原文地址:https://blog.csdn.net/shouhuzhezhishen/article/details/69221517
概述
Redis哨兵为Redis提供了高可用性。实际上这意味着你可以使用哨兵模式创建一个可以不用人为干预而应对各种故障的Redis部署。
哨兵模式还提供了其他的附加功能,如监控,通知,为客户端提供配置。
下面是在宏观层面上哨兵模式的功能列表:
- 监控:哨兵不断的检查master和slave是否正常的运行。
- 通知:当监控的某台Redis实例发生问题时,可以通过API通知系统管理员和其他的应用程序。
- 自动故障转移:如果一个master不正常运行了,哨兵可以启动一个故障转移进程,将一个slave升级成为master,其他的slave被重新配置使用新的master,并且应用程序使用Redis服务端通知的新地址。
- 配置提供者:哨兵作为Redis客户端发现的权威来源:客户端连接到哨兵请求当前可靠的master的地址。如果发生故障,哨兵将报告新地址。
哨兵的分布式特性
Redis哨兵是一个分布式系统:
哨兵自身被设计成和多个哨兵进程一起合作运行。有多个哨兵进程合作的好处有:
当多个哨兵对一个master不再可用达成一致时执行故障检测。这会降低错误判断的概率。
即使在不是所有的哨兵都工作时哨兵也会工作,使系统健壮的抵抗故障。毕竟在故障系统里单点故障没有什么意义。
Redis的哨兵、Redis实例(master和slave)、和客户端是一个有特种功能的大型分布式系统。在这个文档里将逐步从为了理解哨兵基本性质需要的基础信息,到为了理解怎样正确的使用哨兵工作的更复杂的信息(这是可选的)进行介绍。
哨兵自身被设计成和多个哨兵进程一起合作运行。有多个哨兵进程合作的好处有:
当多个哨兵对一个master不再可用达成一致时执行故障检测。这会降低错误判断的概率。
