在基于深度学习的目标检测算法的综述 那一节中我们提到基于区域提名的目标检测中广泛使用的选择性搜索算法。并且该算法后来被应用到了R-CNN,SPP-Net,Fast R-CNN中。因此我任务还是有研究的必要。
传统的目标检测算法大多数以图像识别为基础。一般可以在图片上使用穷举法或者滑动窗口选出所有物体可能出现的区域框,对这些区域框提取特征并进行使用图像识别分类方法,得到所有分类成功的区域后,通过非极大值抑制输出结果。
在图片上使用穷举法或者滑动窗口选出所有物体可能出现的区域框,就是在原始图片上进行不同尺度不同大小的滑窗,获取每个可能的位置。而这样做的缺点也显而易见,复杂度太高,产生了很多的冗余候选区域,而且由于不可能每个尺度都兼顾到,因此得到的目标位置也不可能那么准,在现实当中不可行。而选择性搜索有效地去除冗余候选区域,使得计算量大大的减小。

我们先来看一组图片,由于我们事先不知道需要检测哪个类别,因此第一张图的桌子、瓶子、餐具都是一个个候选目标,而餐具包含在桌子这个目标内,勺子又包含在碗内。这张图展示了目标检测的层级关系以及尺度关系,那我们如何去获得这些可能目标的位置呢。我们能不能通过视觉特征去减少候选框的数量并提高精确度呢。
可用的特征有很多,到底什么特征是有用的呢?我们看第二副图片的两只猫咪,他们的纹理是一样的,因此纹理特征肯定不行了。而如果通过颜色则能很好区分。但是第三幅图变色龙可就不行了,这时候边缘特征、纹理特征又显得比较有用。而在最后一幅图中,我们很容易把车和轮胎看作是一个整体,但是其实这两者的特征差距真的很明显啊,无论是颜色还是纹理或是边缘都差的太远了。而这这是几种情况,自然图像那么多,我们通过什么特征去区分?应该区分到什么尺度?
selective search的策略是,既然是不知道尺度是怎样的,那我们就尽可能遍历所有的尺度好了,但是不同于暴力穷举,我们可以先利用基于图的图像分割的方法得到小尺度的区域,然后一次次合并得到大的尺寸就好了,这样也符合人类的视觉认知。既然特征很多,那就把我们知道的特征都用上,但是同时也要照顾下计算复杂度,不然和穷举法也没啥区别了。最后还要做的是能够对每个区域进行排序,这样你想要多少个候选我就产生多少个,不然总是产生那么多你也用不完不是吗?
- 适应不同尺度(Capture All Scales):穷举搜索(Exhaustive Selective)通过改变窗口大小来适应物体的不同尺度,选择搜索(Selective Search)同样无法避免这个问题。算法采用了图像分割(Image Segmentation)以及使用一种层次算法(Hierarchical Algorithm)有效地解决了这个问题。
- 多样化(Diversification):单一的策略无法应对多种类别的图像。使用颜色(color)、纹理(texture)、大小(size)等多种策略对分割好的区域(region)进行合并。
- 速度快(Fast to Compute):算法,就像功夫一样,唯快不破!
一 选择性搜索的具体算法(区域合并算法)

首先通过基于图的图像分割方法初始化原始区域,就是将图像分割成很多很多的小块。然后我们使用贪心策略,计算每两个相邻的区域的相似度,然后每次合并最相似的两块,直到最终只剩下一块完整的图片。然后这其中每次产生的图像块包括合并的图像块我们都保存下来,这样就得到图像的分层表示了呢。那我们如何计算两个图像块的相似度呢?
