机器学习训练营——机器学习爱好者的自由交流空间(qq 群号:696721295)
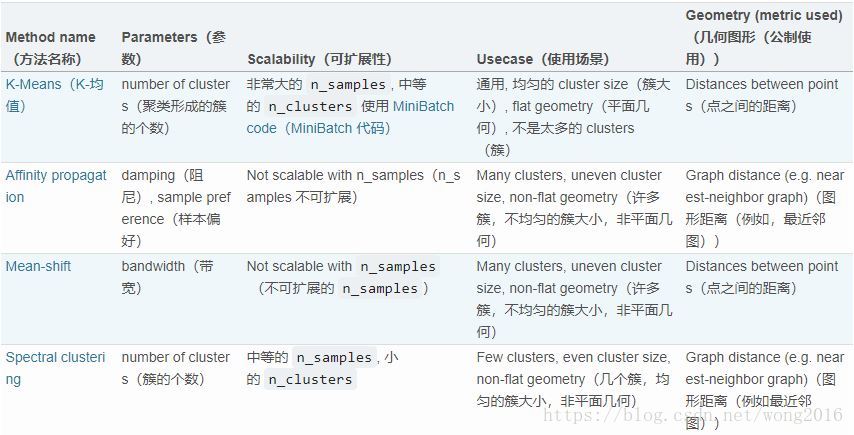
sklearn.cluster模块用来作聚类分析。每一个聚类算法包括两部分结果:一个执行fit方法的类,它在训练数据上学习类;一个函数,即,给定训练数据,它返回一个整数标签的数组,标签对应每个数据点的聚类结果,保存在labels_属性里。
输入数据
值得注意的是,sklearn.cluster模块执行的聚类算法能够取不同类型的矩阵作为输入。所有的算法都接受[n_samples, n_features]标准矩阵输入。
聚类方法概述

K-means
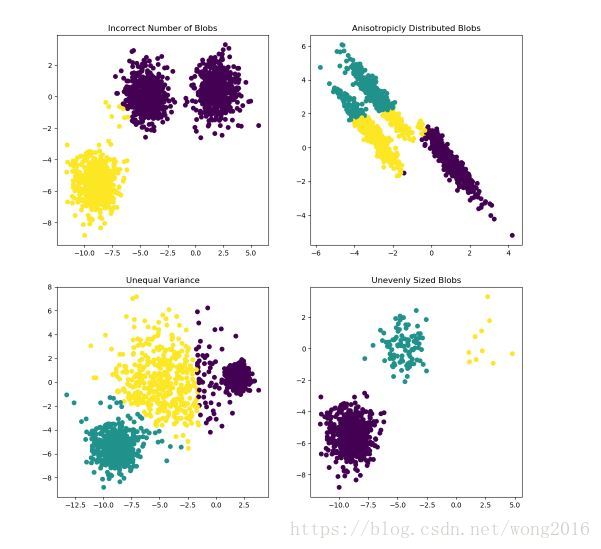
KMeans算法通过最小化类内平方和,将样本分隔进等方差的组。该算法要求聚类前指定类的个数。
K-means算法要将
个样本的数据集
分割成
个互不相交的类
, 每个类里的样本均值记为
. 这些均值称为类中心,注意,它们通常不是
里的数据点。k-means算法选择使得类内平方和最小的类中心。即,
该准则是度量类内一致程度的测度。一般认为,它存在下列缺点:
它假设类是凸且等方性的(convex and isotropic), 即向所有方向是均匀的,但实际情况并不总是这样。对于延向或不规则向的类,它的聚类结果并不好。
扫描二维码关注公众号,回复: 2231383 查看本文章
它并不是一个标准的测度。我们只知道它的值越小聚类效果越好,达到0是最好的。但是在高维空间,欧氏距离倾向于更大。因此,在k-means聚类前,使用主成分等降维策略,能够减轻这个问题,并且加速计算。
假如有充足的时间,k-means的准则将总是收敛的,但可能收敛到局部最小值,它高度依赖中心的初始化。解决这个问题的办法之一是“k-mean++初始化方案”。该方案初始化的中心彼此距离较远,结果优于随机初始化。在scikit-learn里,使用参数init='k-means++'实现。
Hierarchical clustering
层次聚类(Hierarchical clustering)是一个通用的聚类算法族,这类算法通过连续地合并或分割类,创建嵌套类别。类的层次由一棵树表示,称系统树图(dendrogram). 树根是包括所有样本在内的唯一的类,树叶是仅包括一个样本的类。
AgglomerativeClustering对象使用自下而上法作层次聚类:每个观测初始自成一类,然后连续地合并类。连接准则确定合并类的测度。
Ward 最小化所有类内差的平方和。
Maximum or complete linkage 最小化类的成对观测的最大距离
Average linkage 最小化类的所有成对观测的平均距离
FeatureAgglomeration
FeatureAgglomeration使用自下而上的层次聚类对特征做聚类,这样降低了特征数,因此,可以把它当作一个维数降低的工具。
聚类效果评价
Adjusted Rand index
假设已知真实的类标签分派labels_true, 样本的预测类标签分派labels_pred, adjusted Rand index(ARI)是一个测量两个分派相似性的度量函数。
from sklearn import metrics
labels_true = [0, 0, 0, 1, 1, 1]
labels_pred = [0, 0, 1, 1, 2, 2]
metrics.adjusted_rand_score(labels_true, labels_pred)你可以在预测的标签里置换0和1,重新命名为2和3,得到的分数相同。
labels_pred = [1, 1, 0, 0, 3, 3]
metrics.adjusted_rand_score(labels_true, labels_pred)而且,adjusted_rand_score能被用来作为一致性测度(consensus measure), 交换参数不会改变分数值。
metrics.adjusted_rand_score(labels_pred, labels_true)完美的标签,分值是1.
labels_pred = labels_true[:]
metrics.adjusted_rand_score(labels_true, labels_pred)坏的预测,分值是负的或接近0.
labels_true = [0, 1, 2, 0, 3, 4, 5, 1]
labels_pred = [1, 1, 0, 0, 2, 2, 2, 2]
metrics.adjusted_rand_score(labels_true, labels_pred)优势
随机标签分派的ARI分数接近0.
有界范围[-1, 1]: 负值是非常差的,类似的聚类结果有正的ARI, 完美匹配的分值是1.
不假定类结构
不足
ARI需要知道样本的真实类标签,这在实际情况里几乎是不可能的。然而,在完全的无监督学习环境下,ARI可以作为聚类模型选择的一致性指标。
互信息分数
给定真实的类标签labels_true和预测标签labels_pred, 互信息(Mutual Information)是一个度量忽略置换情况下,两种分派一致性的函数。这个函数有两个不同的归一化版本,Normalized Mutual Information(NMI) and Adjusted Mutual Information(AMI). NMI经常在文献里使用,而AMI用于反机会归一化(normalized against chance). 互信息分数在[0, 1]内,优势与不足和ARI类似。
from sklearn import metrics
labels_true = [0, 0, 0, 1, 1, 1]
labels_pred = [0, 0, 1, 1, 2, 2]
metrics.adjusted_mutual_info_score(labels_true, labels_pred)Homogeneity, completeness and V-measure
给定样本的真实类标签,可以根据条件熵理论定义直观的测度。
homogeneity: 每个类只包括同类成员
completeness: 一个给定类的所有成员被分派到相同的类里
在scikit-learn里,使用homogeneity_score and completeness_score把上面的两个概念变成分数。这两个分数值都在[0, 1]内,值越高聚类效果越好。
from sklearn import metrics
labels_true = [0, 0, 0, 1, 1, 1]
labels_pred = [0, 0, 1, 1, 2, 2]
metrics.homogeneity_score(labels_true, labels_pred)
metrics.completeness_score(labels_true, labels_pred)它们的调和平均称V-meature, 由v_meature_score计算。
metrics.v_measure_score(labels_true, labels_pred)使用homogeneity_completeness_v_measure, 可以同时计算这三种分数。
metrics.homogeneity_completeness_v_measure(labels_true, labels_pred)阅读更多精彩内容,请关注微信公众号:统计学习与大数据