即使在不是所有的哨兵都工作时哨兵也会工作,使系统健壮的抵抗故障。毕竟在故障系统里单点故障没有什么意义。
Redis的哨兵、Redis实例(master和slave)、和客户端是一个有特种功能的大型分布式系统。在这个文档里将逐步从为了理解哨兵基本性质需要的基础信息,到为了理解怎样正确的使用哨兵工作的更复杂的信息(这是可选的)进行介绍。
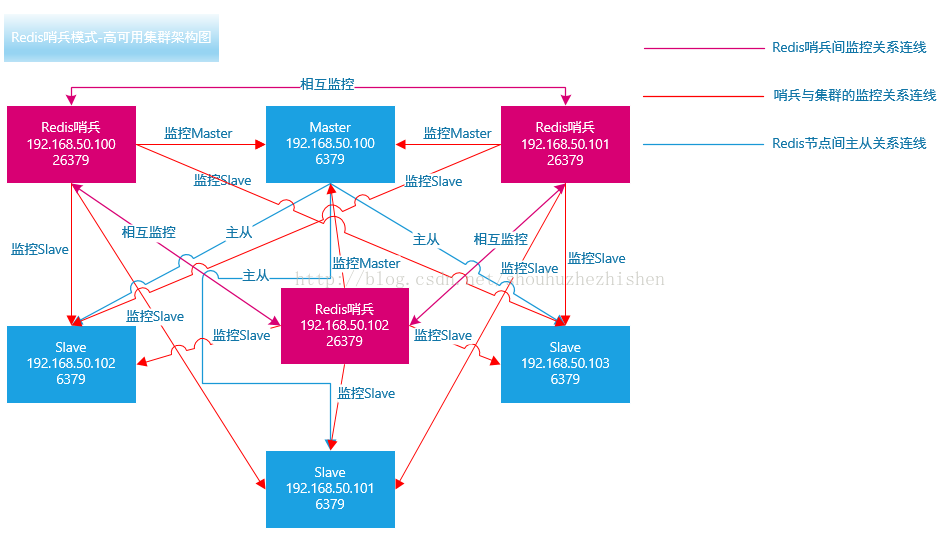
1、机器规划
集群架构图如下:
2、集群配置
- #后台启动
- daemonize yes
- pidfile "/home/redis/redis/redisRun/redis_6379.pid"
- port 6379
- timeout 0
- tcp-keepalive 0
- loglevel notice
- logfile "/home/redis/redislog/redis.log"
- databases 16
- save 900 1
- save 300 10
- save 60 10000
- stop-writes-on-bgsave-error yes
- rdbcompression yes
- rdbchecksum yes
- dbfilename "dump.rdb"
- dir "/home/redis/redisdb"
- #如果做故障切换,不论主从节点都要填写密码且要保持一致
- masterauth "123456"
- slave-serve-stale-data yes
- slave-read-only yes
- repl-disable-tcp-nodelay no
- slave-priority 98
- #当前redis密码
- requirepass "123456"
- appendonly yes
