上一篇文章介绍了Redis的主从复制原理
在做Master-Slave主从复制的时候,如果主服务器宕机,Redis无法实现主从切换。这时候就需要Redis提供的Sentinel系统。
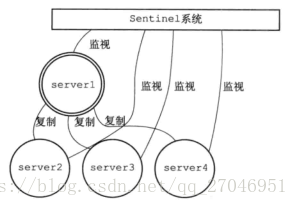
Sentinel是Redis高可用的解决方案。
Sentinel系统可以监视主服务器以及主服务属下的所有从服务器。
并且在主服务进入下线状态时,自动将主服务属下的某个从服务器自动升级
为主服务器。然后由新的主服务器来继续处理命令。
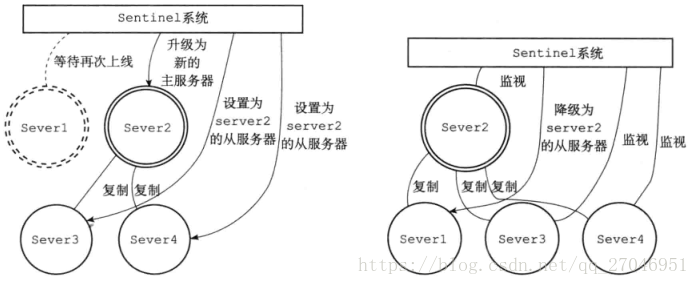
如果这时候主服务器server1下线,从服务器对主服务器的复制操作就会终止,Sentinel系统会察觉到主服务器已经下线。当主服务器server1下线时长超过设定的下线时长后,Sentinel系统会对server1进行故障转移。
1,Sentinel会挑选其中主服务器的其中一台从服务器升级为新的主服务器
2,对下线主服务器的所有从服务器发送新的复制指令,让他们成为新主服务器的
从服务器,当所有的从服务器复制新的主服务器后,完成故障转移
3,Sentinel还有继续监视下线的主服务器,并在它重新上线的时候,将它设置
为新主服务器的从服务器。
Sentinel的配置
在Redis的源码中包含了一个sentinel.conf文件作为sentinel的配置文件。
vim sentinel.conf
//只需要配置master的信息就好了,指定主服务器的host和port
//1代表,有1个Sentinel认为master死了,master就不可用了,会执行故障转移
sentinel monitor mymaster 127.0.0.1 6379 1
//端口 默认为26379
port 26379
dir "/usr/local/copyredis/redis6379/bin"
//每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel
//节点是否可达,如果超过30000毫秒且没有回复,则判定不可达
sentinel down-after-milliseconds mymaster 30000
//故障转移超时时间为180000毫秒
sentinel failover-timeout mymaster 180000启动Sentinel
将配置好的sentinel.conf文件放置在主服务器的bin目录下
[root@wxx bin]# ./redis-sentinel ./sentinel.conf 检测主观下线状态
默认情况下,Sentinel会以每秒一次的频率向所有与它创建连接的实例
(主服务,从服务器,其它Sentinel节点)发送PING
命令,通过PING命令的返回来判断是否在线
如果在配置的sentinel down-after-milliseconds mymaster 30000
在3000毫秒内,连续向Sentinel返回无效回复。那么Sentinel就认为该实例
已经主观下线。
需要注意的是,当多个Sentinel配置的 sentinel down-after-milliseconds值不相同时。
//Sentinel-1配置
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel down-after-milliseconds mymaster 10000
//Sentinel-2配置
sentinel monitor mymaster 127.0.0.1 6379 1
sentinel down-after-milliseconds mymaster 30000当master断线时长超过10000毫秒时,Sentinel-1认为master主观下线,而Sentinel-2却认为master仍然在线。只有当master断线30000毫秒时,Sentinel-1和Sentinel-2才都会认为master主观下线
检测客观下线状态
当Sentinel检测到主服务器主观下线之后,为了确认这个主服务器真的
已经主观下线,会向其他的Sentinel进行询问。当Sentinel从其他Sentinel
那里接收到足够数量的已下线判断后,就会判定主服务器为客观下线,
就会对主服务器进行故障转移
因为每个Sentinel设置的down-after-milliseconds时间可能不一样
客观下线状态的判断条件
Sentinel monitor mymaster 192.168.125.128 6379 2
当认为主服务器已经下线的sentinel数量超过sentinel配置中quorum参数的
值,就会认定主服务器为客观下线。
进行故障转移
先来看看当前的主从关系
127.0.0.1:6379> INFO REPLICATION
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=196752,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=196752,lag=1可以看到主服务器为127.0.0.1 6379,有两个从服务器
127.0.0.1 6380 和 127.0.0.1 6381
停止master主服务器
//找到主服务器6379的pid
ps -ef|grep redis
//再使用kill -9 pid杀死
kill -9 pid这时候Sentinel认为主服务master主观下线,就行故障转移
执行Sentinel masters命令可以看到从服务器127.0.0.1 6380已经升级为主服务器
127.0.0.1:26379> sentinel masters
1) 1) "name"
2) "mymaster"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6380"
7) "runid"
8) "2367e7d87ec13202bdaeaecfa1adcf748155cb56"在127.0.01 6380客户端发送INFO REPLICATION 中查看复制信息
127.0.0.1:6380> INFO REPLICATION
# Replication
role:master
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=15921,lag=0可以看到之前复制主服务127.0.0.1 6379的从服务器127.0.0.1 6381成为
新主服务器127.0.0.1 6380的从服务器。
这时候重新连接之前断线的主服务器127.0.0.1 6379
[root@wxx bin]# ./redis-server redis6379.conf
[root@wxx bin]# ./redis-cli -p 6379查看Sentinel监控的从节点信息
127.0.0.1:26379> sentinel slaves mymaster
1) 1) "name"
2) "127.0.0.1:6379"
3) "ip"
4) "127.0.0.1"
5) "port"
6) "6379"
7) "runid"
8) "80eb4e4dec82b79d25e91c102fef687616698538"
9) "flags"
10) "slave"可以看到,之前断线的主服务器127.0.0.1 6379重新上线后,成为新主服务器
127.0.0.1 6380的从服务器。
整个故障转移过程
选出新的主服务器
修改从服务器的复制目标
将重连后的旧的主服务器变为从服务器,并令其复制新选出的主服务器