一个简单的手写数字分类网络
接上一篇文章,我们定义了神经网络,现在我们开始手写体的识别。我们可以将识别手写数字这个问题划分为两个子问题,一,我们需要将一幅包含了许多数字的图像分解为一系列独立的图像,每一幅图像包含了一个数字。比如,我们需要把下图分解:
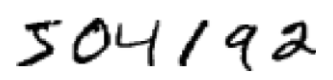
将该图分解为6幅独立的图像:

我们人可以很轻松的将其分开,但是计算机可不那么认为。一旦图片被分割后,程序需要将每个数字单独识别。因此,举个例子,我们想要我们的程序可以识别上图中的第一个数字为5。
这里我们致力于解决第二个问题,就是对单一数字的分类。因为对于第一个分割问题,这里有许多方法可以解决了。因此,与其关⼼分割问题,我们不如把精⼒集中在设计⼀个神经⽹络来解决更有趣、更困难的问题,即⼿写数字的识别。
为了识别单个数字,我们将用到三层神经网络:
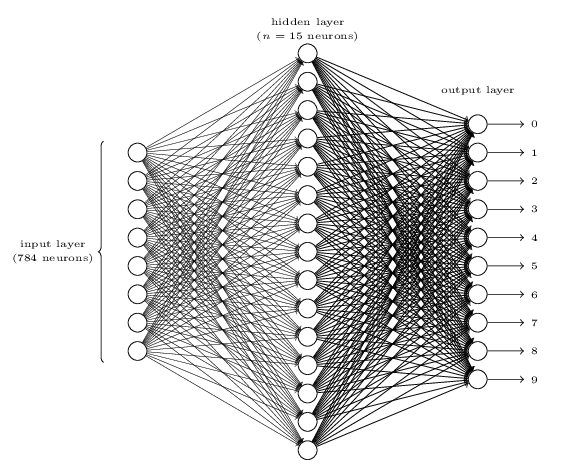
网络的输入层包含了对输入像素值编码的神经元。正如后面讨论的,我们的训练数据有许多28X28的手写数字的像素图组成,也就是说我们的输入层包含了28X28=784个神经元,一个神经元对应一个像素位的值。输入的像素值为灰度值,0.0表示白色,1.0表示黑色,0到1之间的值表示不同程度的灰色。
网络的第二层为隐藏层,我们记隐藏层的神经元数量为n,我们将对n的取值进行实验。这个图例中展示了一个小的隐藏层,它的隐藏层只有15个。
网络的输出层包含了10个神经元。如果第一个神经元被激活,也就是输出值无限接近1,那么我们可以认为这个网络识别出来的数字是0.如果是第二个神经元激活,那么识别出来的数字为1。更准确的说,我们将对输出神经元从0到9编号,然后找出激活值最高的神经元。如果编号为6的神经元激活值最高,那么我们认为输入的数字为6。
这里使用是个输出神经元很现实是为了对应输出的十种可能性。一种看起来更自然的方法是使用4个输出神经元,每一个神经元看作一个二进制数,结果取决于改神经元输出更靠近0还是更靠近1。4个输出神经元对于10个数字来说已经足够了,毕竟
为了理解为什么要这样做,了解神经网络的工作的基本原理是很有帮助的。首先考虑我们使用10个输出神经的情况。让我们把目光放在第一个输出神经上,该神经决定了是否该数字是0。它是通过权衡隐藏层所输出的信息做出判断的。那么隐藏层的神经元做了些什么呢?假设隐藏层的第一个神经元是为了检测图像中是否存在如下图形:

它是通过对输入图像中与该图形重合的像素赋予很大的权值,而其他部分赋予很小的权值来判断的。以同样的方式,我们假设第二个第三个第四个神经元分别是为了探测图像中是否存在以下图形:

可能你已经看出来上面四个图形可以组成数字0:

因此,如果隐藏层的这四个神经元都被激活,那么我们可以认为这个图像上的数字是0。当然这不是我们用来推断数字为0的唯一组合,我们可以通过诸多图形组合得到0(比如将上图进行扭曲变形,但它还是0)。但至少在这个例子中,我们可以推断出输入数字是0。
如果神经网络是这样工作的,那么我们似乎可以给出一个对为什么使用10个输出神经而不是4个这件事一个合理的解释。如果是4个输出神经元,那么,我们的第一个输出神经元将用于判断该数字对应二进制的最高有效位是什么,然而,我们很难将图形和数字的最高有效位对应起来。
上面说了这么多都只是一个启发性的方法,没人说三层神经网络必须按照我上面所说的方式去工作,即每个隐藏层的神经元去探测一个简单的图像组成部分。也许一些聪明的学习算法会找到一些权重分配让我们使用4个输出神经元。但是作为一种启发,我所描述的方法可以工作的很好,这可以让你节省许多时间在设计神经网络的结构上。
使用梯度下降算法进行学习
现在我们已经设计出了一个神经网络,那么我们如何使用它去学习识别数字呢。首先,我们需要一个数据集去学习,我们使用的是MNIST数据集,它包含了数以万计的手写数字的扫描图像,以及他们的正确分类。下图是取值MNIST的几个图像:
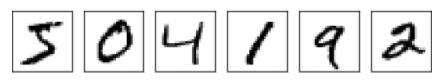
正如你所见,这些数字和上一篇文章的数字是一样,当然我们需要我们的网络可以识别不在数据集中的图像。
MNIST数据集包含两个部分,第一个部分包含了60000张图片被用作训练数据。这些通过扫面250个人的手写数字获得,其中有些是美国人口普查局的员工,有些是高中生。这些图像是28X28的灰度图。数据集的第二部分是10000张图片被用来测试,与训练数据的格式一样。我们将使用测试数据衡量我们的神经网络学习得怎么样。当然第二部分的图片是另外250个人的手写样本,这有可以让我们证实网络可以识别不在训练集中的人的手写数字。
我们用
我们想有这样一个算法,它可以让我们找到权重和偏差,这样网络的输出
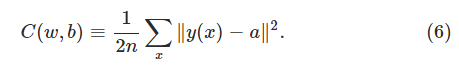
其中
为什么要介绍二次代价函数?我们不应该关注于图像的正确分类的数量上面吗?为什么不尝试直接最大化正确分类的数量而是要使用最小化一个二次代价函数来简介评测呢?这是因为正确分类图像的数量对于权重和偏差来说不是一个平滑的函数,那么在大多数情况下,对权重和偏差的微小改变不会造成目标函数即正确分类数量的值的改变,这让我们很难找到通过改变权重和偏差提高性能的方法。如果我们使用一个像二次代价函数这样的平滑函数,那将很容易找到通过改变权重和偏差来提高性能的方法。这就是我们为什么专注于最小化二次代价,因为只有这样,我们才能测试分类的准确性。
那么可能你又会好奇为什么要选择式(6)那样的二次函数来作为平滑函数呢?这时临时想出来的么?可能如果我们选择另外一个不一样的代价函数,我们将会得到不同的代价最小时的权重和偏差。这个疑问是有必要的,稍后我将对上面的成本函数再次进行讨论,并作一些修改。然而式(6)中的代价函数对于我们理解神经网络的基础很有帮助,所以我们将一直使用它。
重申一次,我们的目标是训练一个神经网络,找到权重和偏差使得二次代价函数
OK,现在假设我们尝试最小化某些函数,
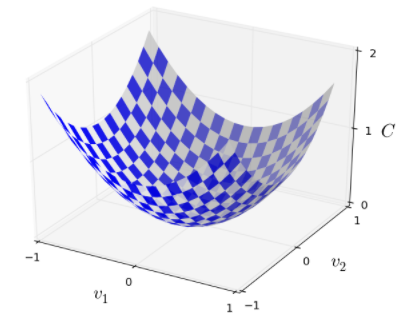
我们想要找到使
解决这个问题的一种方法是使用微积分的方法。我们将计算函数
现在微积分是不能解决最小值的问题了。幸运的是,有一种漂亮的推导法暗示有一种算法可以很好的解决问题。首先我们把函数想象成山谷,向上面那幅图画一样。然后我们假设有一个球从山谷上沿斜坡滚下,常识告诉我们这颗球会滚落到山谷底部。也许我们可以使用这样一个想法去寻找函数的最小值。开始我们把球随机放置在一个位置,然后模拟球从该点滚落到谷底这一过程。我们可以通过计算C的导数(和一些二阶导数)来简单模拟——这些导数将告诉我们这个山谷的一切局部形状,然后我们就知道这个球该怎么滚落了。
说了这么多,你可能会以为接下来我将介绍牛顿定理,摩擦力和重力对球体的影响。事实上,我们只是做了一个假设,并不是真的要用这个球的运动来寻找最小值。提到球只是用来激发我们的想象力,而不是束缚我们的思维。因此与其陷进物理学⾥凌乱的细节,不如我们就这样问⾃⼰:如果我们扮演⼀天的上帝,能够 构造⾃⼰的物理定律,能够⽀配球体可以如何滚动,那么我们将会采取什么样的运动学定律来 让球体能够总是滚落到⾕底呢?
为了使这个问题更明确,让我们讨论当我们将球在
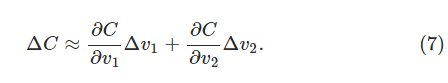
我们需要找到一种方法,找到一个
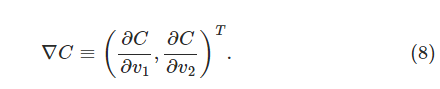
后面我们将会用
有了这些定义,(7)式中的

这个等式帮助我们理解为什么

其中

然后我们再一次使用这个更新规则,就可以计算它下一次下降的位置。如果我们一直这样做,
总结一下,我们使用的梯度下降算法的工作就是重复计算梯度
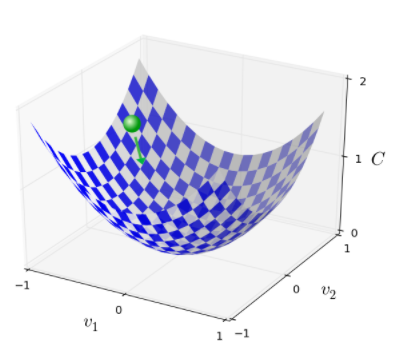
注意到梯度下降规则并不满足真实的物理规则。在真实世界中,球有动量,动量可能允许它偏移斜坡,甚至向上滚。只有在摩擦力的影响下它才可能滚到山谷。相比之下,我们选择
为了使梯度下降正确地工作,我们需要选择一个足够小的学习速率
我已经解释过当

其中梯度
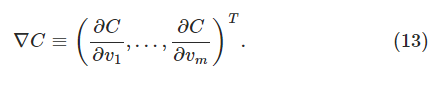
和前面的两个变量时的情况一样,我们可以选择:

我们保证我们的近似表达式(12)的值也将是负值。这将是我们可以在

你可以认为这个更新规则就是我们的梯度下降算法。它提供了重复改变位置
的确,在这种情况下,梯度下降是寻找最小值的最优策略。假设我们尝试移动
人们已经研究了梯度下降的许多变化形式,包括一些更接近真实的球的物理运动的形式。这种模拟球的形式有许多优点,但是也有一个重大的缺点:它最终必须计算
我们如何将梯度下降算法应用到一个神经网络?其思想是,使用梯度下降算法找到权重
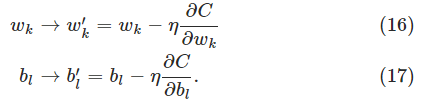
通过迭代使用这个更新规则,我们可以“滚下山谷”,找到期望的最小的代价函数。换句话说,这个规则可以用来学习神经网络。
在应用梯度下降时有许多挑战,我们将在后面的深入探讨这个问题。现在,我仅仅关注一个问题,在提出问题之前,我们先回顾一下公式(6)中的二次代价函数。这个代价函数有着
有一种叫做随机梯度下降的方法可以用来加速学习。这个思想就是通过随机选取小的训练样本来计算

其中第二个求和公式是对所有的训练样本而言。通过上式我们得到:
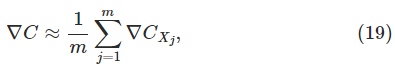
也就是我们可以通过计算样本大小为
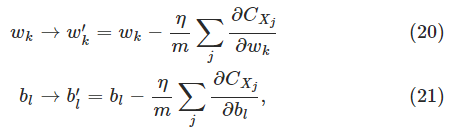
其中两个求和符号是在随机选取的小批量的训练样本上进行的。然后我们使用另一组随机的训练样本去训练,以此类推,直到我们用完了所有的训练输入,这样被称为一个训练迭代期。然后我们会开始一个新的训练迭代期。
另外,对于改变代价函数⼤⼩的参数,和⽤于计算权重和偏置的⼩批量数据的更新规则,会有不同的约定。在等式(6)中,我们通过因子
实现我们的数字分类网络
现在我们准备开始用代码通过随机梯度下降和MNIST训练集实现我们的识别网络。我们将使用python(2.7)来实现,仅仅74行代码!首先我们需要获得MNIST数据集,如果你使用git,你可以通过克隆代码库来获取:
git clone https://github.com/mnielsen/neural-networks-and-deep-learning.git
如果你不使用git也可以点击这里来获取数据和源码。
顺便提一下,之前我说MNIST数据集被分成了60000个训练图像和10000个测试图像,那是官方的描述。事实,我们将对这些数据做一些不同的划分。我们将对60000个MNIST训练集分成两部分,其中50000作为训练集,另外10000作为检验集。在这里我们先不会使用检验数据,但是在后面我们将会发现它对于神经网络中一些如学习速率这样的超参数的设置很有用,这些超参数不是学习算法所决定的。景观验证数据不是原始MNIST的规范,但是许多人都这样使用MNIST数据集,并且在神经网络中使用验证数据是很普遍的。从现在开始我们提到的MNIST训练数据指的是50000张训练图像而不是原始的60000张图像。
除了MNIST数据集以外,我们还需要python中的Numpy包,用于快速线性代数运算。
在列出一个完整的代码清单之前,让我先解释一下神经网络代码的核心特性。核心是一个Network类,用来表示神经网络,下面是初始化网络Network类的代码:
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]在这个代码中,list对象sizes包含了各层中神经元的数量。比如,你想创建一个第一层有2个神经元,第二层3个神经元,第三次1个神经元的网络,你可以这样创建类对象:
net = Network([2, 3, 1])网络对象中的偏差和权重是初始化为随机值,使用Numpy包中的np.random.randn函数来产生均值为0,标准差为1的⾼斯分布。这个随机初始化也就是我们使用随机梯度下降算法的一个起点。后面我们将讨论其他初始化权重和偏差的方法。注意,Network初始化代码中是假定第一层为输入层的,并且对这些神经元不设置任何偏差,因为偏差仅仅被用于后面层输出的计算。
另外偏差和权重以Numpy矩阵列表的形式存储。因此,net.weights[1]是一个存储着链接第二层和第三层神经元权重矩阵。由于net.weights[1]写起来很冗长,我们就用

我们需要一块一块地来解释这个方程。
有了这些知识,很容易写出从Network计算输出的代码实例,我们从定义sigmoid函数开始:
def sigmoid(z):
return 1.0/(1.0+np.exp(-z))注意到当参数z是一个向量或者Numpy数组时,Numpy自动的对向量中每一个元素应用sigmoid函数。
让后我们添加feedforward方法在Network类中,它对于网络给定输入a,返回对应的输出,这个方法是对每一层应用方程(22):
def feedforward(self, a):
"""Return the output of the network if "a" is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a的确,我们想要Network对象做的主要事情是学习。我们用SGD函数来实现随机梯度下降算法。下面是代码,有些地方比较神秘,我会在代码后面逐个分析。
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""Train the neural network using mini-batch stochastic
gradient descent. The "training_data" is a list of tuples
"(x, y)" representing the training inputs and the desired
outputs. The other non-optional parameters are
self-explanatory. If "test_data" is provided then the
network will be evaluated against the test data after each
epoch, and partial progress printed out. This is useful for
tracking progress, but slows things down substantially."""
if test_data: n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)training_data 是⼀个 (x, y) 元组的列表,表⽰训练输⼊和其对应的期望输出。变量 epochs 和mini_batch_size 正如你预料的 —— 迭代期数量,和采样时的⼩批量数据的⼤⼩。eta 是学习速率,η。如果给出了可选参数 test_data,那么程序会在每个训练器后评估⽹络,并打印出部分进展。这对于追踪进度很有⽤,但相当拖慢执⾏速度。
update_mini_batch代码如下。在每一次迭代期,先随机排列训练样本,然后将它分成适当大小的小批量数据。这是一个简单的从训练样本随机采样的数据。然后对每一个小批量数据应用一次梯度下降。它仅仅使⽤ mini_batch 中的训练数据,根据单次梯度下降的迭代更新⽹络的权重和偏置:
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The "mini_batch" is a list of tuples "(x, y)", and "eta"
is the learning rate."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]大部分的工作有下面这行代码完成:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)这行调用了一个称为反向传播的算法,可以快速的计算代价函数的梯度。因此update_mini_batch 的⼯作仅仅是对 mini_batch 中的每⼀个训练样本计算梯度,然后适当地更新 self.weights 和 self.biases。
我现在不会列出 self.backprop 的代码。我们将在后面学习反向传播是怎样⼯作的,包括self.backprop 的代码。现在,就假设它按照我们要求的⼯作,返回与训练样本
测试:

首先创建三个py文件,第一个用来读取数据,第二个用来学习,第三个就是调用上面两个文件中的函数。
源码下载地址:
手写数字分类网络源码
可以看到参数选取为:

即迭代30次,小批量数据大小为3,学习速率为3.0时的准确率如图:
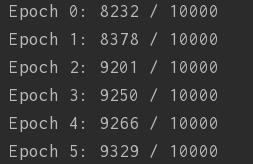
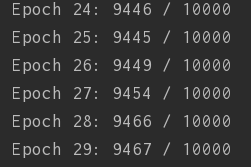
准确率达到了94.67%。
我们还可以通过自己生成一张手写数字的图片,测试一下结果,下面的图片是我通过画板自己画的:


我们可以通过改变神经网络隐藏层的神经元数量,或者学习速率,或者小批量数据大小来改变识别准确率。这些参数的选取,调试都是神经网络构造过程中重要的步骤。后面将会继续学习,下一篇文章将会讲到上面没有解释的backprop()函数,即反向传播算法。
参考原文:http://neuralnetworksanddeeplearning.com/chap1.html#a_simple_network_to_classify_handwritten_digits
以上是作者对原文的翻译和理解,有不对的地方请指正。
注:转载请注明原文出处:
作者:CUG_UESTC
出处:http://blog.csdn.net/qq_31192383/article/details/77198870