- # appendfsync always
- appendfsync everysec
- # appendfsync no
- no-appendfsync-on-rewrite no
- auto-aof-rewrite-percentage 100
- auto-aof-rewrite-min-size 64mb
- lua-time-limit 5000
- slowlog-log-slower-than 10000
- slowlog-max-len 128
- notify-keyspace-events ""
- hash-max-ziplist-entries 512
- hash-max-ziplist-value 64
- list-max-ziplist-entries 512
- list-max-ziplist-value 64
- set-max-intset-entries 512
- zset-max-ziplist-entries 128
- zset-max-ziplist-value 64
- activerehashing yes
- client-output-buffer-limit normal 0 0 0
- client-output-buffer-limit slave 256mb 64mb 60
- client-output-buffer-limit pubsub 32mb 8mb 60
- hz 10
- aof-rewrite-incremental-fsync yes
- # Generated by CONFIG REWRITE
Slave(192.168.50.101-103)机器配置如下:
- daemonize yes
- pidfile "/home/redis/redis/redisRun/redis_6379.pid"
- port 6379
- timeout 0
- tcp-keepalive 0
- loglevel notice
- logfile "/home/redis/redislog/redis.log"
- databases 16
- save 900 1
- save 300 10
- save 60 10000
- stop-writes-on-bgsave-error yes
- rdbcompression yes
- rdbchecksum yes
- dbfilename "dump.rdb"
- dir "/home/redis/redisdb"
- #主节点密码
- masterauth "123456"
- slave-serve-stale-data yes
- slave-read-only yes
- repl-disable-tcp-nodelay no
- slave-priority 98
- requirepass "123456"
- appendonly yes
- # appendfsync always
- appendfsync everysec
- # appendfsync no
- no-appendfsync-on-rewrite no
- auto-aof-rewrite-percentage 100
- auto-aof-rewrite-min-size 64mb
- lua-time-limit 5000
- slowlog-log-slower-than 10000
- slowlog-max-len 128
- notify-keyspace-events ""
- hash-max-ziplist-entries 512
- hash-max-ziplist-value 64
