机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
每个估计量都有自己的优势和不足。估计量的泛化误差能被分解为偏差(bias), 方差(variance)和噪音(noise). 一个估计量的偏差是它对于不同训练集的平均误差。方差表示它对不同训练集的敏感程度。噪音是数据的属性。在下图里,我们看见函数
, 还有来自该函数的带噪音的样本。我们使用三个不同的估计量拟合这个函数。度为1, 4, 15的多项式特征的线性回归。从图上可以看出,第一个估计量充其量提供一个很差的拟合,因为它太简单了,偏差很高。第二个估计量非常完美地近似了函数,第三个估计量完美地近似了训练数据,但对拟合真实函数不是很好,即,它对改变的数据集很敏感,方差高。
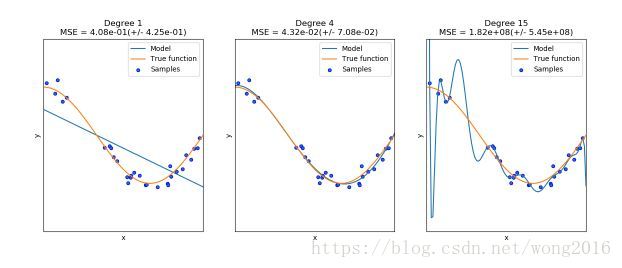
偏差和方差是估计量的内在属性,为了使它们尽量低,我们通常必须选择学习算法和超参数。减少一个模型的方差的另一种方法是使用更多的数据。然而,如果一个模型太复杂而不好估计时,你只能收集更多的数据。
在简单的一维问题里,很容易看出估计量是否遭遇偏差或方差的问题。然而,在高维空间里,模型变得很难可视化。出于这个原因,经常使用下面介绍的工具。
验证曲线
为了验证一个模型,我们需要分数函数,例如,分类器准确率。选择一个估计量的多个超参数的正确方式是网格搜索或类似的方法,这类方法选择在一个或多个验证集上具有最高分数的超参数。注意,如果我们根据一个验证分数优化超参数,那么这个超参数是有偏的,不再是一个好的泛化估计。为了得到一个适当的泛化估计,我们必须在另一个检验集上计算分数。然而,有时候画出一个超参数对训练分数和验证分数的影响,找出估计量是否过度拟合或欠拟合是有帮助的。
validation_curve函数帮助实现。
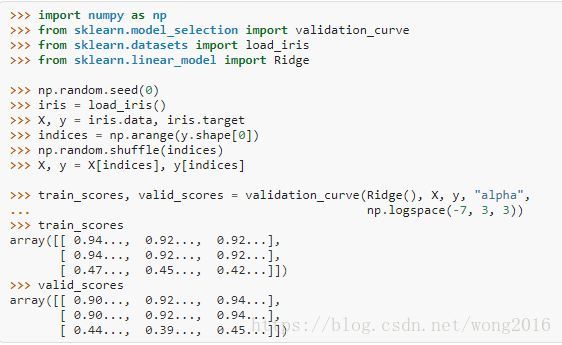
如果训练分数和验证分数都很低,估计量是欠拟合的。如果训练分数高而验证分数低,估计量是过度拟合,否则估计量是好的。然而,在实际情况中,低训练分数高验证分数通常是不太可能的。
学习曲线
一个学习曲线显示一个估计量的训练分数和验证分数随着训练样本量的变化情况。学习曲线可以帮助我们找出增加更多训练数据的受益程度,估计量是否遭遇方差/偏差误差。如果训练分数和验证分数收敛到的值,随着训练集样本的增加而变得太小,那么增加训练样本益处不大。下图显示的是,naive Bayes大致收敛到一个很低的分数。
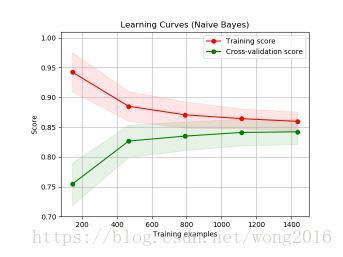
我们可能必须使用一个估计量,或者参数化当前估计量。如果对于最大的训练样本数,训练分数比验证分数大很多,增加训练样本将很有可能增加泛化性。下图显示的是SVM受益于增加训练样本。
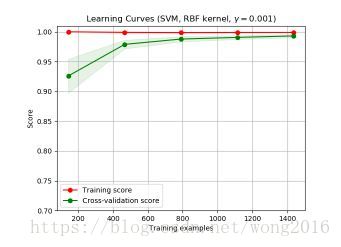
我们能够使用函数learning_curve产生画学习曲线必须的值,样本数、训练集的平均分数、验证集的平均分数。
阅读更多精彩内容,请关注微信公众号:统计学习与大数据