官方地址:http://www.rabbitmq.com/getstarted.html
这些教程覆盖了使用RabbitMQ创建消息应用的基础。首先安装一个RabbitMQ服务(地址:http://www.rabbitmq.com/download.html),代码示例是开源的(地址:https://github.com/rabbitmq/rabbitmq-tutorials),同样,Spring也提供了对RabbitMQ的支持:Messaging with RabbitMQ(地址:http://spring.io/guides/gs/messaging-rabbitmq/)。
1.”Hello World”(入门)
RabbitMQ是一个消息broker。它接受并且向前(accepts and forwards)消息,你可以将它想象成一个邮局:当你把想发的邮件放入邮箱时,邮递员最终会将邮件投递给你的接收人。以此类比,RabbitMQ就是一个邮箱,邮局,邮递员。
唯一的不同就是RabbitMQ并不需要实质的纸张。取而代之地,它可以接受,并保存二进制的数据--messages
RabbitMQ,通常会使用下列术语
Producer:发送消息的程序
Queue:RabbitMQ中的一个queue就是一个邮箱的名字。所有的消息流经RabbitMQ和你的应用,它们只能被存储到queue当中。Queue绑定了主机的内存和磁盘的限制,它本质上是一个庞大的消息缓冲,生产者可以发送多个消息到queue,多个消费者也可以从一个queue当中获取数据。
Consumer:类似于接收。一个消费者就是一个等待接收消息的程序。
Producer、consumer、broker可以不再一个主机中,一个应用也可以既是生产者也是消费者。
RabbitMQ提供了Java的客户端:amqp-client


Spring提供了rabbit的支持:spring-rabbit
*Sending doesn’t work
如果broker在没有足够的空闲磁盘空间时启动,则会拒绝接收消息。检查broker日志文件确认,必要的话,可以减少限制。配置参数为’disk_free_limit’,详情参见配置文档http://www.rabbitmq.com/configure.html#config-items。
DefaultConsumer是接口Consumer的一个实现类,用来缓冲服务(生产者)发送过来的消息。

*注意,我们尝试接收(消费)消息之前需要确保the queue已经存在。
2.Work queues
在上一个教程中,我们写了一个应用来发送和接收队列上的消息。本节我们将创建一个用于在多个Worker上分配耗时消费任务的Work Queue。
Work Queue(又叫做Task Queue),它会避免立即执行一个占用大量资源的Task,并且会等待Task的完成。我们会安排Task稍后执行。我们将Task压缩成一条消息,并发送到queue。一个Worker进程会在后台取出队列中的Task,最终会执行这个Job。当你运行了多个Worker时,这些Task会分配给它们。
这个概念在Web应用中会尤其地有用,因为不可能在一个简短的HTTP请求过程中,去处理一个复杂的Task。
Preparation 准备
在上一节中我们发送了一个”Hello World”消息。现在我们将发送字符来代表一个复杂的Task。我们没有真正的Task,比如压缩图片...,我们可以通过使用Thread.sleep()函数来将自己伪装成很busy。我们用点号’.’的数量来表示Task的复杂度;每个小数点.都代表一秒钟的”work”,比如,”Hello...”任务会占用3秒时间。我们稍微改动一下上一节示例”Send.java”的代码,支持发送任意数量的消息。它会把我们的task发送到workqueue,我们命其名为”NewTask.java”


之前的”Recv.java”程序同样需要做出调整:它将处理已投递到queue的消息体,并根据消息中的小数点’.’进行停顿,一个点’.’停顿1秒。So我们称之为”Worker.java”


编译:

Round-robin dispatching(轮询调度)
使用Task queue(work queue)的优势之一就是有能力并行地执行Task。如果有Task堆积,只需增加worker即可。
默认情况下,RabbitMQ会有序地将消息发送给每个consumer,平均每个consumer都会获取到同样数量的消息。这种调度消息的方式称为”round-robin”。
Message acknowledgment(消息确认/投递确认)
可能执行某个Task会花费一些时间。当一个消费者consumer执行了一个task,并且只完了一部分就死掉了时会发生什么?按照当前的code,一旦消息投递到消费者就会立即被清除。这种情况下,如果worker(消费者)在工作状态时将它kill,会导致消息的丢失。我们也会丢失所有已经分配给这个worker(consumer)但还没有执行的Task。
但是我们不希望丢失任何消息,如果一个worker挂点,我们会将任务投递给其它的worker。
为了确保消息不会丢失,RabbitMQ提供了一种投递确认机制message acknowledgements(http://www.rabbitmq.com/confirms.html)。一个ack确认会被消费者发回告知RabbitMQ(客户端),指定的message已经被接收,消费,RabbitMQ(服务端)可以删除它了。
如果一个消费者挂掉了(它的channel已经关闭,连接关闭,或者TCP连接丢失)而没有发送(给客户端)ack确认,RabbitMQ会认为这条message并没有被消费,会将它re-queue重入队列。如果此时有其他的消费者存活,此条message会立刻地重新投递给另一个consumer。这样,就可以确保没有消息丢失,即使worker(消费者consumer)偶尔会死掉。
如果没有消息超时,当consumer死掉时,RabbitMQ将重新投递此消息。即使消息消费过程会花费很长很长的时间,这种方式仍然是很好的。
Manual message acknowledgments 手动消息确认(http://www.rabbitmq.com/confirms.html)默认是开启的。在上一个示例中,我们通过’autoAck=true’关掉了手动确认。设置’autoAck=false’,一旦任务处理完成(消费完成),worker(消费端)会发送一个ack确认。

使用这段代码我们可以确保即使你在consumer处理消息的时候通过CTRL+C的方式关掉了工作进程,也不会有消息丢失。进程死后的不久,所有未收到ack确认的message都将会被重新投递(re-queue)。
ack确认一定要被接收message的同一个channel发送。尝试使用不同的channel去发送ack确认,将会抛出一个channel-level protocol的异常(详情见http://www.rabbitmq.com/confirms.html)。
*Forgotten acknowledgment(忘记ack确认)
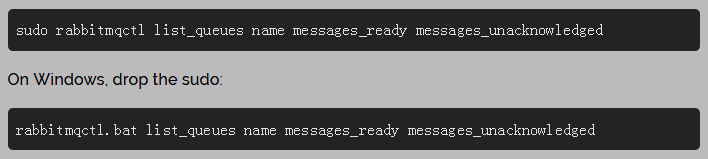
这是一个很常见的错误:(消费后)忘记ack确认(basicAck)。犯错很容易,但是后果很严重。当你的客户端退出的时候,消息会被重新投递,没有ack确认的message永远都不会被释放,导致RabbitMQ会消耗越来越多的内存。为了debug这种错误,你可以使用rabbitmqctl 输入’messages_unacknowledged’:
Message durability 消息持久化
我们学习了当consumer死掉的时候如何确保消息不会丢失。但是如果RabbitMQ服务停止,我们的消息仍然会丢失。
当RabbitMQ服务退出或者崩溃,它将忘记它的queues和messages除非你告诉它不要这样做。2件事来确保messages不会丢失:持久化queue和messages。
首先,我们要确保RabbitMQ永远不会丢失queue。为了确保这件事,我们需要将queue声明为durable:

尽管这条command是对于queue是自我调整,但是上述步骤并不会生效。这是因为我们之前已经定义了’hello’的queue是非持久的。RabbitMQ不允许使用不同的参数去重新定义一个已经存在的queue,任何这样做的程序都是返回一个错误error。但是有一个变通的方案,就是使用不同的名字声明一个queue,比如’task_queue’:

‘queueDeclare’的改变需要兼顾生产端producer和消费端consumer的code。
此时,我们就可以确保即使在RabbitMQ重启时,不会有queue的丢失。现在,我们通过设置MessageProperties(实现了BasicProperties)的PERSISTENT_NEXT_PLAN来将message标识为持久的。

*需要注意的是,即使标记messgae为持久的也无法完全的保证消息不会丢失。尽管它(MessageProperties.PERSISTENT_NEXT_PLAN)告诉RabbitMQ将这些message保存到磁盘,但是在RabbitMQ已经接收到message还没有保存的时候,还是会存在短时间的时窗。RabbitMQ不会绝对地’fsync(2)’为每个message--它也许只是将message保存到缓存中,而没有写入磁盘。这种方式不是强持久的,但是对于我们的简单任务已经足够了。如果你需要更强的保证,你可以使用publisher confirms(https://www.rabbitmq.com/confirms.html)。
Fair dispatch调度失败
你可能已经意识到(Round robin)调度并不会完全按照我们预想的那样去工作。比如,假设我们有2个worker,所有奇数次的message都十分繁重,而所有偶数次的message都很小,这就会导致一个worker经常会很busy,另一个确几乎没什么工作。RabbitMQ无法感知这一点,仍让会均匀的分配message。
这是因为RabbitMQ只是在当一个message进入到queue的时候去分配它,它不会考虑其中一个consumer中未ack确认的消息数量。仅仅是盲目的分发每个message。

为了解决这个问题我们可以设置参数’prefetchCount = 1’来调用’basicQos’方法。来告知RabbitMQ每次给worker分发message的时候不要超过1个message。换句话说,当一个worker的message没有处理完成并返回ack确认时,不要给这个worker分发新的message。取而代之,它(RabbitMQ)可以将message分发给下一个空闲的worker。

*关于queue size需要注意一下,如果所有的worker都在工作中,你的队列可能会被填满。你需要留意这件事情,或者增加更多的worker,或者使用一些其它的策略。
整理:
NewTaks.java(https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/java/NewTask.java)
Worker.java(https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/java/Worker.java)
3.Publish/Subscribe 发布/订阅
一次发送消息到多个consumer。
在上一节教程中,我们创建了一个work queue。在work queue中每个task都会投递给其中一个worker,在这一部分中会完全不同--我们将会把一条message投递给多个consumer。这种形式称为’publish/subscrible’。
为了说明这种模式。我们将创建一个简单的日志系统。它由2部分组成,一部分发送日志消息,一部分接收消息并打印。
在这个日志系统中,每一个consumer都可以接收到同样的message。这样,我们可以指定其中一个consumer去持久日志消息到磁盘,与此同时,我们使用其它的consumer来查看日志消息。
已发布的message将会广播到所有的consumer。
Exchanges 交换机
在上一部分的教程中,我们发送和接收消息都是使用一个queue。现在介绍RabbitMQ中一个更全面的消息模式。
快速复习一下上节教程的内容:
Producer 是用来发送消息的客户端应用。
Queue是一个存储消息的buffer。
Consumer是用来接收消息的客户端应用。
RabbitMQ中messaging model 的核心就是producer永远都不会直接将消息发送到queue。事实上,相当多的producer甚至都不知道message是否被投递到queue。
取而代之,producer只能发送消息到一个exchange。Exchange非常简单。一面接收producers发送的message,一面将messages放入queue。这个exchange一定会知道它接收到的message是用来干什么的。将它投递给指定的queue?还是将它投递给所有的queue?或者是丢弃这条message?这些规则依赖于exchange的类型。

Exchange可用的类型有以下几种:direct,topic,headers,fanout。我们这节关注最后一个类型-fanout。首先创建一个此类型的exchange,名字为’logs’:

Fanout(扇形)exchange非常简单。正如它的名字,它将会把接收到的所有messages广播给所有的queue。
*List exchanges 列出exchange
你可以在你的Rabbit服务上通过’rabbitmqctl’命令来列出已有的exchange:

这个列表中可能会有一些’amq.*’的exchange和一些默认的exchange(未命名)。这是系统默认创建的。
*Nameless exchange 未命名的exchange
在上一部分教程中(work queue),并没有涉及到exchange的概念。但是我们仍可以发送message到queue。那是因为我们使用了一个命名为空字符串””的一个默认exchange。
回忆一下之前我们是如何发送message的:

第一个参数就是exchange的名字。空字符串””就表示默认的或无名的exchange:如果参数’routingKey’存在,message会根据’routingKey’被路由到指定的queue。
现在,我们将message发布到已命名的exchange。

Temporary queues 临时queue
也许你可能会记得之前我们使用的queue都有一个特定的名字(“hello” 和“task_queue”)。可命名的queue对我们来说十分重要--我们需要将workers连接到相同的queue。如果你想在producer与consumer之间共享queue,那么名字就尤为重要了。
但这对我们的日志应用并不重要。我们想接收所有消息,而不仅仅是它们的子集,我们同样也关心当前的日志message,而不关心之前的。为了解决这个问题,我们需要做2件事:
首先,无论我们何时连接Rabbit我们都需要一个新的、空的队列。所以,我们需要使用一个随机的名字来创建queue,或者,更好的一种方式-让RabbitMQ服务为我们选择一个随机队列名称。
其次,一旦我们断开了consumer与queue之间的连接,queue会自动删除。
在java客户端中,我们支持无参的’queueDeclare()’,会创建一个非持久的、独有的、可自动删除的队列(使用一个自动生成的名称):

你可以学习更多关于’exclusive’标识和一些其它的queue属性:http://www.rabbitmq.com/queues.html。
这样一来,queueName就是一个随机的队列名称。比如:amq.gen-JzTY20BRgKO-HjmUJj0wLg。
Bindings 绑定关系

我们创建了扇形交换机(fanout exchange)。现在我们要告知exchange发送message给我们的queue。这种介于exchange与queue之间的关系称为一个绑定(binding)。

从现在起,’logs’交换机开始向我们的queue推送message。
*Listing bindings 列出绑定关系

整理:
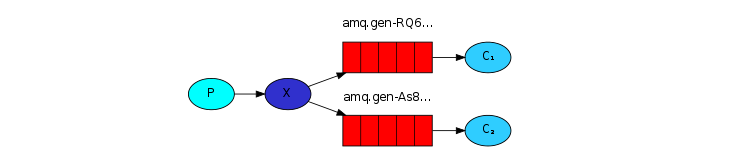
用来发送日志消息的生产者程序,和上一节教程中的code没什么太大的区别。最重要的就是我们现在将message发送到’logs’交换机而不是无名的交换机了。当发送消息时,我们需要提供一个routingKey,但是这个在数在扇形交换机中被忽略了。
EmitLog.java(https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/java/EmitLog.java)
如你所见,当你建立了到已声明的交换机的连接。发送消息到一个不存在的交换机是被禁止的。
ReceiveLogs.java(https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/java/ReceiveLogs.java)
4.Routing 路由
在上一个教程中我们建立了一个简单的日志系统,我们可以将日志消息广播给所有的接收者。
在本节教程中,我们将添加一个特性--我们可以订阅消息的一部分子集。比如,我们只将一些错误的日志消息保存到日志文件中,然而我们仍然可以看到所有的日志消息。
Bindings 绑定
上一节教程中,我们已经创建了一种绑定关系,回忆一下,是不是这样:

Binding就是介于exchange与queue之间的一种关系。这可以被解读为:这个queue对这个exchange的messages很感兴趣。
(producer)Binding提供了一个额外的参数’routingKey’。为了避免与消息发布(basic_publish)的参数混淆,我们称之为’binding key’。下面演示如何使用key创建一个绑定关系(binding):

一个binding key的意义依赖于exchange的类型。扇形交换机(fanout exchange)会忽略这个key。
Direct exchange 直连交换机
上一节教程中我们的日志系统会广播所有的消息给所有的消费者。现在想要扩展一下,允许消息的过滤。比如我们想要一个程序,只将error级别的日志消息持久到磁盘文件中,而不保存warning或info级别的消息。
我们之前使用的fanout交换机,不会为我们提供很好的灵活性--它只能无脑的广播。
我们将使用direct类型交换机来取代它。Direct交换机的路由算法很简单--消息会发送到binding key 与消息的routingKey相同的队列上。
为了说明它,思考下列设置:
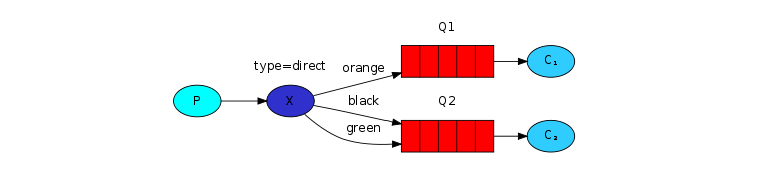
在这个设置中,我们可以看到direct类型交换机x和与其绑定的2个队列。第一个使用’orange’作为binding key,第二个队列有2个绑定关系,其中一个是’black’ binding key,另一个binding key 是’green’。
在上述设置中,一个消息使用routingKey ‘orange’发送消息到交换机,将会被路由到队列Q1。使用’black’或者’green’的消息会发送到Q2。所有其它的消息则都将被丢弃。
Multiple bindings (多绑定:一个key对应多个queue)
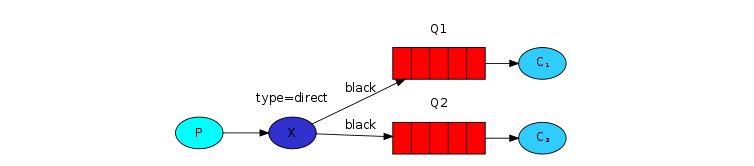
使用同一个binding key 来绑定多个queue是完全合法的。在我们的示例中,我们在交换机x与队列Q1中使用’black’增加一个绑定关系。这种情况下,direct类型的交换机将表现的和fanout交换机一样,会广播所有消息到匹配到的队列。即routingKey为’black’的消息将一同被投递到Q1和Q2队列。
Emitting logs
我们将这种模式应用到我们的日志系统中,使用direct类型交换机来代替fanout类型的交换机。我们将使用日志的等级来作为一个routing key。这样我们的消费者就会选择性消费。先说发送日志的程序:
首先,创建一个交换机:

准备发送消息:

参数severity可以是‘info’,‘warning’,‘error’的其中一个。
Subscribing 订阅
消费端的程序代码大致和上一节教程中的一样,需要注意的是--我们需要重新为每一个参数severity和队列之间建立一个绑定关系:
整理:

5.Topics
在上一节教程中,我们对日志系统进行了升级。使用direct类型的交换机取代了只能无脑广播的fanout类型交换机,获得了可选择性消费的能力。
尽管使用direct交换机升级了系统,它仍然还有限制--它不能根据多个条件进行路由。
在日志系统中,我们可能不仅仅想要根据日志的等级去订阅,还想根据日志输出的来源去订阅。你可能了解unix系统中syslog的概念,我们可以通过日志等级(info/warn/crit..)和日志生成方式(auth/cron/kern..)多条件去路由。
这会给我们提供更好的灵活性--也许我们既想监听来自’cron’(定时)的消息,也想监听’error’等级的日志消息。为了在日志系统中实现这种功能,我们需要学习一下更加灵活的topic交换机。
Topic exchange
消息发送到topic交换机并不可以使用多个routing_key-它是以点号’.’分开的一串字母。这串字符可以是任意的,但是通常它们都会用来指定消息的一些特性,比如:”stock.usd.nyse”,”nyse.vmw”,”quick.orange.rabbit”。它可以是你想要的任何单词,大小不能超过255字节。
此时,binding key必须是相同的格式。Topic交换机路由的逻辑与direct交换机类似--指定格式routingKey的格式会被投递到所有与bindingKey匹配的队列上。关于bingding keys需要注意2点:
①*(star)只能代替一个单词(就是单词中不能有点号’.’)
②#(hash)可以代替0或任意数量的words(就是代表所有)
举个例子:
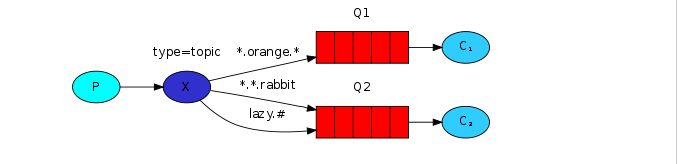
在这个例子中,我们发消息来描述动物。消息的routingKey由3个单词组成(2个点’.’)。
routingKey的第一个单词描述速度,第二个描述颜色,第三个描述物种:”<speed>.<colour>.<species>”。
我们创建3个绑定关系:Q1使用”*.orange.*”,Q2使用”*.*.rabbit”和”lazy.#”。
3个关系可以总结为:
Q1只对orange的动物感兴趣。
Q2可以接收到所有关于兔子或者是懒的动物的消息。
routingKey为“quick.orange.rabbit”的消息将同时被投递到2个队列。routingKey为”lazy.orange.elephant”的消息也将同时被投递到2个队列中。”quick.orange.fox”的消息只能被投递到Q1队列,”lazy.brown.fox”的消息只能投递到Q2,”lazy.pink.rabbit”虽然与2个binding key都匹配,但是它只能被投递到队列一次。”quick.brown.fox”没有匹配任何绑定关系,所以将被丢弃。
如果我们使用一个或四个单词去发送消息,像”orange”,”quick.orange.male.rabbit”会发生什么?好的,它们没有匹配到任何绑定关系,将被丢失。
另一方面,”lazy.orange.male.rabbit”,即使它有4个单词,仍然会匹配上最后一个绑定关系,然后被投递到Q2。
*Topic exchange
Topic交换机同样也可以实现其他交换机的功能。
当一个队列使用”#”(hash)来绑定时---它将接收所有的消息,无论routingkey的值是什么--就像fanout交换机一样。
当我们既不使用”*”也不使用”#”的时候,topic交换机就和direct交换机一样了。
6.RPC
在第二节教程中我们学会了如何使用Work queue来分发任务。
但是如果我们想要在远程机器上运行一个函数并等待结果呢?好的,这是一个新的故事。就是我们所有的远程过程调用(RPC)。
这本节教程中,我们将使用RabbitMQ 构建一个RPC系统:一个客户端和一个可扩展的服务端。因为我们没有了占用大量时间的task让我们去分配调度,我们将创建一个虚拟的RPC服务,用于返回斐波纳契数列。
Client interface 客户端接口
为了演示如何使用一个RPC服务,我们将创建一个简单的客户端类:Client.class。它将暴露一个call()方法,用来发送一个RPC请求并阻塞知道收到回复:

* A note on RPC 关于RPC
尽管在计算中RPC是相当常见的模式,它会经常受到诟病。当一个程序员没有意识到一个函数到底是本地调用还是缓慢的RPC调用时,问题就显现了。这样的混淆导致了不可预知的系统,并增加了调试的复杂度。相对于简化的软件,滥用RPC会导致代码维护性降低。
如果可以忍受这些,还需要考虑下列建议:
①确保区分本地与远程调用的函数。
②Document your system,确保组件中的依赖清晰。
③处理异常情况。当RPC服务挂掉或者超时,客户端需要怎么处理
当你对RPC犹豫不决时。如果你想,可以使用一个异步的流水线pipeline---来取代阻塞的RPC,结果同样异步地传递到下一个阶段。
Callback queue 回调队列
通常来将,使用RabbitMQ来做RPC是很容易的。一个客户端发送一个请求消息,一个服务端回复请求的结果消息。为了接收到请求返回信息,我们需要通过请求传递一个回调的队列地址。我们可以使用默队列(Java客户端中):

*Message properties
AMQP 0-9-1协议中对message预定义了14中属性。大多数属性很少使用,除了下面几种:
①deliveryMode:标记message是持久的(使用值2)还是临时的(任意其他值)。第二节教程中提到过这个参数。
②contentType:用于描述mime-type。比如,我们常用的JSON,就可以将此属性设置为:application/json。
③replyTo:常用来命名一个回调的队列
④correlationId:用来关联请求与其RPC返回信息
我们需要一个新的import:

Correlation id 关联ID
之前的方法中我们建议为每个RPC请求创建了一个回调队列。那是相当低效的,有一种更好的方式---为每个客户端创建一个回调队列。
这又引出了一个新的问题,回调队列中的RPC返回信息就是是哪一个请求的。此时’correlationId’数据就有用了。我们可以为每一个请求创建一个唯一的值作为’correctionId’,当我们收到回调队列中的message时,我们将查看它的’correctionId’属性,通过它我们可以匹配到它对应的请求。如果我们发现一个无法识别的(不存在的)correctionId,我们将删除这条message---它不属于我们的请求。
也许你会问,我们为什么会忽略回调队列中无法识别的消息,而不是调用失败返回error?这可能是因为服务端的原因。尽管不太现实,还是有可能RPC服务刚刚给我们发送完RPC请求结果,但还没来得及对请求messag进行ack确认,如果发生了,那么重启的RPC服务端仍会消费那一条message。这就是为什么客户端需要做消费幂等处理的原因,避免重复消费。
Summary 摘要

我们RPC的工作流程是这样的:
对于一个RPC请求,客户端发送的消息将携带2个属性:’replyTo’将设置一个匿名的队列(request请求创建),’correlationId’将为每个请求设置一个唯一值。
请求会被发送要一个’rpc_queue’队列。
RPC worker(服务端)等待队列上的消息。当消息出现,它(服务端)就开始工作并将结果发送回客户端,客户端队列就是’replyTo’属性的值。
客户端等待回调队列上的数据。当消息出线,它(客户端)检查correclationId属性。如果与请求requestd的correclationId相同时,返回结果到应用。
整理:
斐波纳契任务:

我们声明了一个斐波纳契函数。
RPCServer.java(https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/java/RPCServer.java)
服务端的代码更加简洁:
通常都是,建立连接,channel,声明一个队列。
我们也许想运行不止一个服务进程,为了均衡Server,我们需要设置’prefetchCount’在channel.basicQos()中。
我们使用basicConsume来连接队列,DefaultConsumer中会提供一个回调队列,执行work,发送执行结果到回调队列。
RPCClient.java(https://github.com/rabbitmq/rabbitmq-tutorials/blob/master/java/RPCClient.java)
客户端代码稍微复杂:
我们建立连接和channel。
Call()方法就是一个RPC请求。
我们先生成一个唯一的correclationId并保存它--我们在RpcConsumer中实现了handleDelivery方法,我们将使用这个值来捕获对应的请求返回信息。
然后,我们创建了一个专门的回调队列,然后去订阅它。
然后,我们发送请求消息,使用’replyTo’和’correclationId’两个参数。
然后,静静地等,等到合适的responsed出现。
既然我们消费者的投递处理(消费)发生在单独的线程中,我们需要做一些事情来延缓main线程在结果返回前继续执行。使用BlockingQueue是一种很好的解决方案。这里,我们创建一个容量为1的ArrayBlockingQueue来等待一个返回结果。
handleDelivery方法做了一个简单的工作,检查每一个返回的消息的correclationId是否为我们正在寻找的。如果是,就把它放到BlockingQueue中。
同时main线程等待并从BolckingQueue中取出结果。
最后将结果返回给user。