:
纹理相似度
纹理相似度采用 的高斯分布在8邻域方向做梯度统计,然后每个通道的梯度方向以bins=10计算直方图,其结果用
表示,所以直方图维度为
。最后使用与颜色相似度相同的方式计算纹理相似度:
尺寸相似度
尺寸相似度采用像素面积计算,其中
为整个图像的像素面积,
为区域
的像素面积,
为区域
的像素面积。显然当
与
都很小时,尺寸相似度趋近1,这保证了较小的区域优先合并,从而避免大区域不断合并小区域。
空间交叠率
交叠相似度同样采用像素面积计算,其中
是区域
和区域
的最小外接矩形的像素面积。越高的重叠度意味着两个区域接触的像素点越多,两个区域占
的比例就会越高,交叠相似度也就会越高,这保证了交叠度高的区域优先合并。
最终的相似度是上述四个相似度的加权和:
合并候选框
通过上面的相似度判别依据,接下来要逐个合并图分割生成的候选框,SS采用这样的策略:

算法:
利用切分方法得到候选的区域集合R = {r1,r2,…,rn}
初始化相似集合S = ϕ
遍历邻居区域对(ri,rj) do
计算相似度s(ri,rj)
S = S ∪ s(ri,rj)
while S not=ϕ do
从S中得到最大的相似度s(ri,rj)=max(S)
合并对应的区域rt = ri ∪ rj
移除ri对应的所有相似度:S = S\s(ri,r*)
移除rj对应的所有相似度:S = S\s(r*,rj)
计算rt对应的相似度集合St
S = S ∪ St
R = R ∪ rt
L = R中所有区域对应的边框
最终,候选框会被合并成一张图,但是每次的合并过程所对应的图层,以及它们合并时的相似度大小,都被记录下来了。这样一来就会有很多的图层,每个图层中又有若干的区域,这些区域还存在很大的重复,并且,不同的目标可能在这个图层中存在,在另一图层中又没了,所以我们需要一些策略对这些区域建议打分,最终的阈值决定将哪些区域最后输出出来。
Selective Search效果

上面这张图,说明了SS在多目标,多尺度,多形态下的区域建议效果,这个起码比滑动窗好多了。
