这篇博客专门介绍一下MarkerMapper的实现原理,不了解MarkerMapper的可以先看一下我的上一篇博客:基于ArUco的视觉定位(三)。
Paper:Mapping and localization from planar markers (很重要)
这不是一篇翻译,而是博主对上述论文的总结,理解之中难免有不到位的地方,不足之处还请参看原文。
〇、MarkerMapper干了啥?
这里再陈述一遍MarkerMapper到底干了些什么事:
- 根据我们指定的空间中任意一个ID的marker,MakerMapper将整个空间中任意分布的所有marker以指定marker为参考坐标系构建marker的分布图,生成一个二维码分布文件。二维码的分布体现在每个marker的四个角点相对指定marker坐标系的三维坐标,即得到所有marker在参考世界坐标系下的位姿分布。其实最重要的也是我们最想得到的,就是所有marker的角点在世界坐标系下的三维坐标,因为有了这些角点的三维坐标,我们就可以用PnP算法估计相机的位姿。
- 在构建二维码分布图的过程中,MarkerMapper同时对相机的运行轨迹进行了估计,记录了关键帧在参考世界坐标系下的位姿。
- 除了优化了二维码的位姿分布和相机的运行轨迹,MarkerMapper还优化了相机的内参数。
- MakerMapper为我们生成了一个包含二维码位姿分布以及关键帧轨迹的可视化点云图。
一、基本原理
1、基本思路
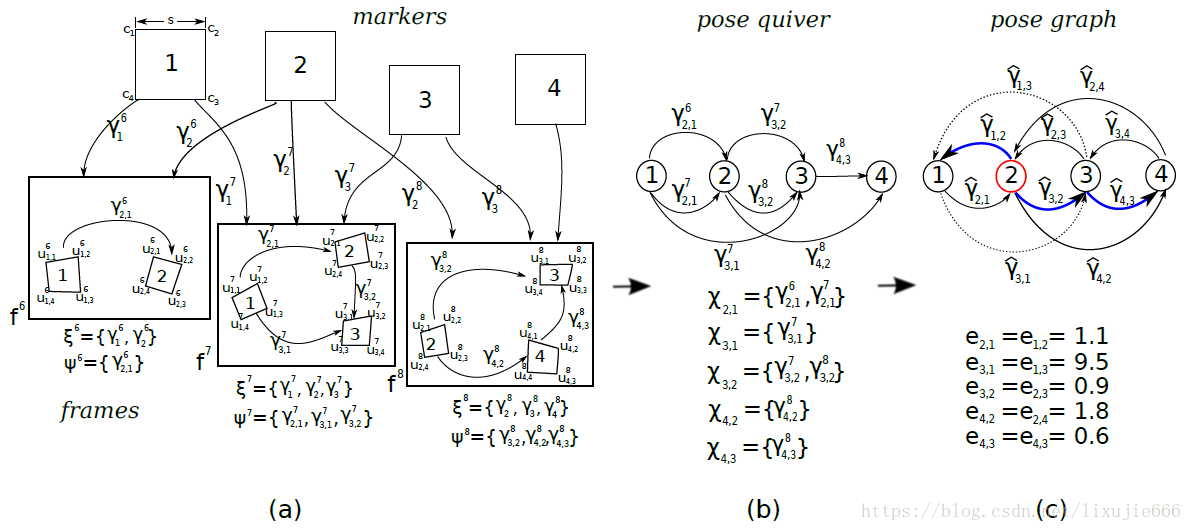
如上图(a)所示,当第
帧图像中同时检测到marker1和marker2时,我们可以得到相机当前与marker1之间的位姿关系
、与marker2之间的位姿关系
,由此我们就可以在
帧下求得marker1与marker2之间的位姿变换矩阵
;当第
帧图像中同时检测到marker1、marker2和marker3时,我们可以得到相机当前与marker1之间的位姿关系
、与marker2之间的位姿关系
、以及与marker3之间的位姿关系
,从而我们可以在
帧下求得marker1与marker2之间的位姿变换矩阵
、marker1与marker3之间的位姿变换矩阵
、marker2与marker3之间的位姿变换矩阵
。同理,当第
帧图像中同时检测到marker{
,
,
,
}时,我们可以求得在当前帧下各marker之间的位姿变换矩阵
、
、
、
。
按照上面的思路,我们可以得到空间中所有二维码任意两两之间的相对位姿关系。指定其中一个二维码坐标系作为参考世界坐标系,就可以求得所有二维码相对于参考坐标系的位姿,进而得到所有二维码的角点在世界坐标系下的三维坐标。
道理我们都懂,但实现起来远非这么简单。
理论上,在相机经过若干帧观察到所有marker后,我们就可以推算出任意marker间的相对位姿关系,但由于观测噪声的存在,比如光线不佳、相机移动过快、分辨率较低、对焦不清等等原因,总而言之,这种简单地推算出来的关系是非常不准确的,存在极大的累积误差。所以,如何在有噪声的观测数据下精确地计算出每个marker在世界坐标系下的角点坐标,才是我们真正要解决的问题。
2、核心问题
经过上面的分析,我们知道,问题的关键在于如何在相机不准确的观测数据下估计出二维码准确的位姿分布。了解SLAM的同学应该都知道,要解决这个问题最终不得不使出我们的杀手锏——非线性优化。好吧,MarkerMapper最终也要归结到一个优化问题上,基本手段就是最小化重投影误差:
解释一下这个重要的公式:
- 为已知量,表示marker 在该marker坐标系下角点 的三维坐标。通常,在marker边长已知为 的情况下,每个marker的4个角点在自身坐标系下的坐标分别为 。
- 为待估计量,表示从marker坐标系到世界坐标系的齐次变换矩阵,这里的世界坐标系是指参考的marker坐标系。 是将marker 的第 个角点有marker坐标系转换到世界坐标系下表示。
- 为待估计量,表示从世界坐标系到相机坐标系的齐次变换矩阵,也即相机的外参。
- 为待估计量,表示相机的内参矩阵。
- 函数 表示marker 的角点 从三维空间坐标到像素坐标的一种投影,它先将角点 转换到世界坐标系,再转换到相机坐标系,最后转换到像素坐标系。所以, 表示的角点像素坐标是根据待估计量计算出来的,称为重投影。
- 为观测量,表示在第 帧下观察到的marker 第 个角点真实的像素坐标,由于各种原因产生的观测噪声,真实的并不代表就是准确的。-
所以,
表示在第
帧下marker
4个角点的重投影误差平方和,我们的最终目的是估计出最优的
、
、
使得所有的
最小,即:
将变换矩阵
用它的李代数形式
代替,写成如下形式:
其中, , ,这里 、 均为行向量。
未完成。。。