前言
为了能够解决感知机人工设定权重的工作,即确定合适的、能符合预期的输入与输出的权重,神经网络便出现了,神经网络的一个重要的性质是它可以自动地从数据中学习得到合适的权重参数。
神经网络
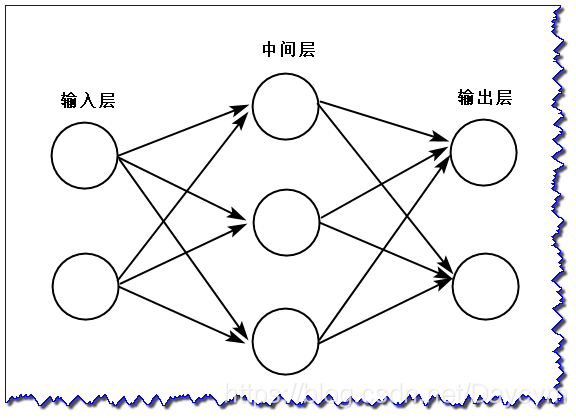
如上图,我们把最左边的一列称为输入层,最右边的称为输出层,中间的称为中间层(也可称为隐藏层),一般情况下,我们通常将输入层、隐藏层、输出层的总数减去1后的数量来表示神经网络的名称,上图即可称为两层神经网络。
从图上看,神经网络的形状与感知机很类似,实际上,就神经元的连接方式与感知机并没有差别。
感知机
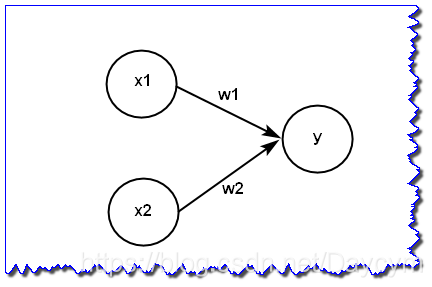
图中感知机接收
和
两个输入信号,输出
。用数学表达式可表示为(图中偏置项没画出来):
称为偏置,用于控制神经元被激活的容易程度; 和 表示各个信号的权重参数,用于控制各个信号的重要性。
进一步,我们可以引入一个新函数 ,将上面的式子改写为:
输入信号的总和会被函数 转换,转换后的值就是输出 。
激活函数
在前面,我们提到函数 会将输入信号的总和转换为输出信号,这种函数就叫激活函数。

我们先将式子改写为:
画出如下图:
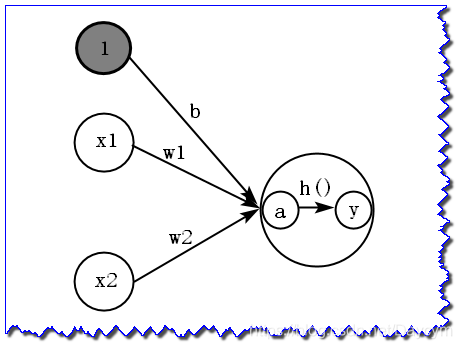
上面的激活函数 是以阀值为界,一旦输入超过阀值,就切换输出。这样的激活函数为“阶跃函数”,因此,可以说感知机中使用热阶跃函数作为激活函数,那么感知机使用其他激活函数呢?实际上,如果将激活函数从阶跃函数换成其他的,就可以进入神经网络的世界了。
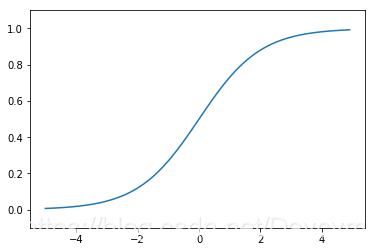
- sigmoid函数
数学表达式为:
python实现:
import numpy as np
import matplotlib.pylab as plt
def sigmoid(x):
return 1 / (1 + np.exp(-x))
x = np.arange(-5.0, 5.0, 0.1)
y = sigmoid(x)
# 画图
plt.plot(x,y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()
- 阶跃函数
数学表达式:
python实现:
# 方法一
def step_function1(x):
if x > 0:
return 1
else:
return 0
# 方法二
def step_function2(x):
return np.array(x>0, dtype=np.int)
x = np.arange(-5.0, 5.0, 0.1) # 在-0.5到0.5的范围内,以0.1为单位,生成NumPy数组([-5.0,-4.9,...,4.9])
y = step_function2(x)
plt.plot(x,y)
plt.ylim(-0.1, 1.1) # 指定y轴的范围
plt.show()
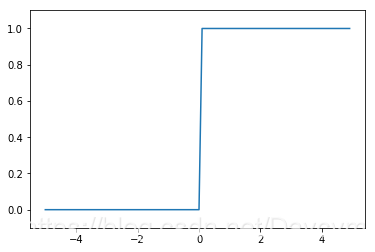
- 阶跃函数与sigmoid函数的比较
- “平滑性”不同,sigmoid函数是一条平滑的曲线,而阶跃函数在0处有突变,输出发生急剧性变化,sigmoid函数的平滑性对神经网络的学习具有重要意义;
- 返回值的不同,阶跃函数只能返回0和1,sigmoid函数可以返回0到1的任意数,这和平滑性有关,也就是说,感知机中神经元之间流动的是0和1的二元信号,而神经网络中流动的是连续的实值信号;
- 二者也有共同性质,输入较小时,输出接近0(或为0),随着输入增大,输出向1靠近(或变成1),也就是说,当输入信号为重要信息时,两者都会输出较大的值,当输入信号不重要的时,两者都会输出较小的值;
- 二者输出值都在0到1之前
- ReLU函数
数学表达式:
python实现:
def relu(x):
return np.maximum(0,x)
x = np.arange(-5.0, 5.0, 0.1)
y = relu(x)
plt.plot(x,y)
plt.ylim(-0.1, 5) # 指定y轴的范围
plt.show()
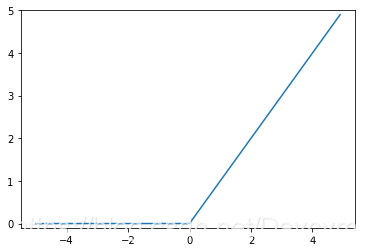
- softmax函数
数学表达式为:
其中, 表示假设输出层共有n个神经元,计算第k个神经元的输出
分子是输入信号 的指数函数,分母是所有输入信号的指数函数之和
python实现:
a = np.array([0.3, 2.9, 4.0])
exp_a = np.exp(a)
print(exp_a)
输出为:[ 1.34985881 18.17414537 54.59815003]
sum_exp_a = np.sum(exp_a)
print(sum_exp_a)
y = exp_a / sum_exp_a
print(y)
输出为:74.1221542101633
[0.01821127 0.24519181 0.73659691]
def softmax(a):
exp_a = np.exp(a)
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
神经网络的激活函数必须使用非线性函数,线性函数是一条笔直的直线,而非线性函数是指不想线性函数那样呈现出的一条直线的函数。
那么,为什么不能使用线性函数呢?
如果使用线性函数,那么不管如何加深层数,总是存在与子等效的“无隐藏层神经网络”
假如我们使用 作为激活函数,使用三层神经网络对应 运算,即 ,我们取 同样可以经过一次乘法来处理(即没有隐藏层的神经网络),因此激活函数必须使用非线性函数。
多维数组的运算
为了可以高效地实现神经网络,必须熟练掌握NumPy的多维数组运算
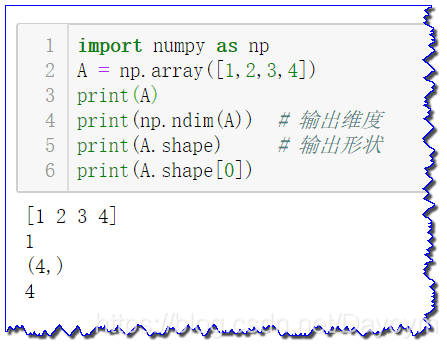
- 一维数组
import numpy as np
A = np.array([1,2,3,4])
print(A)
print(np.ndim(A)) # 输出维度
print(A.shape) # 输出形状
print(A.shape[0])
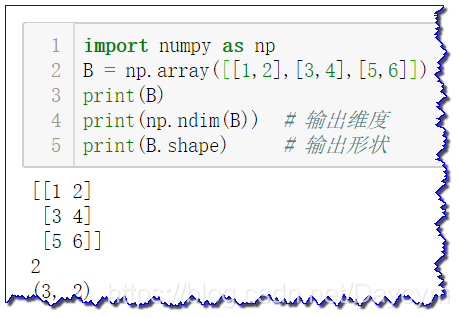
- 多维数组
import numpy as np
B = np.array([[1,2],[3,4],[5,6]])
print(B)
print(np.ndim(B)) # 输出维度
print(B.shape) # 输出形状
- 矩阵乘法
矩阵的乘法要满足前一个矩阵的列数等于第二个矩阵的行数
A = np.array([[1,2,3],[4,5,6]])
print(A.shape)
B = np.array([[1,2],[3,4],[5,6]])
print(B.shape)
print(np.dot(A,B))
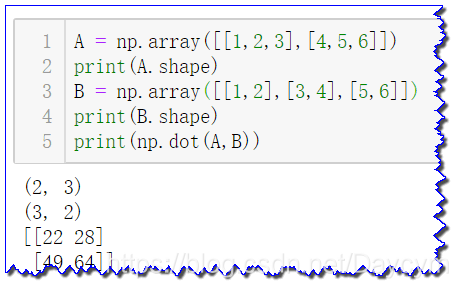
神经网络的内积
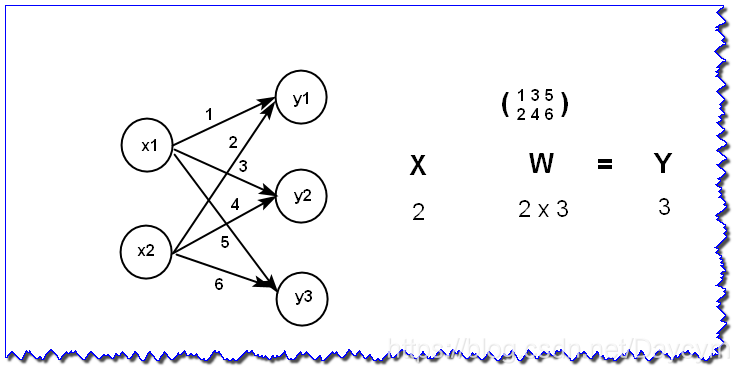
X = np.array([1, 2])
W = np.array([
[1, 3, 5],
[2, 4, 6]
])
print(X)
print(W)
print(W.shape)
print(X.shape)
Y = np.dot(X, W)
print(Y)

3层神经网络的实现
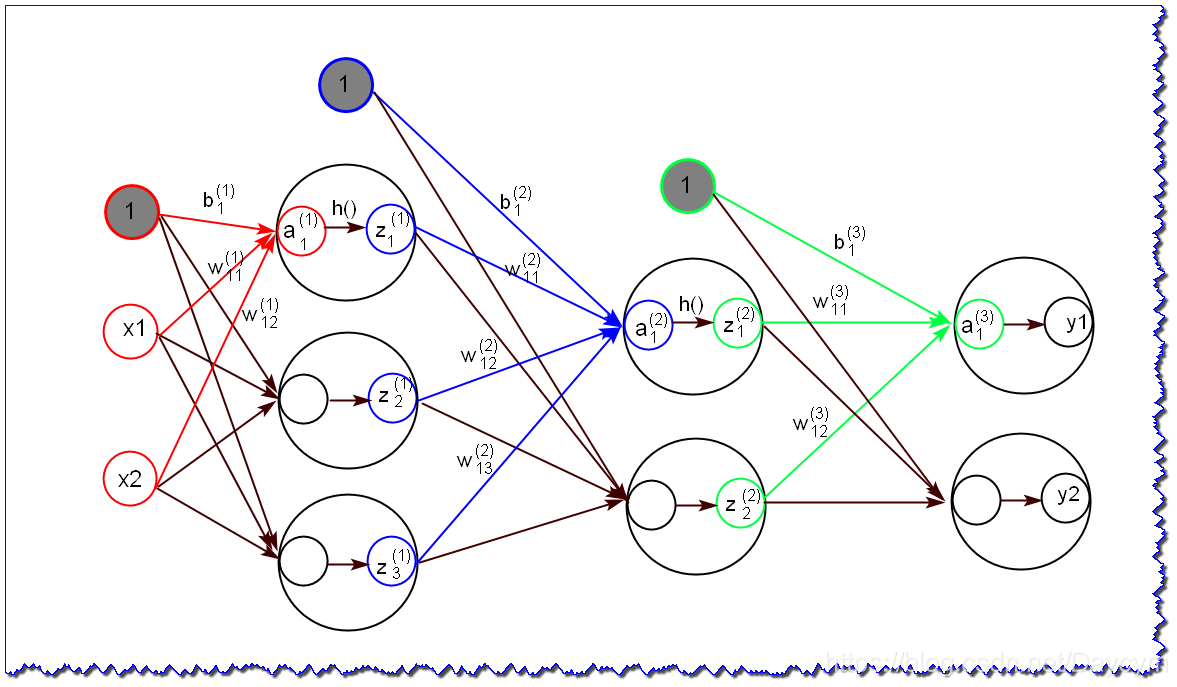
图中,红色表示输入层到第一层的信号传递,蓝色表示第一层到第二层的信号传递,绿色表示第二层到输出层的信号传递
- 其中 表示输入,灰色实心圆表示偏置项,
- 中a表示后一层的第a个神经元,b表示前一层的第b个神经元,c表示第c层的权重
- 中c表示第c层的第d个输出,用于下一层的输入
- 表示最终输出
- 从输入层到第一层的信号传递
由图,可得到:
也按此规律运算,写成矩阵的乘法运算可以表示为:
其中,
下面我们通过python的NumPy多维数组来实现以上步骤,这里将输入信号、权重、偏置设置成任意值。
X = np.array([1.0, 0.5])
W1 = np.array([
[0.1, 0.3, 0.5],
[0.2, 0.4, 0.6]
])
B1 = np.array([0.1, 0.2, 0.3])
A1 = np.dot(X, W1) + B1
Z1 = sigmoid(A1) # 使用sigmoid函数转换
print(Z1)
输出为:[0.57444252 0.66818777 0.75026011]
- 从第一层到第二层的信号传递
W2 = np.array([
[0.1, 0.4],
[0.2, 0.5],
[0.3, 0.6]
])
B2 = np.array([0.1, 0.2])
A2 = np.dot(Z1, W2) + B2
Z2 = sigmoid(A2) # 使用sigmoid函数转换
print(Z2)
输出为:[0.62624937 0.7710107 ]
- 从第二层到输出层的信号传递
W3 = np.array([
[0.1, 0.3],
[0.2, 0.4]
])
B3 = np.array([0.1, 0.2])
A3 = np.dot(Z2, W3) + B3
# 第二层到输出层的信号传递使用的激活函数不是sigmoid函数,而是恒等函数
def identity_function(x):
return x
Y = identity_function(A3)
print(Y)
输出为:[0.31682708 0.69627909]
代码整合
# 恒等函数
def identity_function(x):
return x
# 进行权重和偏置的初始化,并保存到字典network中
def init_network():
network = {}
network['W1'] = np.array([
[0.1, 0.3, 0.5],
[0.2, 0.4, 0.6]
])
network['b1'] = np.array([0.1, 0.2, 0.3])
network['W2'] = np.array([
[0.1, 0.4],
[0.2, 0.5],
[0.3, 0.6]
])
network['b2'] = np.array([0.1, 0.2])
network['W3'] = np.array([
[0.1, 0.3],
[0.2, 0.4]
])
network['b3'] = np.array([0.1, 0.2])
return network
# 前向(从输入到输出的传递处理)
def forward(network, x):
W1, W2, W3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, W1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, W2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, W3) + b3
y = identity_function(a3)
return y
# 测试
network = init_network()
x = np.array([1.0, 0.5])
y = forward(network, x)
print(y)
输出为:[0.31682708 0.69627909]
输出层的设计
神经网络可以用在分类问题和回归问题上,不过需要改变输出层的激活函数,一般而言,回归问题用恒等函数,分类问题用softmax函数。
前面我们介绍了softmax函数,它的分子和分母都涉及指数运算,因为指数运算的值很容易变得非常大,这在计算机的运算上有一定的缺陷,即溢出问题。
因此可对softmax函数进行改进,表达式如下:
这里的 可以使用任何值,但是一般选择输入信号的最大值
分子、分母都乘上 这个任意常数,值不变
不改进softmax函数
a = np.array([1010,1000,990])
print(np.exp(a) / np.sum(np.exp(a)))
输出为:array([nan, nan, nan])
很明显发生了溢出问题
通过减去最大值
c = np.max(a)
print(a - c)
print(np.exp(a-c) / np.sum(np.exp(a-c)))
输出为:array([ 0, -10, -20])
array([9.99954600e-01, 4.53978686e-05, 2.06106005e-09])
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
a = np.array([0.3,2.9,4.0])
y = softmax(a)
print(y) # 输出是0.0到1.0之间的实数
print(np.sum(y)) # 和为1
输出为:[0.01821127 0.24519181 0.73659691]
1.0
手写数字识别
使用数据集MINIST手写数字图像集,由0到9的数字图像构成
- MINIST的图像数据是28*28像素的灰度图像(各个像素取值为0到255之间)
- 每个图像数据都相应地标有“7”,“3”,“2”等标签
数据准备:
import sys, os
import mnist
# 自动下载数据集
(X_train, T_train),(X_test, T_test) = mnist.load_mnist(flatten=True, normalize=False)
# 输出各数据形状
print(X_train.shape)
print(T_train.shape)
print(X_test.shape)
print(T_test.shape)
输出为:
(60000, 784)
(60000,)
(10000, 784)
(10000,)
查看数据:
from PIL import Image
import numpy as np
def img_show(img):
pil_img = Image.fromarray(np.uint8(img))
pil_img.show()
(X_train, T_train),(X_test, T_test) = mnist.load_mnist(flatten=True, normalize=False)
img = X_train[0] # 训练数据的第一个图像数据
label = T_train[0] # 训练数据的第一个图像的标签
print(label) # 输出5
print(img.shape) # 第一个图像的形状,输出为(784,),并不是我们需要的28*28的
img = img.reshape(28,28) # 修改图像数据的形状
print(img.shape)
img_show(img) # 显示图像

神经网络的python代码:
神经网络的输入层有784个神经元,来源于图像大小28 28=784,输出层有10个神经元,来源于10个类别分类(0-9),有2个隐藏层,第一个隐藏层有50个神经元,第二个隐藏层有100个神经元,也可设置为其他值。
输入、权重、输出形状:(后者是批处理)
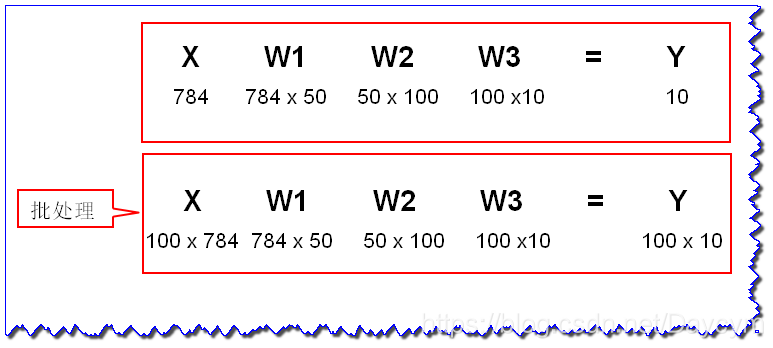
