一、准备工作:
1.python3.x
2.编辑器pycharm
3.requests,json,os,base64,codecs,AES,pymysql(存入什么样的数据库就用什么,也可以不用数据库,直接存入txt文件)
import requests,json,os
import base64
import codecs
from Crypto.Cipher import AES
import pymysql#可加可不加二、数据源:《说散就散》网易云音乐评论区,本文选取了jc和袁娅维两个版本的《说散就散》,爬取她们各自的评论进行文本分析产生词云图,两张词云图的对比就会发现一些秘密了。因为自从原唱登上好声音后,对于jc人们是越来越熟悉了,网上说原唱比翻唱好听,更有青春感,也有人说袁娅维唱的才最好听,到底答案是什么呢?我想大众的眼光总是没错的,我们可以知道这首歌火起来时我们大多数人并不知道是jc的原唱,所以作者想着对比分析一下各自的歌曲评论,看能发现出什么不。
1.网易云音乐网页分析:
url:https://music.163.com/#/song?id=468513829
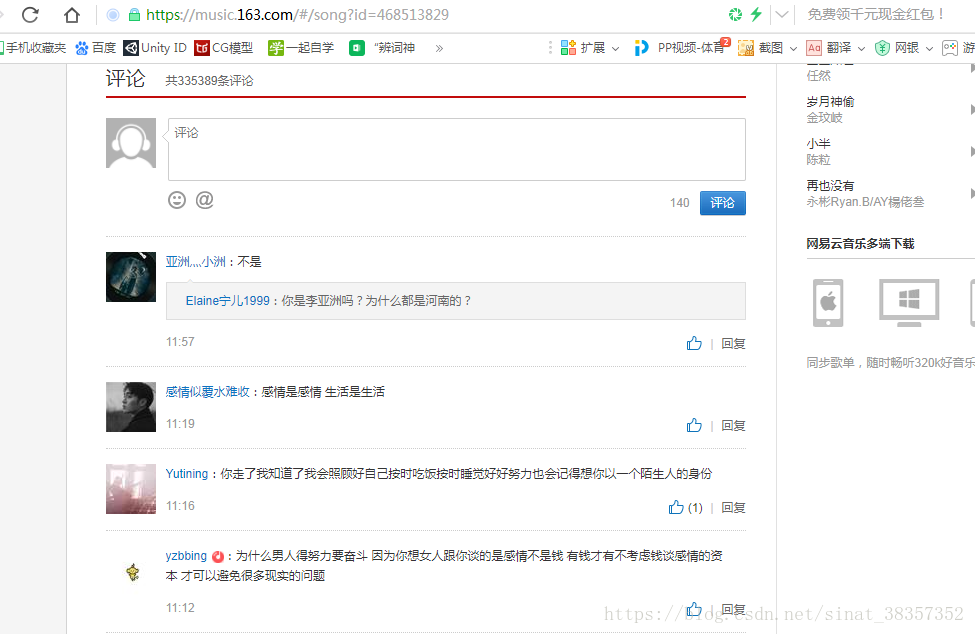
直接查看网页源代码可知评论数据不在源代码中,这时选取fiddler来抓包分析,打开fiddler后点击评论的下一页就会出现评论所在的网址,看下图。fiddler抓包详解请看https://blog.csdn.net/han_cui/article/details/77337870,网上资料也有很多。
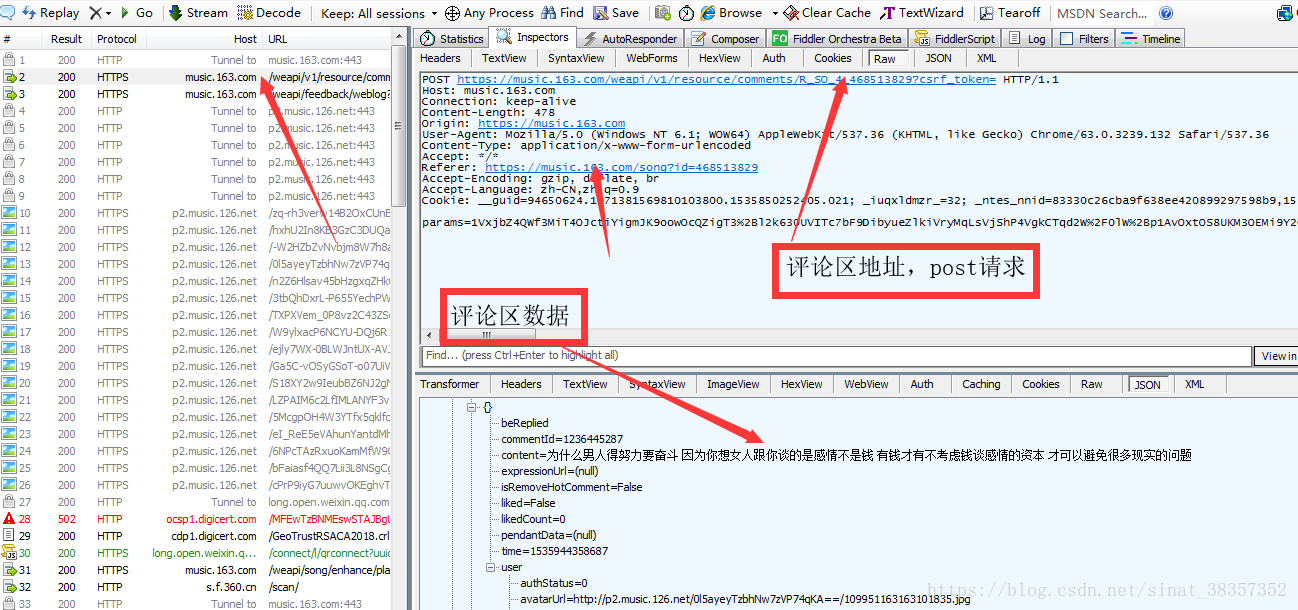
可以知道的是评论区的数据是以json的格式存储,20个为一组,进一步分析得post请求有两个参数需要一起传递过去才能访问该网址,由那些编码可知这是加过密的数据,这里就不说解密过程了,篇幅有限,也可以直接用这两个参数,但是其他页面就同样需要这样分析得出这两个参数。
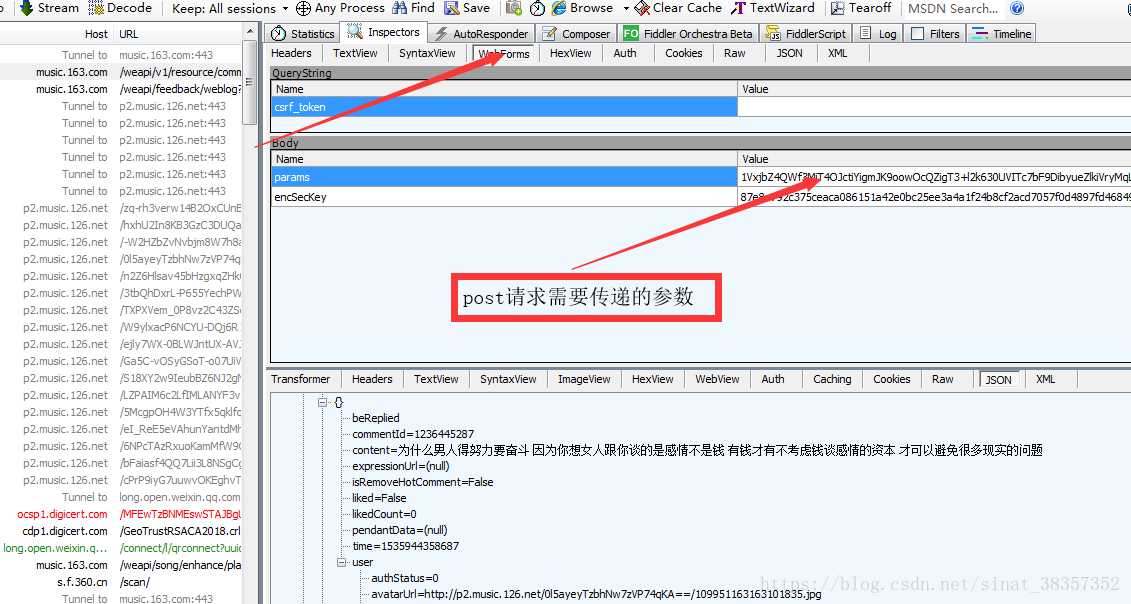
2.分析完之后开始写代码:
下面为爬虫类,用于获取数据:
class Spider():
def __init__(self):
self.header = {'User-Agent':'xxxxxxxxx',
'Referer': 'http://music.163.com/'}
self.url = 'xxxxxxxxxxxx' #post请求的网址
def __get_jsons(self,url,page):
music = WangYiYun()
text = music.create_random_16()
params = music.get_params(text,page)
encSecKey = music.get_encSEcKey(text)
fromdata = {'params' : params,'encSecKey' : encSecKey}