- list-max-ziplist-entries 512
- list-max-ziplist-value 64
- set-max-intset-entries 512
- zset-max-ziplist-entries 128
- zset-max-ziplist-value 64
- activerehashing yes
- client-output-buffer-limit normal 0 0 0
- client-output-buffer-limit slave 256mb 64mb 60
- client-output-buffer-limit pubsub 32mb 8mb 60
- hz 10
- aof-rewrite-incremental-fsync yes
- # Generated by CONFIG REWRITE
- #配置主节点信息
- slaveof 192.168.50.100 6379
- port 26379
- #1表示在sentinel集群中只要有两个节点检测到redis主节点出故障就进行切换,单sentinel节点无效(自己测试发现的)
- #如果3s内mymaster无响应,则认为mymaster宕机了
- #如果10秒后,mysater仍没活过来,则启动failover
- sentinel monitor mymaster 192.168.50.100 6379 1
- sentinel down-after-milliseconds mymaster 3000
- sentinel failover-timeout mymaster 10000
- daemonize yes
- #指定工作目录
- dir "/home/redis/sentinel-work"
- protected-mode no
- logfile "/home/redis/sentinellog/sentinel.log"
- #redis主节点密码
- sentinel auth-pass mymaster 123456
- # Generated by CONFIG REWRITE
Slave(192.168.50.100-102)机器配置同上
注意:以上配置中不存在的文件路径需要手动创建。哨兵可配置多个,最好是最少3个节点,配置相同。
- redis-server /home/redis/redis/redis.conf
在192.168.50.100启动Redis哨兵节点命令如下:
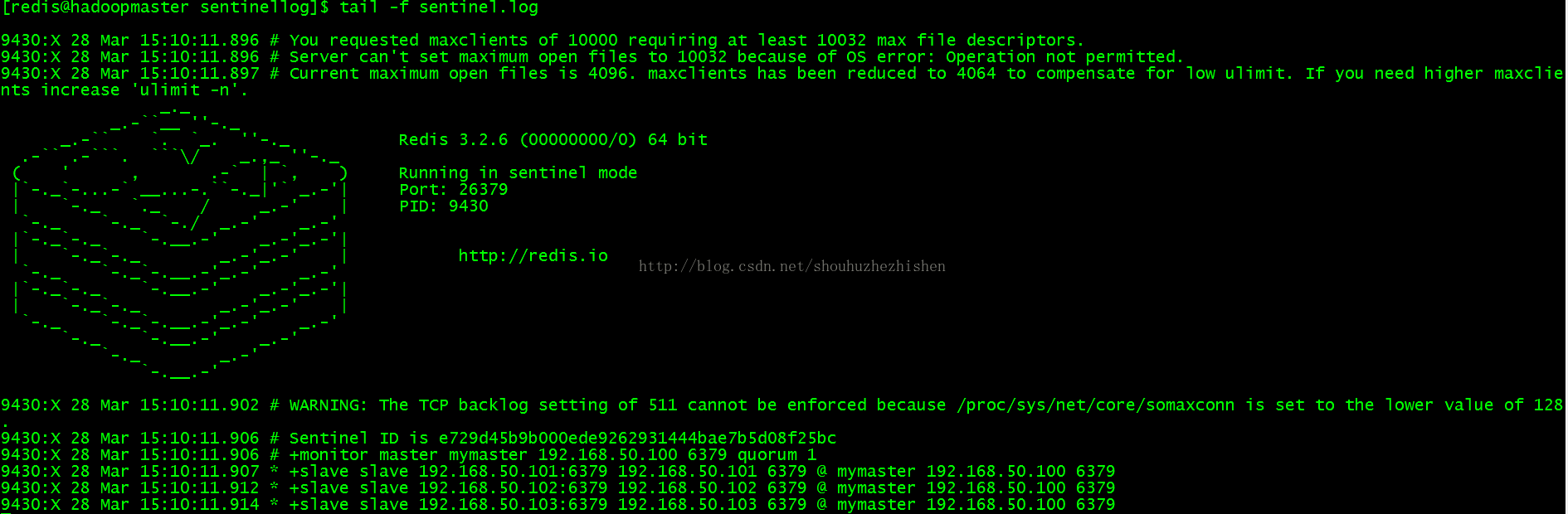
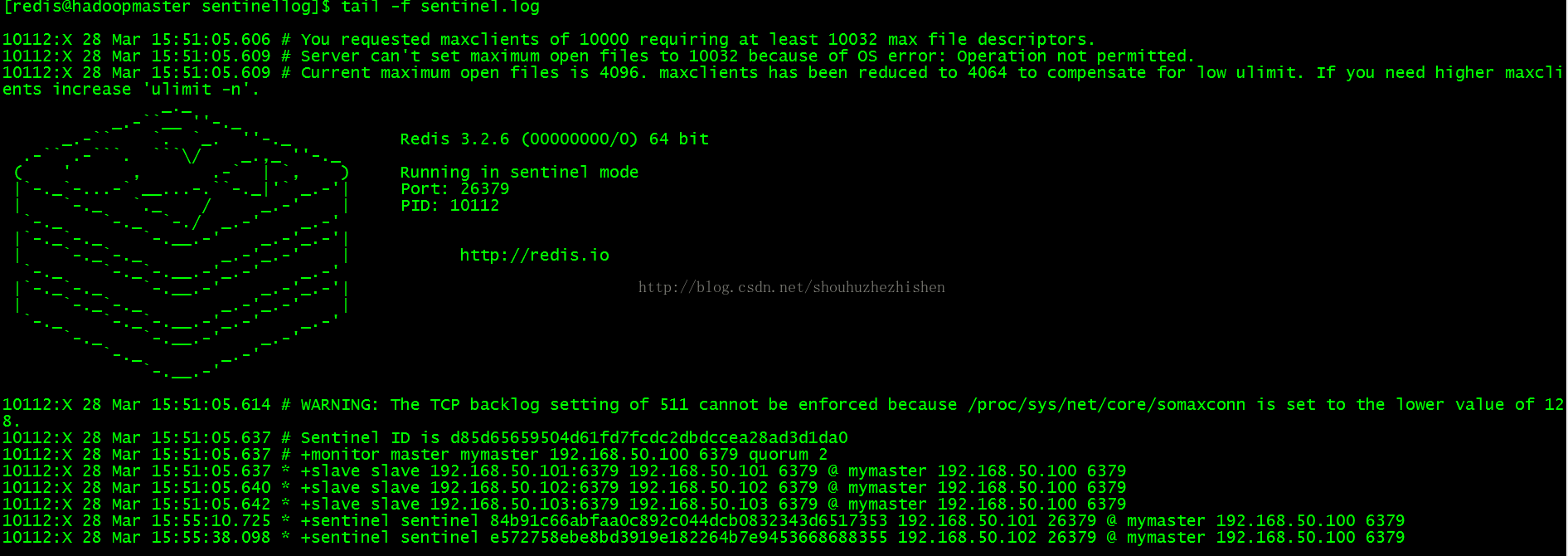
集群多节点节点启动日志截图如下:
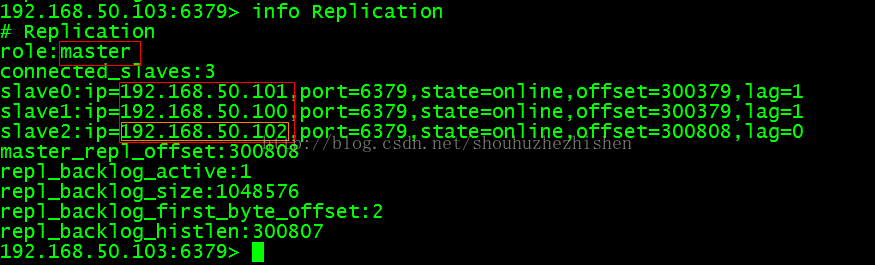
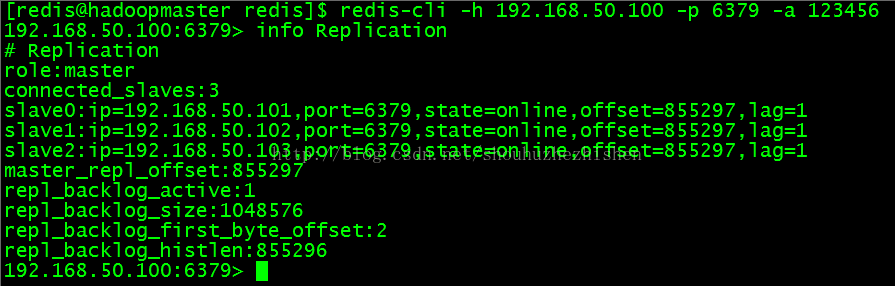
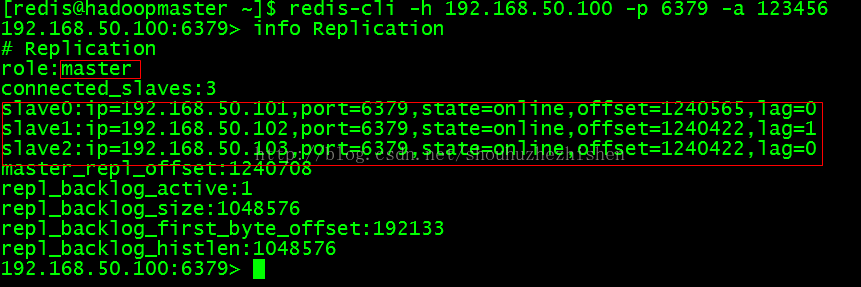
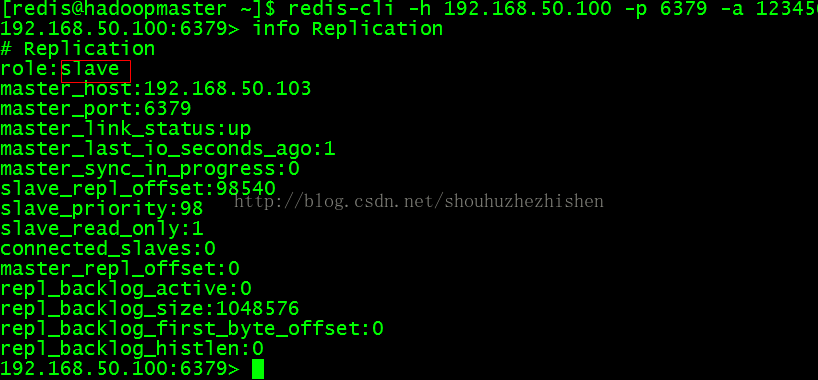
4.2、登录Master(192.168.50.100)的redis查看Master的情况:
执行登录命令如下:
- redis-cli -h 192.168.50.100 -p 6379 -a 123456
列出Master的信息:
- info Replication
效果如图:
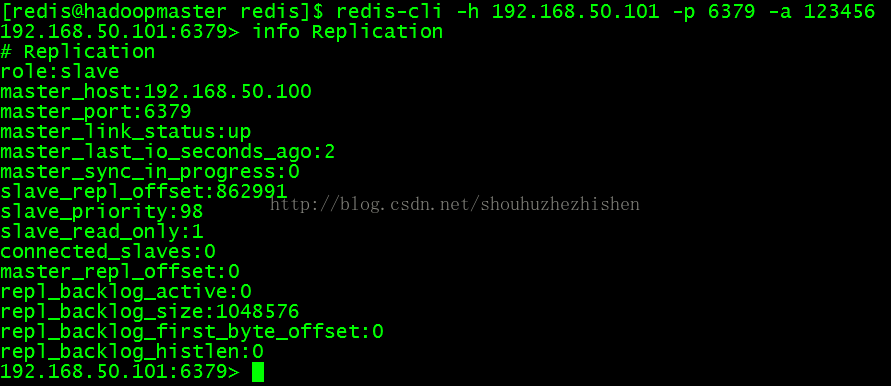
- redis-cli -h 192.168.50.101 -p 6379 -a 123456
列出Slave的信息:
- info Replication
