Histogram Comparison
一. Introduction
几何上的线索 (Geometrical cues)是最靠谱的一种方式来估计一个物体的身份。毕竟而言,我们可以从一张黑色或白色的图片中来识别出里面的椅子,不需要任何的颜色和纹理。然而这种方法并不经常适用。在自然界中有很多的例子表明通过颜色可以很好的确定物体的种类,如水果(Fruits),矿物质(Minerals)等等。在我们的文明中,具有特色的颜色经常被用来当做商标(Trademark and Logo)。对于 Google 和 Facebook 来说,前者的 logo 由蓝色、红色、黄色和绿色组成,但是后者主要是蓝色。
仅仅通过颜色来确定物体在第一眼看来感觉很疯狂。然而,卷积神经网络(Convolutional Neural Network)作为最强大的分类器之一也同样的利用了颜色的信息。通过用 RGB 图而不是灰度图(Greyscale)来训练神经网络,会有很大的不同。更进一步的,我们的大脑也被进化到利用颜色信息来判断物体。因此,颜色信息能够使视觉系统(Visual System)分析复杂的图片更有效,在一定程度上提升了物体识别的效率。心理学上的实验(Psychological Experients)展示了颜色信息在记忆(Memorisation)和 识别(Recognition)的巨大贡献(Wichmann and Sharpe,2002)。直方图交叉算法(Histogram Intersection Algorithm)使用了颜色信息来识别物体。
二. The histogram intersection algorithm
直方图交叉算法(Histogram Intersection Algorithm)由 Swain 和 Ballard 在他们的 “Color Indexing”文章提出。当颜色信息在物体识别时有较大权重的时候,这个算法非常可靠的。直方图交叉算法并不需要将物体从其背景精确的分离开来,且对在前景遮住物体(Occluding objects in the foreground)具有一定的鲁棒性。上述提到的直方图是数字图像中像素值的分布且以图像的形式(graphical representation)表示出来,像素值分布是用来表现颜色信息的一种方式,在HVS模型中,像素值分布又代表着颜色的饱和度(saturation)。在不同视角、尺度和遮挡条件下,当缓慢移动时,直方图(histogram)对变化有一定的鲁棒性。
首先给出该算法的数学基础。给定输入图片的直方图 (camera frame) 和 模型 的直方图(object frame),每一个都包含这 n 个bins,交叉(intersection)定义为:
其中, 和 分别代表第j个bin 的像素数量,是一个集合。min () 函数以 和 的对应的某个 bin 的像素数量为输入参数,然后返回俩者中最小的像素数量(这里的bin代表一个范围内像素值)。交叉的结果得到的是,与输入图像中具有相同颜色(bin)的来自模型(model)的对应像素的数量。
为了对结果进行单位化,我们将结果分别除以模型直方图(model histogram)中每个bin的像素数量并使其位于0和1之间:
因此,我们所需要的是待识别的物体的像素直方图。当一个带有物体的图片被当做输入的时候,为了识别该物体,我们可以跟所有存储的模型(stored models)计算直方图交叉(histogram instesection),分数最高的就是最佳匹配的。
三.Implementation in Python
在Python中我们可以很容易的对直方图进行操作,例如 numpy 有函数 numpy.histogram() 和 OpenCV有函数 cv2.calcHist()。 为了将直方图画出,我们可以使用 matplotlib 函数 matplotlib.pyplot.hist()。这些函数中的最主要的输入参数是矩阵(或者图片),bins的数量和bins大小的范围(最低或者最高)。在OpenCV俩个直方图通过函数cv2.compareHist()来进行比较,该函数输入参数为直方图和比较的方法。在可能的比较方法中,CV_COMP_INTERSECT是用来计算直方图交叉(histogram intersection)的方法。Numpy并没有内置(built-in)函数用来比较直方图,但是我们可以通过几行代码就完成这个函数。首先我们需要创建俩个直方图:
mu_1 = -4 #第一个分布的均值
mu_2 = 4 #第二个分布的均值
data_1 = np.random.normal(mu_1, 2.0, 1000) #以均值为-4,方差为2.0,随机产生1000个数
data_2 = np.random.normal(mu_2, 2.0, 1000) #以均值为4,方差为2.0,随机产生1000个数
hist_1, _ = np.histogram(data_1, bins=100, range=[-15, 15]) #分成100个bins,bins包含的值的范围在-15到15之间
hist_2, _ = np.histogram(data_2, bins=100, range=[-15, 15]) #分成100个bins,bins包含的值的范围在-15到15之间下面的代码从俩个不同的正态分布(mean=mu_1,mu_2; std=2.0)采样来生成俩个直方图。这俩个直方图分别有100 bins, 其包含的值在-15到15之间。一旦我们拥有俩个numpy类型的直方图之后,我们可以通过以下函数来比较他们:
def return_intersection(hist_1, hist_2):
minima = np.minimum(hist_1, hist_2)
intersection = np.true_divide(np.sum(minima), np.sum(hist_2))
return intersection通过以上代码,我们可以得到俩个直方图分别从 和 中生成,对其交叉部分进行可视化,如下所示:

在上图中,x轴方向上有100个 bins,y轴代表落入每个bin的像素的数量。诸如第一个 bin 的值为[-15.0,-15.15), 第二个bin 的值为 [-15.15,-15.30) 等等。上图中红色和蓝色交叉部分就是我们想要的。容易得当俩个分布很相似时交叉部分会较大。在上一个例子中,交叉部分的值为0.035。如果我们选择的正态分布为
和
, 我们能得到更大的交叉部分。
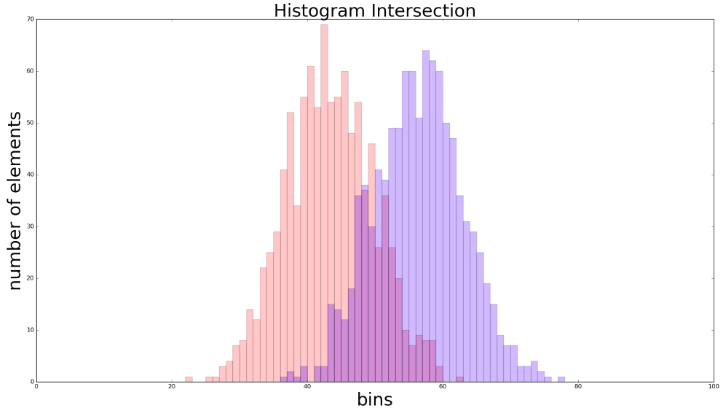
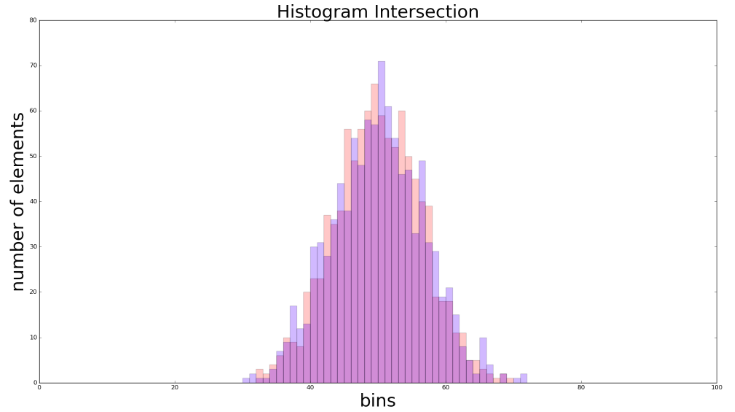
新的交叉值为0.329。在较为极端的例子中,我们令分布拥有相同的均值和标准差
, 我们可以得到接近于1的交叉值(在这个例子中为0.89),如下图所示:
四. Superheroes classification
如下图所示,你应该应该意识到超级英雄有容易区分的颜色,你可以从颜色上看到很多不同处:

在这个例子中我们使用 deepgaze 颜色分类器来识别8个超级英雄,首先我们导入一些库和 deepgaze 模块,然后我们可以通过调用函数 HistogramColorClassifier() 来初始化分类对象(initialise the classifier objec)。作为参数,我们可以给定通道的数量(在RGB图片中通道数是3),然后是每个通道bins的数量,同时每个bin所包含的像素值的范围,如下代码所示:
import cv2
import numpy as np
from deepgaze.color_classification import HistogramColorClassifier
my_classifier = HistogramColorClassifier(channels=[0, 1, 2],
hist_size=[128, 128, 128],
hist_range=[0, 256, 0, 256, 0, 256],
hist_type='BGR')现在我们需要导入模型。可以通过OpenCV中的函数cv2.imread() 读取图片然后调用 deepgaze中的 addModelHistogram()函数,你需要为需要存储的模型重复这个操作。在下面的案例中,导入了8个模型,分别是[Flash, Batman, Hulk, Superman, Capt. America, Wonder Woman, Iron Man, Wolverine]。 对于每个模型需要调用addModelHistogram() 函数,如下所示:
model_1 = cv2.imread('model_1.png') #Flash Model
my_classifier.addModelHistogram(model_1)
model_2 = cv2.imread('model_2.png') #Batman Model
my_classifier.addModelHistogram(model_2)在”Color Indexing“文章中,作者推荐从背景中将模型裁剪出来。这个操作较为麻烦但是你可能会获得比较好的结果。在 deepgaze 库中,你可以找到10张不一样的被裁剪好的图片,每一个模型都是从背景中把前景提取出来的。

现在可以测试这个分类器的效果了。对于第一次尝试我使用Batman的图片。在用 OpenCV 读入图片之后,使它和模型进行对比,可以简单的通过 returnHistogramComparisonArray() 函数来完成,如下所示:
image = cv2.imread('image_2.jpg') #Batman Test
comparison_array = my_classifier.returnHistogramComparisonArray(image,
method="intersection")函数 returnHistogramComparisionArray()返回一个numpy类型的矩阵,该矩阵包含着图片和模型进行交叉运算之后的结果。在这个函数中,我们可以定义比较的方法,intersection 代表我们在这篇文章中所代表的方法。另外一个可用的方法是 correlation (Pearson Correlation Coefficient),chisqr(Chi-Square)和 bhattacharyya(an implementation of the Bhattacharyya distance measure)。下面这个表格显示了各种方法返回的俩个直方图的距离值(distance value returned by each method),包括完整匹配,半匹配和错误匹配:

为了检查比较的结果,我们可以将值输出来:
0.00818883 #Flash
0.55411926 #Batman
0.12405966 #Hulk
0.07735263 #Superman
0.34388389 #Capt. America
0.12672027 #Wonder Woman
0.09870308 #Iron Man
0.2225694 #Wolverine你可以看到第二个值 (~0.55)是最高的一个,意味着第二个模型(Batman)跟输入图片是最好的一个匹配。这个值是原始像素的距离,为了得到概率分布,我们需要单位化这个矩阵(输出的概率结果),我们将矩阵内的值除以所有值的和:
probability_array = comparison_array / np.sum(comparison_array)这个操作的结果为新的向量,且所有值的和为1:
0.00526411 #Flash
0.35621003 #Batman
0.07975051 #Hulk
0.04972536 #Superman
0.22106232 #Capt. America
0.08146086 #Wonder Woman
0.06345029 #Iron Man
0.14307651 #Wolverine现在我们可以说第二个模型拥有35.6%的概率是正确匹配的。

由于Batman有很多种颜色,容易区分,因此较为容易得到较高的置信值。让我们在较为复杂的情况下测试分类器。使用 Ironman 图片,但是 Ironman 稍微向右转了而且没有带头盔,调用returnHistogramComparisonArray()然后单位化其输出,然后使用matplotlib将其概率输出:

同样的在这个例子中,我们得到了 26.6%的好成绩。因此我们可以说,直方图交叉(Histogram Intersection)当物体视角变化很小且背景有些许噪声的时候是很可靠的。如果你想要测试更多的图片可以从deepgaze repository 下载。对于所有的图片中,值最高的就是为匹配上的超级英雄。在 Swain 和 Ballard 的文章里面,在包含66中模型的数据上测试了histogram intersection。 对于66个物体的数据集,在32次中,得到了29次的最佳匹配,其他3次对应的模型分数排在第2,。如果你有机会测试在更大的数据集上测试模型,希望你能分享你的结果!
原文链接:https://mpatacchiola.github.io/blog/2016/11/12/the-simplest-classifier-histogram-intersection.html
deepgaze链接: https://github.com/mpatacchiola/deepgaze