在此我们以MSE作为代价函数:

其中, C表示代价 函数 ,x表示样本, y表示实际值, 表示实际值, 表示实际值, a表示输出值, 表示输出值, n表示样本的总数。为简单起见 表示样本的总数。为简单起见 表示样本的总数。
a=σ(z), z=∑W j*X j+b
σ() 是激活函数
使用梯度下降法(Gradient descent)来调整权值参数的大小,权值w和偏置b的梯度推导如下:
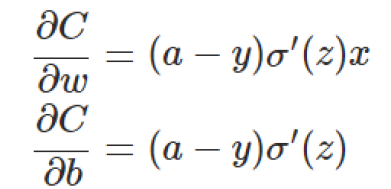
其中,z表示神经元的输入,σ表示激活函数。w和b的梯度跟激活函数的梯度成正比,激活函数的梯度越大,w和b的大小调整得越快,训练收敛得就越快。
假设我们的激活函数是sigmoid函数:
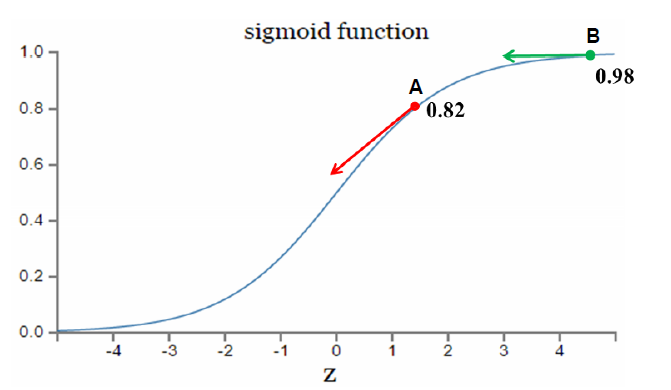
若我们的预测值为1,A点处的梯度大,能以较快的速度逼近预测值,B点梯度小,逼近速度较慢,这样效果比较好
若我们的预测值为0,A点出的梯度大,能以较快的速度逼近预测值,B点梯度小,逼近速度慢,效果差
我们希望在与预测值较远的点能以较快的速度逼近,较近的点一较慢的速度逼近。
接下来我们不改变激活函数,而是改变代价函数:
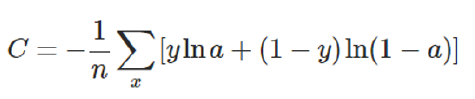
可得到如下结果:

这样在与预测值较远的情况下能以较快的速度逼近,较近的情况下,以较慢的速度逼近,符合想要的效果。
结论:1.交叉熵代价函数中,权值和偏置值的调整与无关,另外,梯度公式中的表示输出值与实际值的误差。所以当误差越大时,梯度就越大,参数w和b的调整就越快,训练的速度也就越快。
2.如果输出神经元是线性的,那么二次代价函数就是一种合适的选择。如果输出神经元是S型函数,那么比较适合用交叉熵代价函数。
3.对数释然函数常用来作为softmax回归的代价函数,如果输出层神经元是sigmoid函数,可以采用交叉熵代价函数。而深度学习中更普遍的做法是将softmax作为最后一层,此时常用的代价函数是
对数释然代价函数。
4.对数似然代价函数与softmax的组合和交叉熵与sigmoid函数的组合非常相似。对数释然代价函数在二分类时可以化简为交叉熵代价函数的形式。
5.在Tensorflow中用:
tf.nn.sigmoid_cross_entropy_with_logits()来表示跟sigmoid搭配使用的交叉熵。
tf.nn.softmax_cross_entropy_with_logits()来表示跟softmax搭配使用的交叉熵。
另外,可能产生过拟合问题:
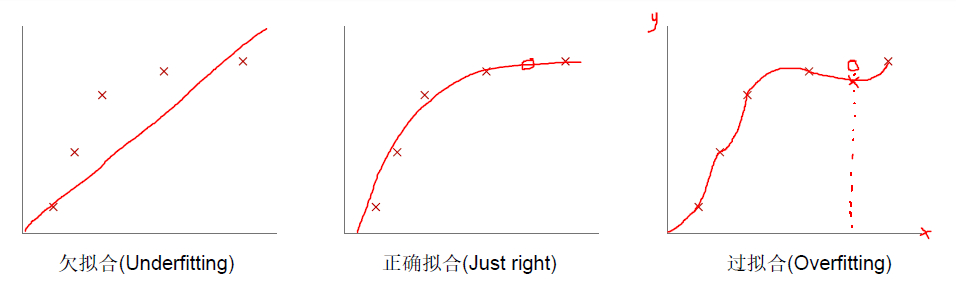
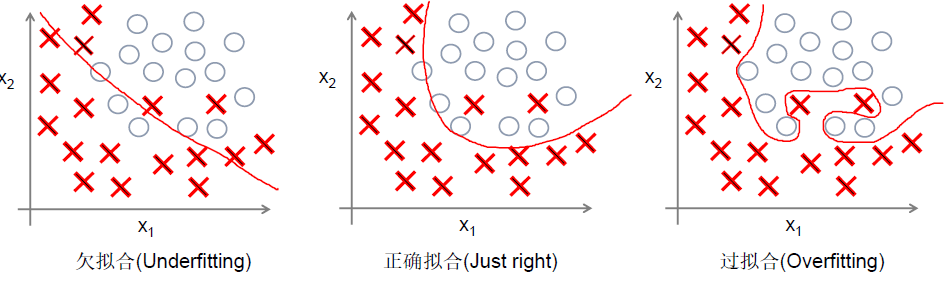
此时我们可以在代价函数中加入正则项: ,右式第二部分即为正则项。正则化的思想就是在代价函数中加入刻画模型复杂程度的指标。
,右式第二部分即为正则项。正则化的思想就是在代价函数中加入刻画模型复杂程度的指标。
关于防止过拟合的问题,在下一篇文章中做讨论。
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data ''' ##简单版本 ##只有两层网络,输入层和输出层 ''' mnist = input_data.read_data_sets('MNIST_data',one_hot=True) batch_size = 100 n_batch = mnist.train.num_examples // batch_size x_train = tf.placeholder(tf.float32,[None,784]) y_train = tf.placeholder(tf.float32,[None,10]) w = tf.Variable(tf.zeros([784,10])) bias = tf.Variable(tf.zeros([1,10])) y = tf.nn.softmax(tf.matmul(x_train,w) + bias) # loss = tf.reduce_mean(tf.square(y - y_train)) #MSE代价函数 loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_train,logits=y)) #交叉熵代价函数 #train = tf.train.GradientDescentOptimizer(0.1).minimize(loss) #train = tf.train.AdadeltaOptimizer(1e-3).minimize(loss) train = tf.train.MomentumOptimizer(0.1,0.9).minimize(loss) init = tf.global_variables_initializer() correct = tf.equal(tf.argmax(y_train,1),tf.argmax(y,1)) accuracy = tf.reduce_mean(tf.cast(correct,tf.float32)) with tf.Session() as sess: sess.run(init) for epoch in range(31): for batch in range(n_batch): batch_xs,batch_ys = mnist.train.next_batch(batch_size) sess.run(train,feed_dict={x_train:batch_xs,y_train:batch_ys}) acc = sess.run(accuracy,feed_dict={x_train:mnist.test.images,y_train:mnist.test.labels}) print('iteration ', str(epoch),' accuracy: ',acc)