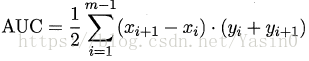验证集:模型评估与选择中用于评估测试和模型调参的数据集。
测试集:在研究对比不同算法的泛化性能时,用测试集上的判别效果来估计模型在实际使用时的泛化能力,测试集应该尽可能与训练集互斥,即测试样本尽量不在训练集中出现、未在训练过程中使用过。
调参:对每个参数选定一个范围和变化步长,例如在[0,0.2]范围内以0.05为步长,则实际要评估的候选参数值有5个,最终是从这5个候选值中产生选定值。
根据切分的方法不同,交叉验证分为下面三种:
第一种是简单交叉验证。首先,随机的将样本数据分为两部分(比如: 70%的训练集,30%的测试集),然后用训练集来训练模型,在测试集上验证模型及参数。接着,再把样本打乱,重新选择训练集和测试集,继续训练数据和检验模型。最后我们选择损失函数评估最优的模型和参数。
第二种是S折交叉验证。S折交叉验证把样本数据随机的分成S份,每次随机的选择S-1份作为训练集,剩下的1份做测试集。当这一轮完成后,重新随机选择S-1份来训练数据。若干轮(小于S)之后,选择损失函数评估最优的模型和参数。
第三种是留一交叉验证,是第二种情况的特例,此时S等于样本数N,这样对于N个样本,每次选择N-1个样本来训练数据,留一个样本来验证模型预测的好坏。此方法主要用于样本量非常少的情况,比如对于普通适中问题,N小于50时,一般采用留一交叉验证。
ROC曲线:对角线对应于“随机猜测”模型,而点(0,1)则对应于将所有正例排在所有反例之前的“理想模型”。
绘图过程:给定m+个正例和m-个反例,根据学习器预测结果对样例进行排序,然后把分类阂值设为最大,即把所有样例均预测为反例,此时真正例率和假正例率均为0,在坐标(0, 0)处标记一个点。然后,将分类阈值依次设为每个样例的预测值,即依次将每个样例划分为正例。设前一个标记点坐标为(x,y),当前若为真正例,则对应标记点的坐标为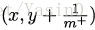
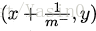
进行学习器的比较时,若一个学习器的ROC曲线被另一个学习器的曲线完全“包住”,则可断言后者的性能优于前者;若两个学习器的ROC曲线发生交叉,则难以一般性地断言两者孰优孰劣.此时如果一定要进行比较,则较为合理的判据是比较ROC曲线下的面积,即AUC (Area Under ROC Curve),