# 定义sigmoid函数
def sigmoid(x):
return 1 / (1 + np.exp(-x))
# 定义softmax函数(添加溢出对策)
def softmax(a):
c = np.max(a)
exp_a = np.exp(a - c) # 溢出对策
sum_exp_a = np.sum(exp_a)
y = exp_a / sum_exp_a
return y
# 获取数据normalize=True,函数内部会进行转换,将图像的各个像素值除以255,称为正规化
def get_data():
(x_train, t_train), (x_test, t_test) = mnist.load_mnist(normalize=True, flatten=True, one_hot_label=False)
return x_test, t_test
# 读入保存在sample_weight.pkl文件中的学习到的权重参数(这边没有学习过程,我们假设之前已经学习完,并把权重值保存了下来)
def init_network():
with open("sample_weight.pkl", 'rb') as f:
network = mnist.pickle.load(f)
return network
# 预测
def predict(network, x):
w1, w2, w3 = network['W1'], network['W2'], network['W3']
b1, b2, b3 = network['b1'], network['b2'], network['b3']
a1 = np.dot(x, w1) + b1
z1 = sigmoid(a1)
a2 = np.dot(z1, w2) + b2
z2 = sigmoid(a2)
a3 = np.dot(z2, w3) + b3
y = softmax(a3)
return y
# 测试1
x, t = get_data()
network = init_network()
accuracy_cnt = 0
for i in range(len(x)):
y = predict(network, x[i])
p = np.argmax(y) # 获取概率最高的元素的索引
if p == t[i]:
accuracy_cnt += 1
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
# 测试2
x, t = get_data() # 获取数据
network = init_network() # 生成网络
batch_size = 100 # 批数量
accuracy_cnt = 0
for i in range(0, len(x), batch_size): # 按批处理
x_batch = x[i:i+batch_size]
y_batch = predict(network, x_batch)
p = np.argmax(y_batch, axis=1)
accuracy_cnt += np.sum(p == t[i:i+batch_size])
print("Accuracy:" + str(float(accuracy_cnt) / len(x)))
输出为:Accuracy:0.9352
Accuracy:0.9352
总结
- 神经网络中的激活函数使用平滑变化的sigmoid函数或者ReLU函数
- 我们可以通过巧妙的使用NumPy多维数组,高效的实现神经网络
- 机器学习问题答题可以分为回归问题和分类问题
- 输出层的激活函数,分类问题一般使用softmax函数,回归问题一般使用恒等函数
- 分类问题中,输出层的神经元 个数按照要分类的类别数设置
- 通过批量处理,可以实现高速的运算