jsons = requests.post(url, data=fromdata, headers=self.header,verify=False)
return jsons.text
def json_list(self,jsons):
users = json.loads(jsons)
comments = []
for user in users['comments']:
name = user['user']['nickname']
content = user['content']
goodnum = user['goodnum']
user_dict = {'name': name, 'content': content, 'goodnum': goodnum}
comments.append(user_dict)
return comments
def write_sql(self,comments):
music = Operate_SQL()
print('第%d页正在获取' % self.page)
for comment in comments:
#print(comment)
music.add_data(comment)
print(' 该页获取完成')
def run(self):
self.page = 1
while True:
jsons = self.__get_jsons(self.url,self.page)
comments = self.json_list(jsons)
print(comments[0])
# 当这一页的评论数少于20条时,证明已经获取完
self.write_sql(comments)
if len(comments) < 20:
print('评论已经获取完')
break
self.page +=1下面为存入mysql数据库和程序启动:
# 操作 mysql
class Operate_SQL():
# 连接数据库
def __get_conn(self):
try:
self.conn = pymysql.connect(host='127.0.0.1',user='root',passwd='xxxx',port=3306,db='xxxx',charset='utf8mb4')
except Exception as e:
print(e, '数据库连接失败')
def __close_conn(self):
'''关闭数据库连接'''
try:
if self.conn:
self.conn.close()
except pymysql.Error as e:
print(e, '关闭数据库失败')
def add_data(self,comment):
sql = 'INSERT INTO `gumeng`(`name`,`content`,`goodnum`) VALUE(%s,%s,%s)'
try:
self.__get_conn()
cursor = self.conn.cursor()
#table = "comments" # 要操作的表格
# 注意,这里查询的sql语句url=' %s '中%s的前后要有空格
#sqlExit = "SELECT content FROM comments WHERE content = ' %s '" % (comment['content'])
#res = cursor.execute(sqlExit)
#if not res: # res为查询到的数据条数如果大于0就代表数据已经存在
cursor.execute(sql, (comment['name'], comment['content'], comment['goodnum']))
self.conn.commit()
return 1
#else:
#return 0
except AttributeError as e:
print(e,'添加数据失败')
self.conn.rollback()
return 0
except pymysql.DataError as e:
print(e)
self.conn.rollback()
return 0
finally:
if cursor:
cursor.close()
self.__close_conn()
# 找出post的两个参数params和encSecKey
class WangYiYun():
def __init__(self):
# 在网易云获取的三个参数
self.second_param = '010001'
self.third_param = '00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7'
self.fourth_param = '0CoJUm6Qyw8W8jud'
def create_random_16(self):
'''获取随机十六个字母拼接成的字符串'''
return (''.join(map(lambda xx: (hex(ord(xx))[2:]), str(os.urandom(16)))))[0:16]
def aesEncrypt(self, text, key):
iv = '0102030405060708'
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, 2, iv)
ciphertext = encryptor.encrypt(text)
ciphertext = base64.b64encode(ciphertext)
return ciphertext
def get_params(self,text,page):
if page == 1:
self.first_param = '{rid: "R_SO_4_400162138", offset: "0", total: "true", limit: "20", csrf_token: ""}'
else:
self.first_param = ('{rid: "R_SO_4_400162138", offset:%s, total: "false", limit: "20", csrf_token: ""}'%str((page-1)*20))
params = self.aesEncrypt(self.first_param, self.fourth_param).decode('utf-8')
params = self.aesEncrypt(params, text)
return params
def rsaEncrypt(self, pubKey, text, modulus):
text = text[::-1]
rs = int(codecs.encode(text.encode('utf-8'), 'hex_codec'), 16) ** int(pubKey, 16) % int(modulus, 16)
return format(rs, 'x').zfill(256)
def get_encSEcKey(self,text):
'''获取第二个参数'''
pubKey = self.second_param
moudulus = self.third_param
encSecKey = self.rsaEncrypt(pubKey, text, moudulus)
return encSecKey
def main():
spider = Spider()
spider.run()
if __name__ == '__main__':
main()至此爬虫完成,没有运行成功的可以联系我,微信LJ642615662。
三、清洗数据:
清洗数据可以先从mysql数据库导出到Excel然后去除重复项,选择评论列保存到txt文件里,也可以用python直接来清洗数据。
获取到的数据:
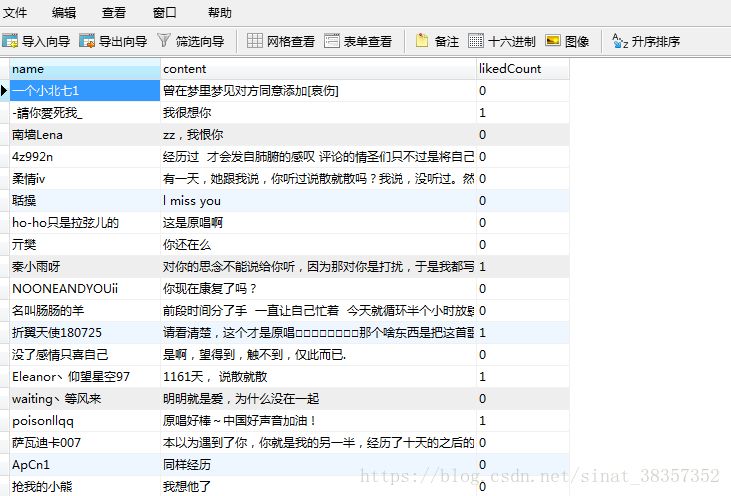
预处理后的数据:
四、文本分析,此次分析部分的源码和上篇《延禧攻略》分析差不多就不过多阐述了,想要源码的可以去我的上篇博文中找。
经过导入,分词,去停用词,画词云图后可得下图:
这个为jc的评论分析词云图,数据量11万

这个为袁娅维的评论分析词云图,为了更好的对比,数据量也是11万

大家看到两张图会有什么样的想法呢,本人第一感觉两首歌都是好听的,深受大家的喜爱,袁娅维的评论里分手、前任、心碎等扎心的词汇明显多于jc原唱的,说明大家在听这首歌时投入情感了,更多的人产生共鸣回想自己的经历,而jc的评论里原唱、中国、声音、感觉、希望则表现出许多人都是中国好声音播出之后才去听的原唱,也说明大家非常的尊敬这位歌手。你们的见解怎么样呢?欢迎联系作者,微信LJ642615662,一起讨论。