效果如图:
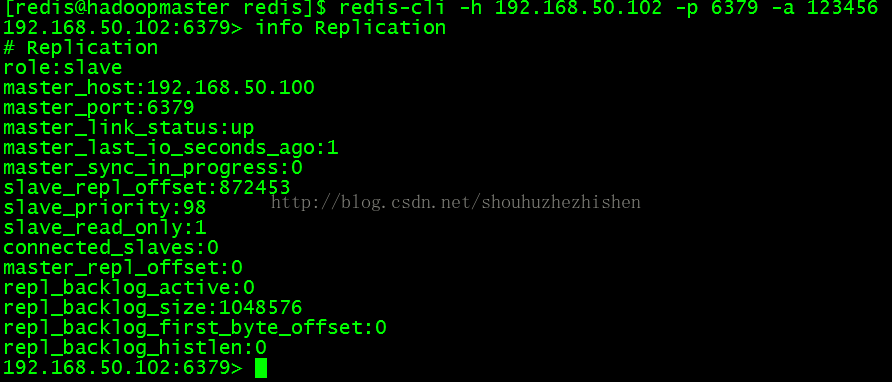
- redis-cli -h 192.168.50.102 -p 6379 -a 123456
列出Slave的信息:
- info Replication
效果如图:
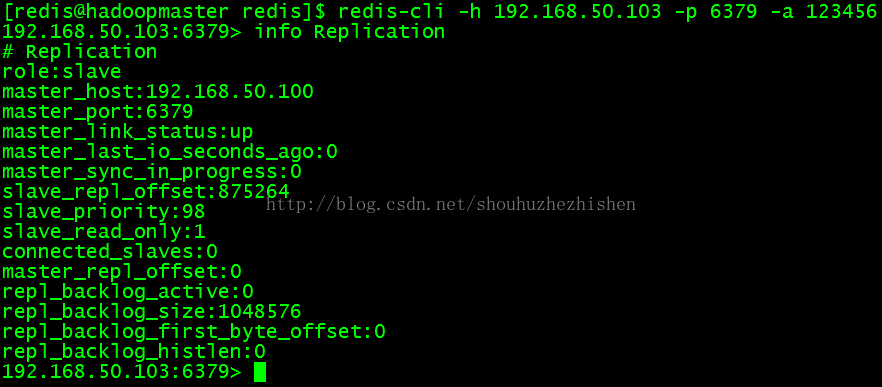
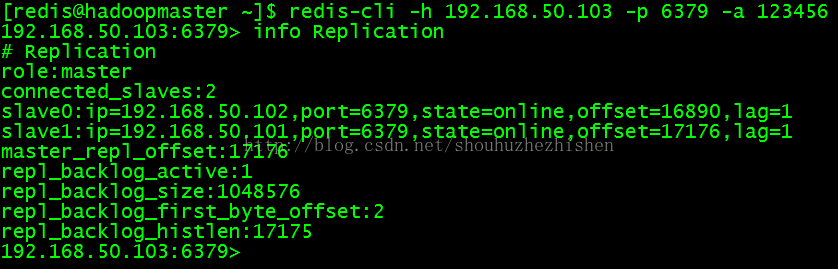
4.5、登录Slave(192.168.50.103)的redis查看Slave的情况:
执行登录命令如下:
- redis-cli -h 192.168.50.103 -p 6379 -a 123456
列出Slave的信息:
- info Replication
效果如图:
5、场景测试
5.1、场景1:master宕机
master-sentinel作为master 1的leader,会选取一个master 1的slave作为新的master。slave的选取是根据一个判断DNS情况的优先级来得到,优先级相同通过runid的排序得到,但目前优先级设定还没实现,所以直接获取runid排序得到slave 1。然后发送命令slaveofno one来取消slave 1的slave状态来转换为master。当其他sentinel观察到该slave成为master后,就知道错误处理例程启动了。sentinel A然后发送给其他slave slaveof new-slave-ip-port 命令,当所有slave都配置完后,sentinelA从监测的masters列表中删除故障master,然后通知其他sentinels。现在192.168.50.100:6379是master,192.168.50.101:6379、192.168.50.102:6379和192.168.50.103:6379是salve。
