版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u011240016/article/details/85138172
直接先用前面设定的网络进行识别,即进行推理的过程,而先忽视学习的过程。
推理的过程其实就是前向传播的过程。
深度学习也是分成两步:学习 + 推理。学习就是训练模型,更新参数;推理就是用学习到的参数来处理新的数据。
from keras.datasets.mnist import load_data
import pickle
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 防止溢出型
def softmax(x):
c = np.max(x)
exp_x = np.exp(x - c)
sum_exp_x = np.sum(exp_x)
return exp_x / sum_exp_x
def get_data():
(X_train, y_train), (X_test, y_test) = load_data()
return X_test.reshape(10000, 784), y_test
def init_network():
# https://github.com/Bingyy/deep-learning-from-scratch/blob/master/ch03/sample_weight.pkl
with open('sample_weight.pkl', 'rb') as f:
network = pickle.load(f)
return network
# 存储的是网络参数字典
network = init_network()
# 组合网络流程,用于预测
def predict(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x,W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = softmax(a3) # 分类用的最后输出层的激活函数
return y
# 使用网络预测
X_test, y_test = get_data() # 得到测试数据
network = init_network()
accuracy_cnt = 0
for i in range(len(X_test)):
y = predict(network, X_test[i])
p = np.argmax(y)
if p == y_test[i]:
accuracy_cnt += 1
print('准确率:', str(float(accuracy_cnt) / len(X_test)))
# 准确率: 0.9207
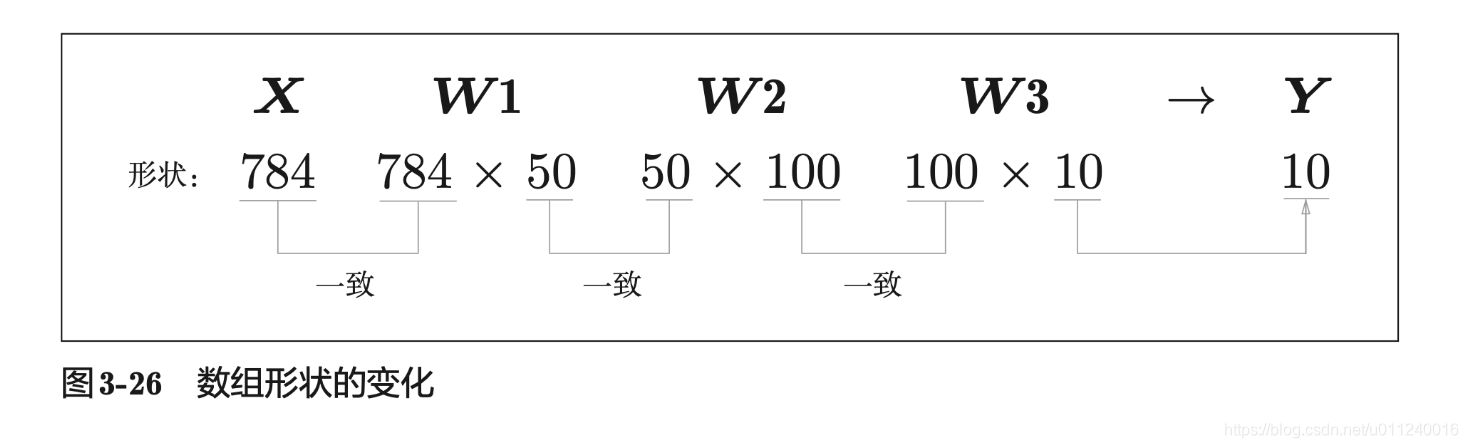
这里用到的网络还是三层网络,只是第一个隐藏层有50个神经元,第二个隐藏层有100个神经元,参数是作者提供的已经训练好的网络权重。本篇的目的是为了熟练使用已经训练好的模型。
网络对应的数组结构
要点总结:
- 使用
keras提供的load_data加载mnist数据 - 使用
pickle加载保存的网络权重 - 基于权重组建全连接网络
- 使用网络进行数据预测,并统计正确率
上面是一次读取一张图片,如果批量处理是如何进行的呢?
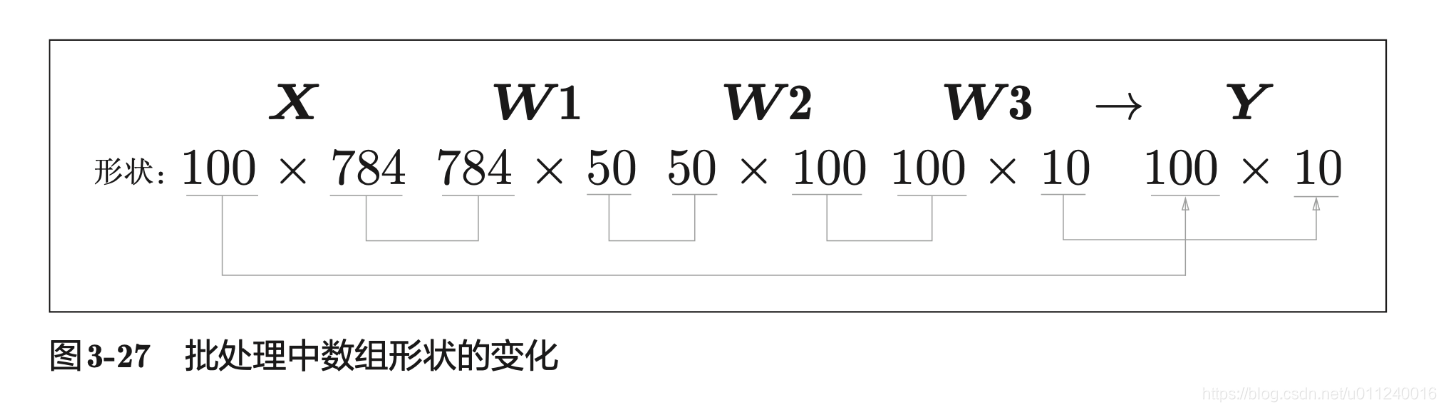
X_test, y_test = get_data() # 得到测试数据
network = init_network()
batch_size = 100
accuracy_cnt = 0
for i in range(0, len(X_test), batch_size):
x_batch = X_test[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == y_test[i:i+batch_size])
print('准确率:', str(float(accuracy_cnt) / len(X_test)))
这里只是如何取数据有变化,然后预测时还是用原来的predict函数。
另外,这里再讲一下轴的问题:
x = np.array([[0.1, 0.8, 0.1], [0.3, 0.1, 0.6], [0.2, 0.5, 0.3], [0.8, 0.1, 0.1]])
y = np.argmax(x, axis=1) # array([1, 2, 1, 0])
取出的是每一行的最大值下标。
扫描二维码关注公众号,回复:
4769287 查看本文章

END.
参考:
《深度学习入门:基于Python的理论与实现》