标题:Line as a Visual Sentence:Context-aware Line Descriptor for Visual Localization
作者:Sungho Yoon1 and Ayoung Kim2∗
摘要

在机器人以及计算机视觉领域,除了通过使用图像匹配的特征点计算多视图几何来求解问题,还可以通过线特征计算,因为线特征可以为其提供多余的约束。尽管基于CNN的直线特征描述子在视点变化以及动态环境下的应用很有潜力,但是我们认为CNN在直线长度变化时有着天然的劣势,因为CNN需要将变化的直线长度用维度固定的描述子描述。本文中,我们提出了Line-Transformers方法可以有效地解决直线长度变化的问题。受自然语言处理(NLP)启发,我们将直线段视作语句,将特征点视作词汇。通过动态观测直线上的可描述点,我们的描述子对于长度可变的直线表现良好。我们还提出了直线签名网络(line signature networks),可以将直线的几何属性共享给其相邻的直线。并且我们还用本文提出的直线特征描述与匹配方法实现了基于点线的定位(PL-Loc)。我们证明结合我们提出的直线特征可以很好地提高基于特征点的视觉定位效果。我们从单应性估计与视觉定位两方面证明了算法的有效性。
项目开源地址: https://github.com/yosungho/LineTR
Line Transformers
1、Line Tokenizer:作者借鉴了NLP中相关思路。在NLP中把一个句子划分成多个词组的过程称为tokenization 。作者将一条直线看作NLP中的一个语句,使用特征点将一条直线划分为不同的线段,提取的特征点表示为:pi = (x, y, c)i ,其中x,y代表位置,c代表置信度。两相邻点之间区间的长度用v表示,那么一条直线上的特征点数量为n = ⌊l/v⌋+1 ,其中,l表示直线的长度。具体过程如下图所示:

个人理解,使用NLP对应的神经网络训练时需要将直线的信息向量化,而上图就是这个向量化的过程,这样直线特征就抽象成NLP网络对应的特征了。
2、Transformer :作者使用Transformers来建立直线特征描述子模型。Transformer的编码器由两部分组成:MSA层(multi-head self-attention layers )和MLP层。将Transformer堆叠L次便可以得到直线的特征描述子,如公式1所示:
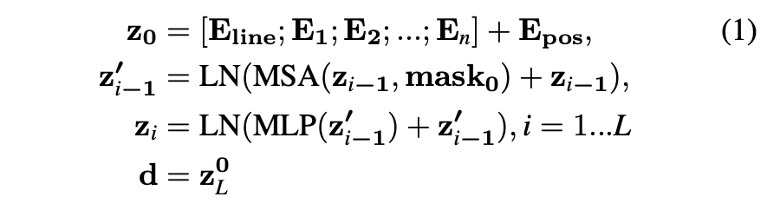
公式中z0为Transformers的输入,Eline为描述子的初始状态;En表示第n个特征点的描述向量;Epos表示每个特征点的位置信息;为了解决直线特征长度不同的问题,加入mask0来去除相关性比较低的特征点;d即为得到的直线特征描述子。
Line Signature Networks

除了建立单条直线特征描述,作者设计了直线签名网络,根据直线的位置、角度将直线聚成一簇,并且相邻直线的信息(位置、角度)通过信息传递网络共享。传递公式如下所示:


Sublines to Keylines

由于Transformers有最大tokens数量限制,对于直线特征来说就是会限制直线上的最大特征点数,也即会限制最大直线长度。为了解决这个问题,本文提出了Sublines,Keylines的概念。原本的直线成为Keyline,当直线长度超过最大长度限制时,就会把原本的直线切分成多个子直线即Subline,同时设计了邻接矩阵(Adjacency Matrices )可以将Subline描述子距离矩阵与Keyline距离矩阵转换。如下所示:


Loss Function

代价函数的设计采用了半硬负抽样策略(semi-hard negative sampling strategy ),代价函数设计如下:
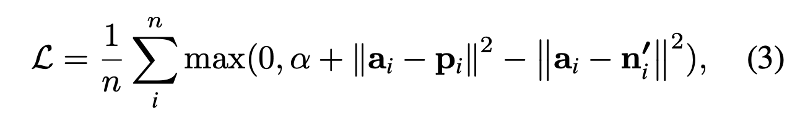
其中,ai为锚描述子(个人理解为当计算匹配距离的描述子),Pi为正描述子(个人理解为匹配上的比较相似的描述子),ni为负描述子(个人理解为匹配不上的描述子),从损失函数中可以看到,就是使匹配上的描述子之间的距离最小,未匹配上的描述子之间的距离最大。
实验结果

作者通过单应性估计,视觉定位的效果两方面来评估算法能力。对比的算法包括 SuperPoint,LBD,LLD,WLD,SOLD。



通过以上各个结果可以证明本问提出的算法在在指标上普遍优于其它对比算法。
总结
本文提出了一种基于NLP思路的直线特征描述方法,并且通过实验量化验证了在单应性估计,视觉定位方面优于其它直线匹配算法,且本方法已经在github上开源,对直线匹配感兴趣的同学可以去看下。
Abstract

Along with feature points for image matching, line features provide additional constraints to solve visual geometric problems in robotics and computer vision (CV). Although recent convolutional neural network (CNN)-based line descriptors are promising for viewpoint changes or dynamic environments, we claim that the CNN architecture has innate disadvantages to abstract variable line length into the fixed-dimensional descriptor. In this paper, we effectively introduce Line-Transformers dealing with variable lines. Inspired by natural language processing (NLP) tasks where sentences can be understood and abstracted well in neural nets, we view a line segment as a sentence that contains points (words). By attending to well-describable points on aline dynamically, our descriptor performs excellently on variable line length. We also propose line signature networks sharing the line's geometric attributes to neighborhoods. Performing as group descriptors, the networks enhance line descriptors by understanding lines' relative geometries. Finally, we present the proposed line descriptor and matching in a Point and Line Localization (PL-Loc). We show that the visual localization with feature points can be improved using our line features. We validate the proposed method for homography estimation and visual localization.