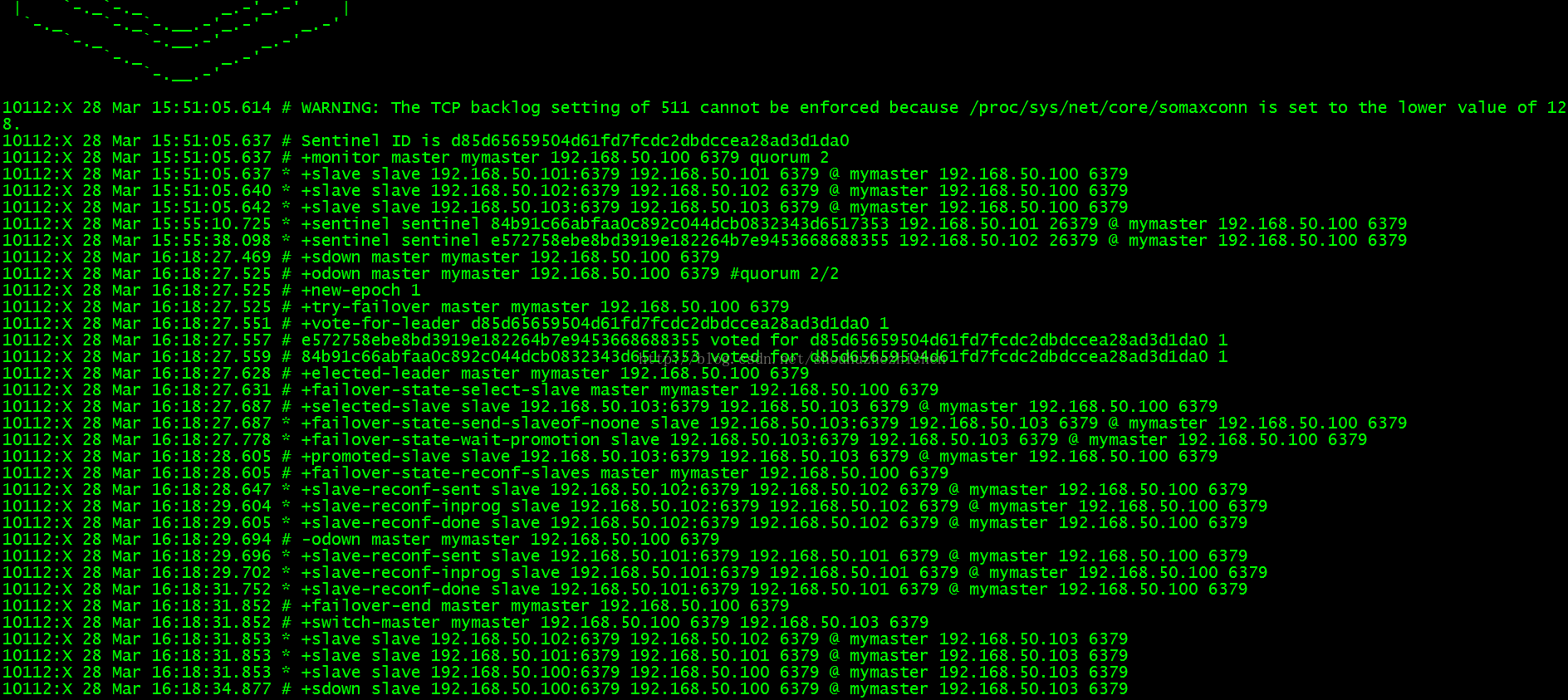
关闭master(192.168.50.100)后观察选举新的master的过程:
显示了failover的过程:
显示了failover的过程:
选择192.168.50.103:6379为master:
- redis-server /home/redis/redis/redis.conf
查看Sentinel日志信息:
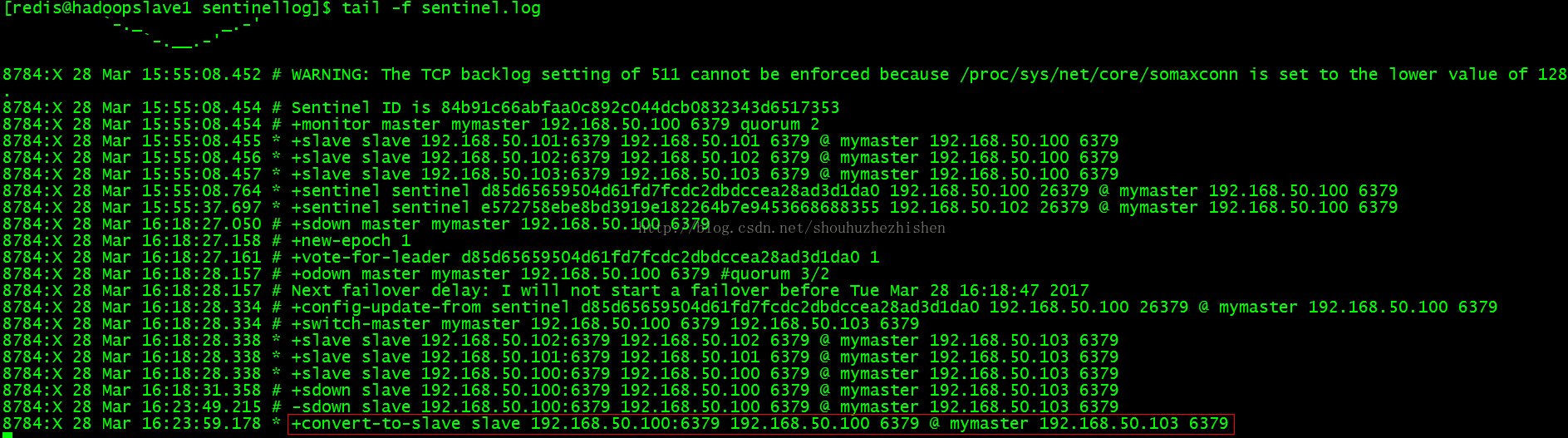
原来的master自动切换成slave,不会自动恢复成master。
5.3、场景3:任意一个Slave宕机(这里用192.168.60.102:6379作为测试)
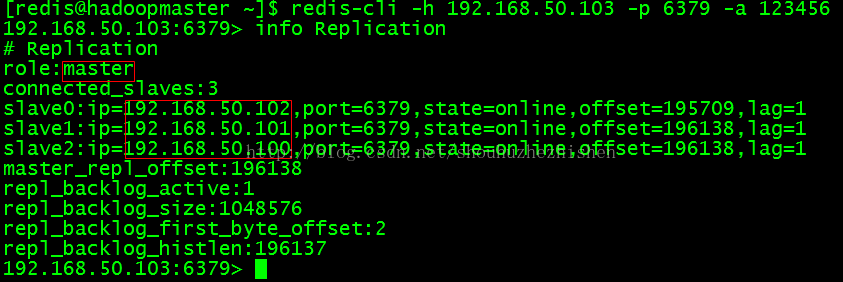
现在192.168.50.103:6379是master,192.168.50.100:6379、192.168.50.101:6379和192.168.50.102:6379是salve。
关闭Slave(192.168.50.102)后查看Sentinel日志信息:
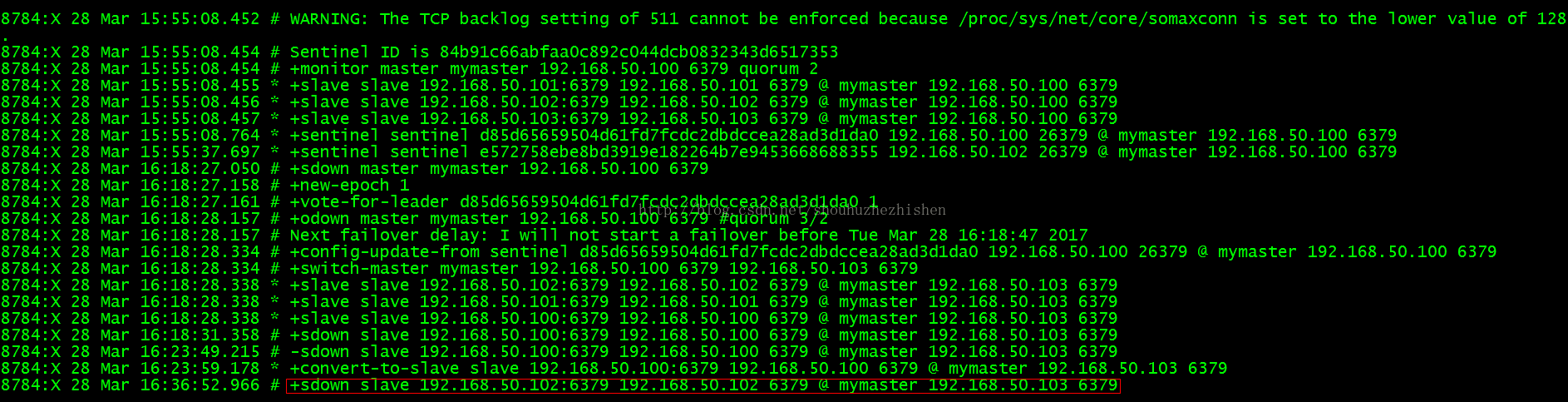
此时Slave已经sdown
查看Master的Replication信息:
查看Master的Replication信息:
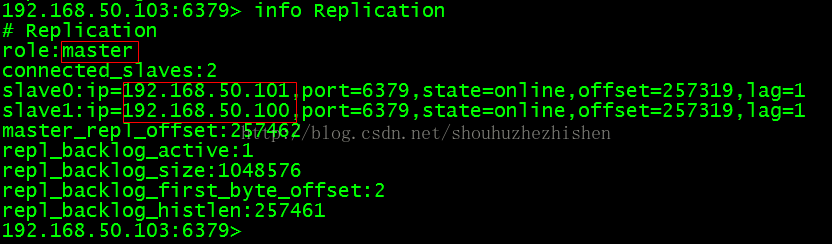
此时只存在两个个slave。
- redis-server /home/redis/redis/redis.conf
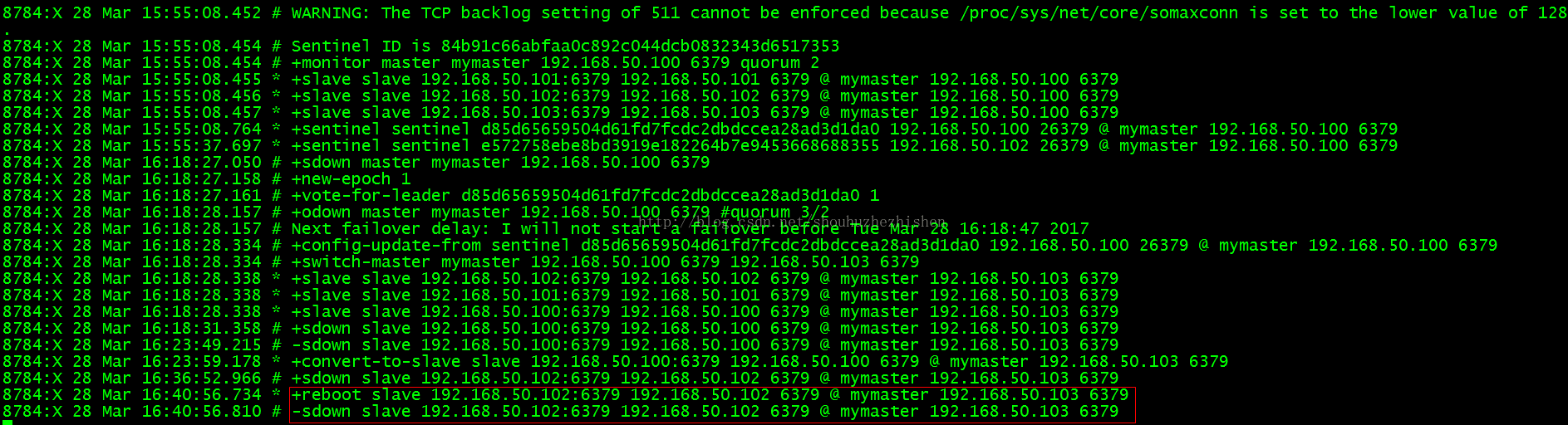
查看master的Replication信息: