一、主从结构:在一个集群中,会有部分节点充当主服务器的角色,其他服务器都是从服务器的角色,当前这种架构模式叫做主从结构。
主从结构分类:
1、一主多从
2、多主多从
Hadoop中的HDFS和YARN都是主从结构,主从结构中的主节点和从节点有多重概念方式:
1、主节点 从节点
2、master slave
3、管理者 工作者
4、leader follower
Hadoop集群中各个角色的名称:
| 服务 | 主节点 | 从节点 |
| HDFS | NameNode | DataNode |
| YARN | ResourceManager | NodeManager |
二、单点故障
1、如果说宕机的那个节点是从节点,那么整个集群能够继续运行,并且对外提供正常的服务。
2、如果说宕机的那个节点是主节点,那么整个集群就处于宕机状态。
通用的解决方案:高可用
概念:当正在对外提供服务器的主从节点宕机,那么备用的主节点立马上位对外提供服务。无缝的瞬时切换。
1)启动一个拥有文件系统元数据的新NameNode(这个一般不采用,因为复制元数据非常耗时间)
2)配置一对活动-备用(Active-Sandby)NameNode,活动NameNode失效时,备用NameNode立即接管,用户不会有明显中断感觉。
共享编辑日志文件(借助NFS、zookeeper等)
DataNode同时向两个NameNode汇报数据块信息
客户端采用特定机制处理 NameNode失效问题,该机制对用户透明
皇帝驾崩,太子继位。
三、集群的模式
1.单机模式
表示所有的分布式系统都是单机的。
2.为分布式模式
表示集群中的所有角色都分配给了一个节点。
表示整个集群被安装在了只有一个节点的集群中的。
主要用于做快速使用,去模拟分布式的效果。
3.分布式模式
表示集群中的节点会被分配成很多种角色,分散在整个集群中。
主要用于学习测试等等一些场景中。
4.高可用模式
表示整个集群中的主节点会有多个
注意区分:能够对外提供服务的主节点还是只有一个。其他的主节点全部处于一个热备的状态。
正在对外提供服务的主节点:active 有且仅有一个
热备的主节点:standby 可以有多个
工作模式:1、在任意时刻,只有一个主节点是active的,active的主节点对外提供服务
2、在任意时刻,都应至少有一个standby的主节点,等待active的宕机来进行接替
架构模式:就是为了解决分布式集群中的通用问题SPOF
不管是分布式架构还是高可用架构,都存在一个问题:主从结构---从节点数量太多了。最直观的的问题:造成主节点的工作压力过载,主节点会宕机,当前的这种现象是一种死循环
5.联邦模式
表示当前集群中的主从节点都可以有很多个。
1)主节点:可以有很多个的意思是说:同时对外提供服务的主节点有很多个。
重点:每一个主节点都是用来管理整个集群中的一部分
2)从节点:一定会有很多个。
在联邦模式下还是会有问题:
虽然这个集群中的一个主节点的压力被分摊到了多个主节点。但是这个多个主节点依然会有一个问题:SOFP
四、hdfs设计思想
1、分散均匀存储 dfs.blocksize = 128M
2、备份冗余存储 dfs.replication = 3
五、hdfs的概念和特性
1、概念
首先,它是一个文件系统,用于存储文件,通过统一的命名空间——目录树来定位文件
其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色;
2.重要特性
1)HDFS中的文件在物理上是分块存储(block),块的大小可以通过配置参数( dfs.blocksize)来规定,默认大小在hadoop2.x版本中是128M,老版本中是64M
(2)HDFS文件系统会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data
(3)目录结构及文件分块信息(元数据)的管理由namenode节点承担
——namenode是HDFS集群主节点,负责维护整个hdfs文件系统的目录树,以及每一个路径(文件)所对应的block块信息(block的id,及所在的datanode服务器)
(4)文件的各个block的存储管理由datanode节点承担
---- datanode是HDFS集群从节点,每一个block都可以在多个datanode上存储多个副本(副本数量也可以通过参数设置dfs.replication)
(5)HDFS是设计成适应一次写入,多次读出的场景,且不支持文件的修改
六、hdfs的特点和hdfs的组成
1.特点
保存多个副本,且提供容错机制,副本丢失或宕机自动恢复(默认存3份)。
运行在廉价的机器上
适合大数据的处理。HDFS默认会将文件分割成block,,在hadoop2.x以上版本默认128M为1个block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,那内存的负担会很重。
2.组成
HDFS也是按照Master和Slave的结构。分NameNode、SecondaryNameNode、DataNode这几个角色。
NameNode:是Master节点,是大领导。管理数据块映射;处理客户端的读写请求;配置副本策略;管理HDFS的名称空间;
SecondaryNameNode:是一个小弟,分担大哥namenode的工作量;是NameNode的冷备份;合并fsimage和fsedits然后再发给namenode。
DataNode:Slave节点,奴隶,干活的。负责存储client发来的数据块block;执行数据块的读写操作。
热备份:b是a的热备份,如果a坏掉。那么b马上运行代替a的工作。
冷备份:b是a的冷备份,如果a坏掉。那么b不能马上代替a工作。但是b上存储a的一些信息,减少a坏掉之后的损失。
fsimage:元数据镜像文件(文件系统的目录树。)
edits:元数据的操作日志(针对文件系统做的修改操作记录)
namenode内存中存储的是=fsimage+edits。
SecondaryNameNode负责定时默认1小时,从namenode上,获取fsimage和edits来进行合并,然后再发送给namenode。减少namenode的工作量。
七、hdfs的局限性
1)低延时数据访问。在用户交互性的应用中,应用需要在ms或者几个s的时间内得到响应。由于HDFS为高吞吐率做了设计,也因此牺牲了快速响应。对于低延时的应用,可以考虑使用HBase或者Cassandra。
2)大量的小文件。标准的HDFS数据块的大小是64M,存储小文件并不会浪费实际的存储空间,但是无疑会增加了在NameNode上的元数据,大量的小文件会影响整个集群的性能。
前面我们知道,Btrfs为小文件做了优化-inline file,对于小文件有很好的空间优化和访问时间优化。
3)多用户写入,修改文件。HDFS的文件只能有一个写入者,而且写操作只能在文件结尾以追加的方式进行。它不支持多个写入者,也不支持在文件写入后,对文件的任意位置的修改。
但是在大数据领域,分析的是已经存在的数据,这些数据一旦产生就不会修改,因此,HDFS的这些特性和设计局限也就很容易理解了。HDFS为大数据领域的数据分析,提供了非常重要而且十分基础的文件存储功能。
八、hdfs保证可靠性的措施
1)冗余备份
每个文件存储成一系列数据块(Block)。为了容错,文件的所有数据块都会有副本(副本数量即复制因子,课配置)(dfs.replication)
2)副本存放
采用机架感知(Rak-aware)的策略来改进数据的可靠性、高可用和网络带宽的利用率
3)心跳检测
NameNode周期性地从集群中的每一个DataNode接受心跳包和块报告,收到心跳包说明该DataNode工作正常
4)安全模式
系统启动时,NameNode会进入一个安全模式。此时不会出现数据块的写操作。
5)数据完整性检测
HDFS客户端软件实现了对HDFS文件内容的校验和(Checksum)检查(dfs.bytes-per-checksum)。
九、hdfs常用命令
1.启动hdfs集群
start-dfs.sh
2.启动yarn集群
start-yarn.sh
3.查看hdfs系统的根目录
hadoop fs -ls /
4.创建文件夹
hadoop fs -mkdir /a
5.级联创建文件夹
hadoop fs -mkdir -p /aa/bb/cc
6.查看根目录下的所有文件包括子文件夹里面的文件
hadoop fs -ls -R /aa
7.上传文件
hadoop fs -put a.txt /aa
hadoop fs -copyFromLocal words.txt /aa/bb
8.下载文件
hadoop fs -get /aa/word.txt /aa
hadoop fs -copyToLocal /aa/word.txt /aa
9.合并下载
hadoop fs -getmerge /aa/word.txt /aa/bb/word.txt /aa
10.复制
hadoop fs -cp /aa/word.txt /a
11.移动
hadoop fs -mv /a/word.txt /a/b
12.删除文件
hadoop fs -rm /a/bword.txt
13.删除空目录
hadoop fs -rmdir /a/b
14.强制删除
hadoop fs -rm -r /aa/bb
15.从本地剪切到hdfs上
hadoop fs -moveFromLocal /a/word.txt /a/b
16.追加文件
hadoop fs -appendToFile /hello.txt /aa/bb/word.txt
17.查看文件内容
hadoop fs -cat /a/b/word.txt
十、hdfs优缺点
优点
1、可构建在廉价机器上
通过多副本提高可靠性,提供了容错和恢复机制
服务器节点的宕机是常态 必须理性对象
2、高容错性
数据自动保存多个副本,副本丢失后,自动恢复
HDFS的核心设计思想: 分散均匀存储 + 备份冗余存储
3、适合批处理
移动计算而非数据,数据位置暴露给计算框架
海量数据的计算 任务 最终是一定要被切分成很多的小任务进行
4、适合大数据处理
GB、TB、甚至 PB 级数据,百万规模以上的文件数量,10K+节点规模
5、流式文件访问
一次性写入,多次读取,保证数据一致性
缺点:
1、低延迟数据访问
比如毫秒级 低延迟与高吞吐率
2、小文件存取
占用 NameNode 大量内存 150b* 1000W = 15E,1.5G 寻道时间超过读取时间
3、并发写入、文件随机修改
一个文件只能有一个写者 仅支持 append
十一、为什么hdfs不适合存储小文件
这是和HDFS系统底层设计实现有关系的,HDFS本身的设计就是用来解决海量大文件数据的存储.,他天生喜欢大数据的处理,大文件存储在HDFS中,会被切分成很多的小数据块,任何一个文件不管有多小,都是一个独立的数据块,而这些数据块的信息则是保存在元数据中的,在之前的博客HDFS基础里面介绍过在HDFS集群的namenode中会存储元数据的信息,这里再说一下,元数据的信息主要包括以下3部分:
1)抽象目录树
2)文件和数据块的映射关系,一个数据块的元数据大小大约是150byte
3)数据块的多个副本存储地
而元数据的存储在磁盘(1和2)和内存中(1、2和3),而服务器中的内存是有上限的,举个例子:
有100个1M的文件存储进入HDFS系统,那么数据块的个数就是100个,元数据的大小就是100*150byte,消耗了15000byte的内存,但是只存储了100M的数据。
有1个100M的文件存储进入HDFS系统,那么数据块的个数就是1个,元数据的大小就是150byte,消耗量150byte的内存,存储量100M的数据。
所以说HDFS文件系统不适用于存储小文件。
十二、hdfs心跳机制
1、DataNode启动的时候会向NameNode汇报信息,就像钉钉上班打卡一样,你打卡之后,你领导才知道你今天来上班了,同样的道理,DataNode也需要向NameNode进行汇报,只不过每次汇报的时间间隔有点短而已,默认是3秒中,DataNode向NameNode汇报的信息有2点,一个是自身DataNode的状态信息,另一个是自身DataNode所持有的所有的数据块的信息。而DataNode是不会知道他保存的所有的数据块副本到底是属于哪个文件,这些都是存储在NameNode的元数据中。
2、按照规定,每个DataNode都是需要向NameNode进行汇报。那么如果从某个时刻开始,某个DataNode再也不向NameNode进行汇报了。 有可能宕机了。因为只要通过网络传输数据,就一定存在一种可能: 丢失 或者 延迟。
3、HDFS的标准: NameNode如果连续10次没有收到DataNode的汇报。 那么NameNode就会认为该DataNode存在宕机的可能。
4、DataNode启动好了之后,会专门启动一个线程,去负责给NameNode发送心跳数据包,如果说整个DataNode没有任何问题,但是仅仅只是当前负责发送信条数据包的线程挂了。NameNode会发送命令向这个DataNode进行确认。查看这个发送心跳数据包的服务是否还能正常运行,而为了保险起见,NameNode会向DataNode确认2遍,每5分钟确认一次。如果2次都没有返回 结果,那么NameNode就会认为DataNode已经GameOver了!!!
最终NameNode判断一个DataNode死亡的时间计算公式:
timeout = 10 * 心跳间隔时间 + 2 * 检查一次消耗的时间
心跳间隔时间:dfs.heartbeat.interval 心跳时间:3s
检查一次消耗的时间:heartbeat.recheck.interval checktime : 5min
最终结果默认是630s。
十二、hdfs安全模式
1、HDFS的启动和关闭都是先启动NameNode,在启动DataNode,最后在启动secondarynamenode。
2、决定HDFS集群的启动时长会有两个因素:
1)磁盘元数据的大小
2)datanode的节点个数
当元数据很大,或者 节点个数很多的时候,那么HDFS的启动,需要一段很长的时间,那么在还没有完全启动的时候HDFS能否对外提供服务?
在HDFS的启动命令start-dfs.sh执行的时候,HDFS会自动进入安全模式
为了确保用户的操作是可以高效的执行成功的,在HDFS发现自身不完整的时候,会进入安全模式。保护自己。
在正常启动之后,如果HDFS发现所有的数据都是齐全的,那么HDFS会启动的退出安全模式
3、在安全模式下:
如果一个操作涉及到元数据的修改的话。都不能进行操作
如果一个操作仅仅只是查询。那是被允许的。
所谓的安全模式,仅仅只是保护namenode,而不是保护datanode
十三、hdfs副本存放策略
第一副本:放置在上传文件的DataNode上;如果是集群外提交,则随机挑选一台磁盘不太慢、CPU不太忙的节点上;
第二副本:放置在于第一个副本不同的机架的节点上;
第三副本:与第二个副本相同机架的不同节点上;
如果还有更多的副本:随机放在节点中;
十四、hdfs负载均衡
负载均衡理想状态:节点均衡、机架均衡和磁盘均衡。
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,例如:当集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值。当数据不平衡时,Map任务可能会分配到没有存储数据的机器,这将导致网络带宽的消耗,也无法很好的进行本地计算。
当HDFS负载不均衡时,需要对HDFS进行数据的负载均衡调整,即对各节点机器上数据的存储分布进行调整。从而,让数据均匀的分布在各个DataNode上,均衡IO性能,防止热点的发生。进行数据的负载均衡调整,必须要满足如下原则:
- 数据平衡不能导致数据块减少,数据块备份丢失
- 管理员可以中止数据平衡进程
- 每次移动的数据量以及占用的网络资源,必须是可控的
- 数据均衡过程,不能影响namenode的正常工作
数据均衡过程的核心是一个数据均衡算法,该数据均衡算法将不断迭代数据均衡逻辑,直至集群内数据均衡为止。
步骤分析如下:
- 数据均衡服务(Rebalancing Server)首先要求 NameNode 生成 DataNode 数据分布分析报告,获取每个DataNode磁盘使用情况
- Rebalancing Server汇总需要移动的数据分布情况,计算具体数据块迁移路线图。数据块迁移路线图,确保网络内最短路径
- 开始数据块迁移任务,Proxy Source Data Node复制一块需要移动数据块
- 将复制的数据块复制到目标DataNode上
- 删除原始数据块
- 目标DataNode向Proxy Source Data Node确认该数据块迁移完成
- Proxy Source Data Node向Rebalancing Server确认本次数据块迁移完成。然后继续执行这个过程,直至集群达到数据均衡标准
十五、hdfs写过程
术语:
1、使用 HDFS 提供的客户端 Client,向远程的 namenode 发起 RPC 请求
2、namenode 会检查要创建的文件是否已经存在,创建者是否有权限进行操作,成功则会 为文件创建一个记录,否则会让客户端抛出异常;
3、当客户端开始写入文件的时候,客户端会将文件切分成多个 packets,并在内部以数据队列“data queue(数据队列)”的形式管理这些 packets,并向 namenode 申请 blocks,获 取用来存储 replicas 的合适的 datanode 列表,列表的大小根据 namenode 中 replication 的设定而定;
4、开始以 pipeline(管道)的形式将 packet 写入所有的 replicas 中。客户端把 packet 以流的 方式写入第一个 datanode,该 datanode 把该 packet 存储之后,再将其传递给在此 pipeline 中的下一个 datanode,直到最后一个 datanode,这种写数据的方式呈流水线的形式。
5、最后一个 datanode 成功存储之后会返回一个 ack packet(确认队列),在 pipeline 里传递 至客户端,在客户端的开发库内部维护着"ack queue",成功收到 datanode 返回的 ack packet 后会从"data queue"移除相应的 packet。
6、如果传输过程中,有某个 datanode 出现了故障,那么当前的 pipeline 会被关闭,出现故 障的 datanode 会从当前的 pipeline 中移除,剩余的 block 会继续剩下的 datanode 中继续 以 pipeline 的形式传输,同时 namenode 会分配一个新的 datanode,保持 replicas 设定的 数量。
7、客户端完成数据的写入后,会对数据流调用 close()方法,关闭数据流;
8、只要写入了 dfs.replication.min(最小写入成功的副本数)的复本数(默认为 1),写操作 就会成功,并且这个块可以在集群中异步复制,直到达到其目标复本数(dfs.replication 的默认值为 3),因为 namenode 已经知道文件由哪些块组成,所以它在返回成功前只需 要等待数据块进行最小量的复制。
口语:
1、客户端发起请求:hadoop fs -put hadoop.tar.gz /
客户端怎么知道请求发给那个节点的哪个进程?
因为客户端会提供一些工具来解析出来你所指定的HDFS集群的主节点是谁,以及端口号等信息,主要是通过URI来确定,
url:hdfs://hadoop1:9000
当前请求会包含一个非常重要的信息: 上传的数据的总大小
2、namenode会响应客户端的这个请求
namenode的职责:
1 管理元数据(抽象目录树结构)
用户上传的那个文件在对应的目录如果存在。那么HDFS集群应该作何处理,不会处理
用户上传的那个文件要存储的目录不存在的话,如果不存在不会创建
2、响应请求
真正的操作:做一系列的校验,
1、校验客户端的请求是否合理
2、校验客户端是否有权限进行上传
3、如果namenode返回给客户端的结果是 通过, 那就是允许上传
namenode会给客户端返回对应的所有的数据块的多个副本的存放节点列表,如:
file1_blk1 hadoop02,hadoop03,hadoop04
file1_blk2 hadoop03,hadoop04,hadoop05
4、客户端在获取到了namenode返回回来的所有数据块的多个副本的存放地的数据之后,就可以按照顺序逐一进行数据块的上传操作
5、对要上传的数据块进行逻辑切片
切片分成两个阶段:
1、规划怎么切
2、真正的切物理切片: 1 和 2
逻辑切片: 1
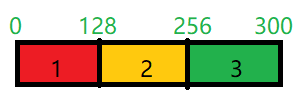
file1_blk1 : file1:0:128
file1_blk2 : file1:128:256
逻辑切片只是规划了怎么切
6、开始上传第一个数据块
7、客户端会做一系列准备操作
1、依次发送请求去连接对应的datnaode
pipline : client - node1 - node2 - node3
按照一个个的数据包的形式进行发送的。
每次传输完一个数据包,每个副本节点都会进行校验,依次原路给客户端
2、在客户端会启动一个服务:用户就是用来等到将来要在这个pipline数据管道上进行传输的数据包的校验信息
客户端就能知道当前从clinet到写node1,2,3三个节点上去的数据是否都写入正确和成功
8、clinet会正式的把这个快中的所有packet都写入到对应的副本节点
1、block是最大的一个单位,它是最终存储于DataNode上的数据粒度,由dfs.block.size参数决定,2.x版本默认是128M;注:这个参数由客户端配置决定;如:System.out.println(conf.get("dfs.blocksize"));//结果是134217728
2、packet是中等的一个单位,它是数据由DFSClient流向DataNode的粒度,以dfs.write.packet.size参数为参考值,默认是64K;注:这个参数为参考值,是指真正在进行数据传输时,会以它为基准进行调整,调整的原因是一个packet有特定的结构,调整的目标是这个packet的大小刚好包含结构中的所有成员,同时也保证写到DataNode后当前block的大小不超过设定值;
如:System.out.println(conf.get("dfs.write.packet.size"));//结果是65536
3、chunk是最小的一个单位,它是DFSClient到DataNode数据传输中进行数据校验的粒度,由io.bytes.per.checksum参数决定,默认是512B;注:事实上一个chunk还包含4B的校验值,因而chunk写入packet时是516B;数据与检验值的比值为128:1,所以对于一个128M的block会有一个1M的校验文件与之对应;
如:System.out.println(conf.get("io.bytes.per.checksum"));//结果是512
9、clinet进行校验,如果校验通过,表示该数据块写入成功
10、重复7 8 9 三个操作,来继续上传其他的数据块
11、客户端在意识到所有的数据块都写入成功之后,会给namenode发送一个反馈,就是告诉namenode当前客户端上传的数据已经成功。
十六、hdfs读过程
1、客户端调用FileSystem 实例的open 方法,获得这个文件对应的输入流InputStream。
2、通过RPC 远程调用NameNode ,获得NameNode 中此文件对应的数据块保存位置,包括这个文件的副本的保存位置( 主要是各DataNode的地址) 。
3、获得输入流之后,客户端调用read 方法读取数据。选择最近的DataNode 建立连接并读取数据。
4、如果客户端和其中一个DataNode 位于同一机器(比如MapReduce 过程中的mapper 和reducer),那么就会直接从本地读取数据。
5、到达数据块末端,关闭与这个DataNode 的连接,然后重新查找下一个数据块。
6、不断执行第2 - 5 步直到数据全部读完。
7、客户端调用close ,关闭输入流DF S InputStream。