版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u013555719/article/details/82182457
5.2自然语言处理
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.6 Word2Vec
- Word2Vec相对于原先介绍的词嵌入的方法来说更加的简单快速。
Mikolov T, Chen K, Corrado G, et al. Efficient Estimation of Word Representations in Vector Space[J]. Computer Science, 2013.
Skip-grams
- 假设在训练集中给出了如下的例句:“I want a glass of orange juice to go along with my cereal” 抽取上下文与目标词配对来构造一个监督学习的问题。
- 上下文不一定总是目标单词之前离得最近的四个单词,或者里的最近的n个单词,可以随机的选择句子中的一个单词作为上下文词。例如选择orange作为上下文单词,然后 随机在一定词距内选定另一个词,在上下文单词前后的五到十个单词随机选择目标词
| Content | Target |
|---|---|
| orange | juice |
| orange | glass |
| orange | my |
- 于是构造一个监督学习问题,给定上下文单词,在这个词正负十个词距中或者正负五个词距中随机选择某个目标词。
- 这显然不是一个简单的学习问题,因为在单词orange的正负十个词距之间会有很多不同的单词,但是构造这个监督学习问题的目标并不是要解决这个监督学习问题本身,而是想要使用这个监督学习来学到一个好的词嵌入模型
Skip-grams model
- 此处使用的是一个1W词的词汇表,有时训练使用的词汇表会超过100W词,我们想要解决的有监督学习问题是学习一种对应关系,即从Content出发对Target的映射。
假设在训练集中的一个实例是“Orange”–>”Juice”的对应,而Content“Orange”对应字典中的第6257个单词,Target“Juice”对应字典中的第4834个单词。
- 使用One-hot向量表示的方式表示出“Orange”和“Juice”即 和
- 使用E表示词嵌入矩阵,使用 表示词嵌入向量Context,使用 表示词嵌入向量Target
- 则具有式子 ,
将词嵌入向量输入到一个Softmax单元
对于Softmax单元,其计算的是已知上下文的情况下目标词出现的概率
- 其中
是一个与输出t有关的参数即表示和标签t相符的概率
- 则此时的损失函数可表示为:
其中 表示Target的真实值,而 表示模型得出的Taret的预测值。
- y是训练集中的真实值即 y是一个与词汇表中词汇数量相同维度的one-hot向量,例如:如果y表示juice,其在词汇表的序号是4834,且词汇表中总共有1W个单词,则y为一个1W维度的向量并且第4834维的值为1其余维度均为0。
类似的 是一个从softmax单元输出的具有1W维度的向量表示所有可能目标词的概率。
矩阵E会有很多参数,其对应了词嵌入向量 的值,softmax单元也有参数 ,如果通过反向传播算法优化损失函数L,你就会得到一个很好的嵌入向量集。此就称之为–skip-gram 模型。
skip-gram模型将一个词汇作为输入,跳过(skip)一些单词并预测这个输入词从左数或从右数的某个词。
hierarchical softmax classifier 分级softmax 分类器
- 但是此方法需要使用softmax分类函数,每次计算softmax的分母的时候需要对输出向量中的1W个词做计算,而这个求和操作是十分耗时的。而且词汇表中的单词数量越多,则softmax操作耗时越多。
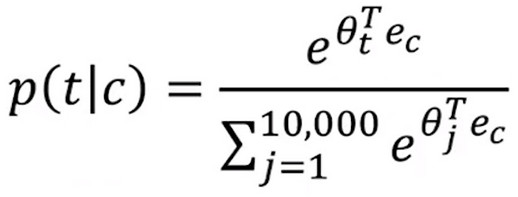
- 为了解决这个问题,引入了 hierarchical softmax classifier 分级softmax 分类器 意思是不是一次性确定属于1W类中的哪一类,而是采用一种 类似二分查找的方法区分词嵌入向量所在类别。
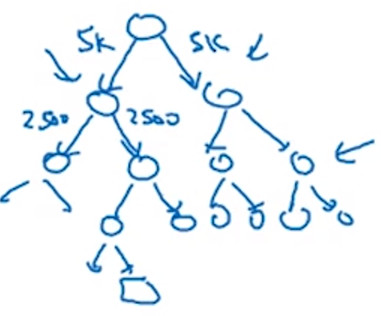
- 当然,为了节省查找的时间和计算资源,将常见词汇构造在查找树的靠近根部的节点,而不常见的词汇则构造在查找树更深的节点上。
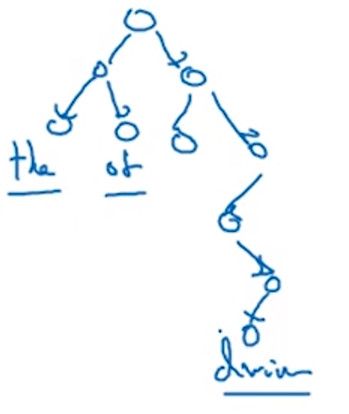
How to sample the context C 如何对上下文进行采样
- 对上下文进行均匀而随机的采样,而目标Target在上下文的前后5-10个区间中进行均匀而随机的采样。
- 这样做,你会发现像词汇 the of a and to 诸如此类介词在Context和Target中出现的相当频繁。而像 orange apple durain 这种有实际意义的词汇不会那么频繁的出现。
- 使用启发式的方式在常用词和不常用的词汇之间分别进行采样。
补充
- 这就是本节介绍的Word2Vec中的skip-gram模型,在参考文献提及的论文原文中,实际上提到了两个不同版本的Word2Vec模型, skip-gram 只是其中之一。还有另外一个模型称为 CBOW–连续词袋模型。
- CBOW–连续词袋模型 获得中间词两边的上下文,然后用周围的词来预测中间的词,这个模型也十分的有效也有其优点和缺点。
- skip-gram 模型的关键问题在于: Softmax 步骤计算成本非常昂贵,需要在分母中对词汇表中的所有词进行求和