二 保持多样性的策略
区域合并采用了多样性的策略,如果简单采用一种策略很容易错误合并不相似的区域,比如只考虑纹理时,不同颜色的区域很容易被误合并。选择性搜索采用三种多样性策略来增加候选区域以保证召回:
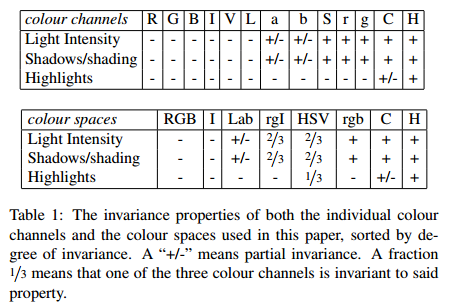
- 多种颜色空间,考虑RGB、灰度、HSV及其变种等
- 多种相似度度量标准,既考虑颜色相似度,又考虑纹理、大小、重叠情况等。
- 并通过改变阈值初始化原始区域,阈值越大,分割的区域越少。
1、颜色空间变换
通过色彩空间变换,将原始色彩空间转换到多达八中的色彩空间。作者采用了8中不同的颜色方式,主要是为了考虑场景以及光照条件等。这个策略主要应用于中图像分割算法中原始区域的生成。主要使用的颜色空间有:(1)RGB,(2)灰度I,(3)Lab,(4)rgI(归一化的rg通道加上灰度),(5)HSV,(6)rgb(归一化的RGB),(7)C(具体请看论文【2】以及【5】),(8)H(HSV的H通道)
2、相似度计算
-
颜色相似度
使用L1-norm归一化获取图像每个颜色通道的25 bins的直方图,这样每个区域都可以得到一个75维的向量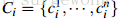
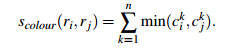
在区域合并过程中使用需要对新的区域进行计算其直方图,计算方法:
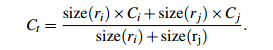
- 纹理相似度
这里的纹理采用SIFT-Like特征。具体做法是对每个颜色通道的8个不同方向计算方差σ=1的高斯微分(Gaussian Derivative),每个通道每个颜色获取10 bins的直方图(L1-norm归一化),这样就可以获取到一个240维的向量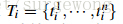
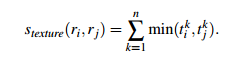
在区域合并过程中对新的区域进行计算其直方图和上面的一样。
- 优先合并小的区域
如果仅仅是通过颜色和纹理特征合并的话,很容易使得合并后的区域不断吞并周围的区域,后果就是多尺度只应用在了那个局部,而不是全局的多尺度。因此我们给小的区域更多的权重,这样保证在图像每个位置都是多尺度的在合并。
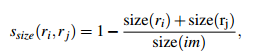
上面的公式表示,两个区域越小,其相似度越大。
- 区域的合适度距离
如果区域ri包含在rj内,我们首先应该合并,另一方面,如果ri很难与rj相接,他们之间会形成断崖,不应该合并在一块。这里定义区域的合适度距离主要是为了衡量两个区域是否更加“吻合”,其指标是合并后的区域的Bounding Box(能够框住区域的最小矩形BBij)越小,其吻合度越高。其计算方式:
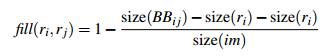
- 合并上面四种相似度
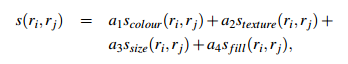
其中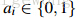
三 给区域打分
通过上述的步骤我们能够得到很多很多的区域,但是显然不是每个区域作为目标的可能性都是相同的,因此我们需要衡量这个可能性,这样就可以根据我们的需要筛选区域建议个数啦。
这篇文章做法是,给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2以此类推。但是当我们策略很多,多样性很多的时候呢,这个权重就会有太多的重合了,排序不好搞啊。文章做法是给他们乘以一个随机数,毕竟3分看运气嘛,然后对于相同的区域多次出现的也叠加下权重,毕竟多个方法都说你是目标,也是有理由的嘛。这样我就得到了所有区域的目标分数,也就可以根据自己的需要选择需要多少个区域了。
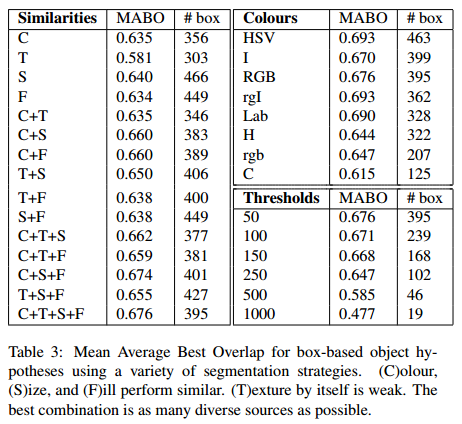
四 选择性搜索性能评估
自然地,通过算法计算得到的包含物体的Bounding Boxes与真实情况(ground truth)的窗口重叠越多,那么算法性能就越好。这是使用的指标是平均最高重叠率ABO(Average Best Overlap)。对于每个固定的类别 c,每个真实情况(ground truth)表示为 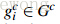
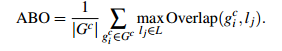
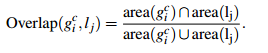
- 使用RGB色彩空间
- 采用四种相似度计算的组合方式
- 设置图像分割的阈值k=50
然后通过改变其中一个参数,获取MABO性能指标如下表: