python爬取网易云歌曲并且保存到本地
打开网易云音乐首页随便打开了一个歌单列表(https://music.163.com/#/playlist?id=924680166) 先贴代码为敬
import requests
import json
from lxml import etree
import jsonpath
def saveSound(url,song_name):
# print(response.content)
root='E://python/%s.mp3'%song_name
with open(root,'wb') as f:
header={
"Origin": "https://music.163.com",
"Referer": "https://music.163.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
r=requests.get(url,headers=header)
f.write(r.content)
# with open('')
def getHTML(url):
header={
"Origin": "https://music.163.com",
"Referer": "https://music.163.com/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36"
}
response=requests.get(url,headers=header)
response.encoding='utf-8'
html=response.text
tree=etree.HTML(html)
url=tree.xpath('//ul[@class="f-hide"]/li/a/@href')
song_name=tree.xpath('//ul[@class="f-hide"]/li/a/text()')
for index,i in enumerate(url):
every_url=i.split('=')[-1]
song=song_name[index]
base_url='http://music.163.com/song/media/outer/url?id=%s'%every_url
print('第'+str(index+1)+'数据保存成功')
saveSound(base_url,song)
getHTML('https://music.163.com/playlist?id=924680166')
先寻找json数据放在那,跟我上一篇文章一样,需要先播放json文件才会出来,不然找不到的
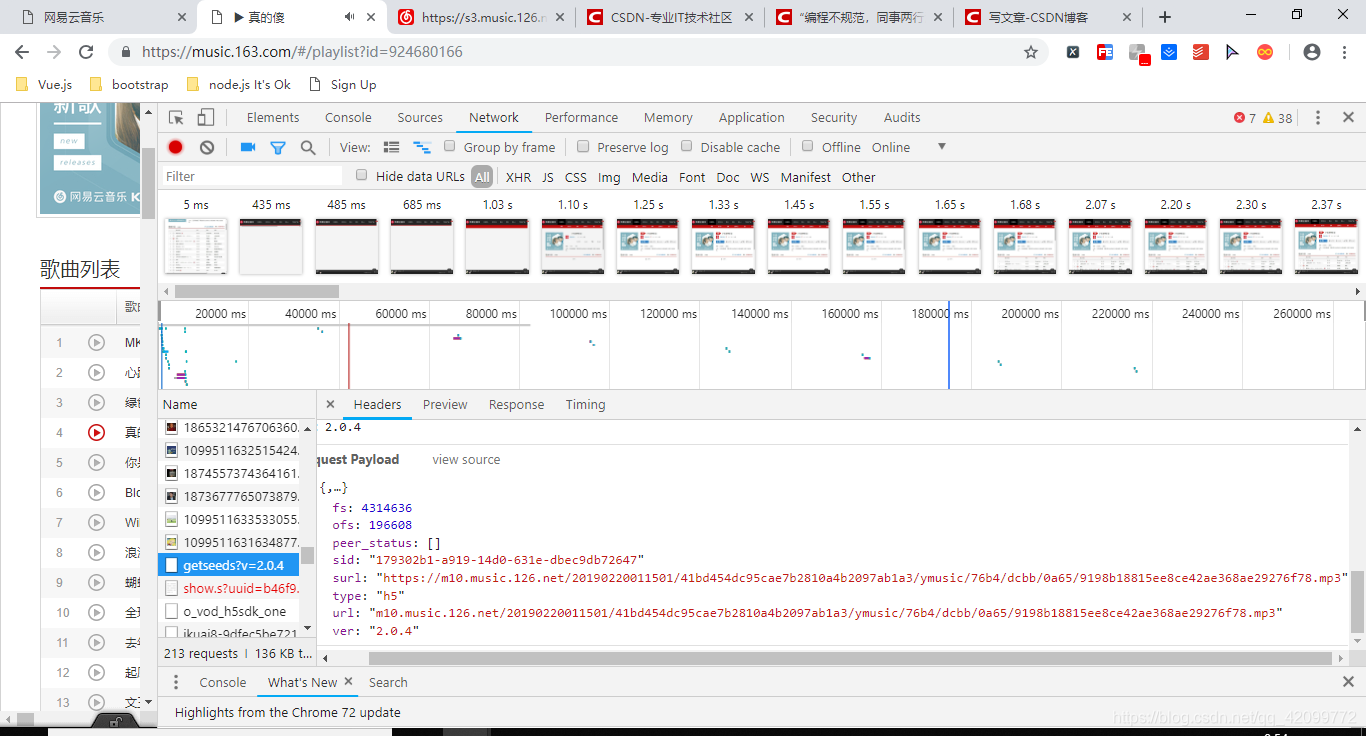
这里你会看到一个surl复制打开你会惊喜的发现这就是要找的音频文件,可是有什么规律那,怎么找也找不到https://m10.music.126.net/20190220011501/41bd454dc95cae7b2810a4b2097ab1a3/ymusic/76b4/dcbb/0a65/9198b18815ee8ce42ae368ae29276f78.mp3
其中最后的这个好找就是中间的这个像是随机生成的,这个歌单的所有的歌曲都是这样的
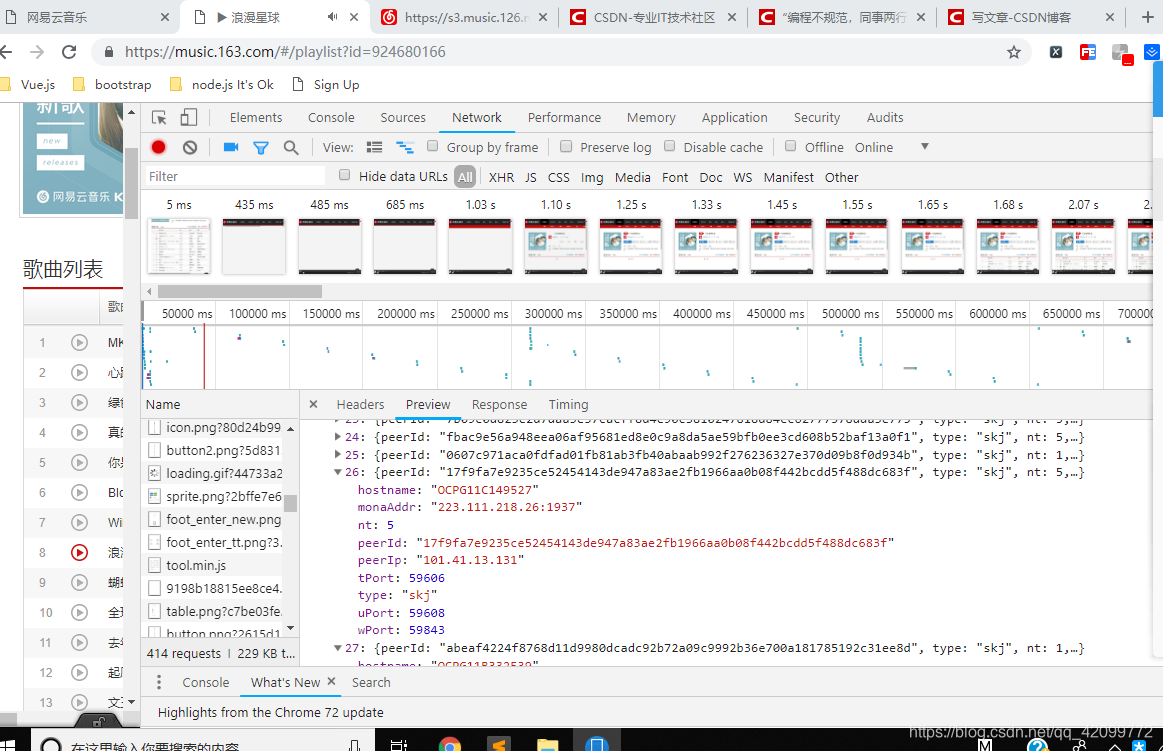
打开reponse查看好像看出点东西来 可是一共就20条歌曲怎么来的30条,里面的peerId可能就是最后的那个参数,当你再打开原网页的时候,检查歌曲,只有一个?songid=xxx并没有规律,来请求json文件,百度之后搜到网易云又音乐有外链接(http://music.163.com/song/media/outer/url?id=)不搜不知道,现在就简单了,只要获取了id就可以了,这个id就是原网页歌曲的song/id添加了以后(http://music.163.com/song/media/outer/url?id=1345651478
),请求就会发现音频文件直接就出来了,这就是最终要请求的地址。
然后就开始解析网页,使用xpath可是,刚开始xpath得不到数据,这时想到是不是异步加载的,不在原网页内,查看网页源代码,搜索相关信息,果然查看不到于是点开source查看果不其然,就在这里。
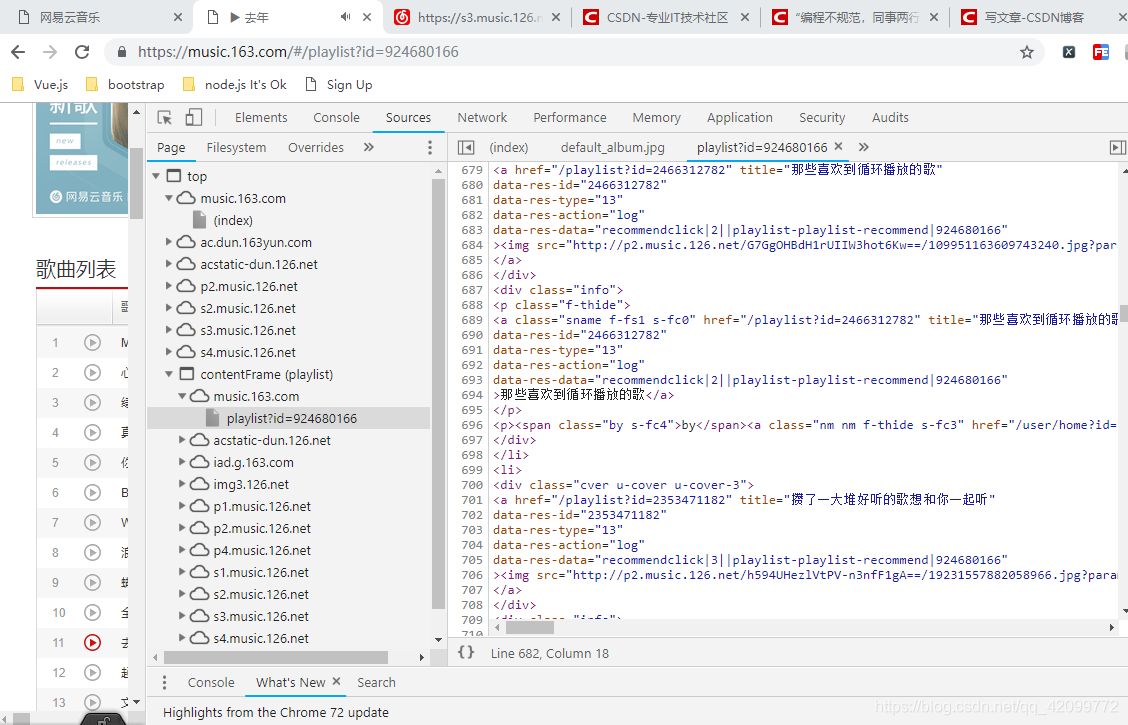
将光标移到这里会发现url地址是(https://music.163.com/playlist?id=924680166)而这个网页的url地址是(https://music.163.com/#/playlist?id=924680166)你如果请求第二个肯定获取不了歌曲信息,请求(https://music.163.com/playlist?id=924680166),现在就按照以前的方法就可以得到网易云音乐的音频文件,并且将其保存到本地文件中去。
需要注意的是要带请求头,就在请求拼接的歌曲信息url时,也要带headers,不然请求不了数据,你可以做个测试 ,如果不加请求头的话,输出
print(r.content)会出现code:-406,即使你发现文件里面已经有了,但也不能播放。