绪论
优化是非常困难的一类问题,而这正是深度学习的核心。优化问题是如此困难,以至于在神经网络引入几十年后,深度神经网络的优化问题仍阻碍着它们的推广,并导致了其 20世纪 90 年代到 21 世纪初的衰落。网络越深,优化问题就越难。
1、激活函数
① 作用:
如今的互联网提供了大量的信息。我们只需要通过搜索引擎就可以找到需要的信息。而其中最重要的一个挑战是区分相关信息和非相关信息。当我们的大脑充满了信息的时候,它会第一时间区分哪些是有用信息哪些是无用信息。因此,在神经网络中我们也需要一个类似的机制来区分有用信息。
这是一个非常重要的概念。因为并不是所有的信息都是同样重要的,有些信息可能就是噪音。激活函数就是帮助网络来区分这些信息。激活函数帮助神经网络获取有用信息而抛弃无用信息,将需要处理的信号往后传输,将不关心的信号丢弃,从而增加神经网络模型的非线性,提升神经网络模型表达能力(数据往往线性不可分 )。
② 常见的激活函数
Sigmoid函数(Logistic 函数)是一种运用非常广泛的激活函数,隐层神经元输出,取值范围(0,1),可以将一个实数映射到(0,1)的区间,可以做二分类。形式如下:


-
优点:
非线性的。这点是非常厉害的。这意味着当我们有多个不同的神经元的时候,其输出结果也都是非线性的。这个函数是0-1之间的S形的。
我们看一下这个函数的梯度(如下图所示),它在-3到3之间是比较大的。但是在其他地方是比较平坦的。这意味着很小范围内的x的变动也可以导致Y值较大的变化。这种函数使得Y值趋向于极端情况。这种特性非常适合我们将某些值分到某种特定的类别上。
同时,这个函数的梯度也是光滑的,而且是依赖于输入值x的。这就意味着后向传播算法也可以使用。误差可以通过后向传播的方式传递给前面的神经元,并对其权重和偏移做更新。

-
缺点:
梯度消失。在-3和3之外的区域,它的图像很平坦。这就意味着一旦函数的结果落入这个区域,它的梯度也会非常平坦,且接近于0,也就意味着后向传播的优化就不存在了,无法深层网络训练。但是并不是所有的时候我们都希望下一个神经元只接受正值。这导致了tanh激活函数的出现。 -
Tanh函数
Tanh函数的形式和Sigmoid很像,如下:


我们可以看到,这个图形是完全对称的,它的值域范围也是-1到1之间。它解了Sigmoid函数的上述两个缺点。而其他特性又和Sigmoid函数一样。它是在所有点上连续可导的。其梯度的图像如下:

Tanh的梯度相比较Sigmoid更加陡峭。我们选择Sigmoid还是Tanh是根据问题中对梯度的要求而定的。但是,和Sigmoid类似,Tanh也有梯度崩塌的情况。即区域外的Tanh非常平坦,其梯度特别小。
Softmax是另一种Sigmoid函数,但是它是在分类中比较容易控制的一种激活函数。Sigmoid只能处理两类的问题。Softmax将输出结果压缩在0-1之间,并依据输出的总和来分类。它给输入的概率一个概率。Softmax形式如下:

假设我们的一个输出结果是[1.2,0.9,0.75]
当我们使用了softmax之后,这个值变成了[0.42, 0.31, 0.27]
[0.42,0.31,0.27],我们可以使用这些概率当做每一类的概率。
Softmax在输出层中使用是比较完美的,这里我们通常是需要获得输入数据对应的类别的各种概率。
ReLU是整流线性单元。它也是最广泛使用的激活函数之一,形式和图形如下:


- 优点:
1、输入为正数,不存在梯度饱和问题。
2、计算速度快。ReLU函数只有线性关系,前向传播和反向传播,都比sigmod和tanh快。(sigmod和tanh计算指数)。
3、在输入是负值的情况下,它会输出0,那么神经元就不会被激活。这意味着同一时间只有部分神经元会被激活,从而使得网络很稀疏,减少参数相互依存,缓解过拟合发生。
ReLU的梯度如下:

- 缺点
1、 输入是负数,ReLU完全不被激活,ReLU会死掉。反向传播中,输入负数,梯度0,和sigmod函数、tanh函数有一样的问题。learning rate 很大,可能网络中40%的神经元都”dead”了。较小的learning rate,问题不会太频繁。
2、ReLU函数的输出是0或正数,ReLU函数也不是以0为中心的函数。
③ 选择正确的激活函数
这么多激活函数需要在什么时候使用什么呢?这里并没有特定的规则。但是根据这些函数的特征,我们也可以总结一个比较好的使用规律或者使用经验,使得网络可以更加容易且更快的收敛。
- Sigmoid函数以及它们的联合通常在分类器的中有更好的效果
- 由于梯度崩塌的问题,在某些时候需要避免使用Sigmoid和Tanh激活函数
- ReLU函数是一种常见的激活函数,在目前使用是最多的。
记住,ReLU永远只在隐藏层中使用
根据经验,我们一般可以从ReLU激活函数开始,但是如果ReLU不能很好的解决问题,再去尝试其他的激活函数。
2、损失函数
常见的三种损失函数
① tf.nn.softmax_cross_entropy_with_logits()
cross_entropy=tf.nn.softmax_cross_entropy_with_logits(logits= Network.out, labels= Labels_onehot)
在计算交叉熵之前,通常要用到softmax层来计算结果的概率分布。
因为softmax层并不会改变最终的分类结果(排序),所以,tensorflow将softmax层与交叉熵函数进行封装,形成一个函数方便计算。上面是softmax交叉熵loss,参数为网络最后一层的输出和onehot形式的标签。
切记输入一定不要经过softmax,因为在函数中内置了softmax操作,如果再做就是重复使用了。
在计算loss的时候,输出Tensor要加上tf.reduce_mean(cross_entropyor)或者tf.reduce_sum(cross_entropy),作为tensorflow优化器(optimizer)的输入。
- 实现代码
#输出层,使用softmax进行多分类
w_fc2=tf.Variable(tf.truncated_normal([80,10]))
b_fc2=tf.Variable(tf.truncated_normal([10]))
y=tf.nn.softmax(tf.matmul(h_fc1,w_fc2)+b_fc2)
##反向传播
####损失函数###
cross_entropy=-tf.reduce_sum(y_*tf.log(y))
# 使用AdamOptimizer优化器训练模型,最小化交叉熵损失
train_step=tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
相当于
y_= tf. placeholder(tf.float32, [None, mnist_forward. OUTPUT_NODE])
w2 = get_weight([LAYER1_NODE, OUTPUT_NODE],regularizer)
b2 = get_bias([OUTPUT_NODE])
y =tf.matmul(y1, w2) + b2
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=y, labels=tf. argmax(y_,1)))
train_step=tf.train.GradientDescentOptimizer(learning_rate). minimize(cross_entropy)
该网络会计算logits和labels的softmax cross entropy loss,衡量独立互斥离散分类任务的误差,说独立互斥离散分类任务是因为,在这些任务中类与类之间是独立而且互斥的,比如VOC classification、Imagenet、CIFAR-10甚至MNIST,这些都是多分类任务,但是一张图就对应着一个类,class在图片中是否存在是独立的,并且一张图中只能有一个class,所以是独立且互斥事件。
要求labels的形式为one hot是因为网络的输出要进行softmax,得到的就是一个有效的概率分布,这里不同与sigmoid,因为sigmoid并没有保证网络所有的输出经过sigmoid后和为1,不是一个有效的概率分布。
有了labels和softmax后的logits,就可以计算交叉熵损失了,最后得到的是形状为[batch_size, 1]的loss。
② tf.nn.sparse_softmax_cross_entropy_with_logits ()
cross_entropy=tf.nn.sparse_softmax_cross_entropy_with_logits (logits=Network.out, labels= Labels)
为了加速计算过程,针对只有一个正确答案(例如MNIST识别)的分类问题所设定的函数。
它与tf.nn.softmax_cross_entropy_with_logits()的区别在于:
tf.nn.softmax_cross_entropy_with_logits()中的logits和labels的shape都是[batch_size, num_classes],而tf.nn.sparse_softmax_cross_entropy_with_logits()中的labels是稀疏表示的,是 [0,num_classes)中的一个数值,代表正确分类结果。即sparse_softmax_cross_entropy_with_logits 直接用标签计算交叉熵,而 softmax_cross_entropy_with_logits 是标签的onehot向量参与计算。
softmax_cross_entropy_with_logits 的 labels 是 sparse_softmax_cross_entropy_with_logits 的 labels 的一个独热版本(one hot version)。
③ tf.nn. sigmoid_cross_entropy_with_logits()
cross_entropy=tf.nn. sigmoid_cross_entropy_with_logits (logits= Network.out, labels= Labels_onehot)
该网络会计算logits和labels的sigmoid cross entropy loss并返回,衡量独立不互斥离散分类任务的误差,说独立不互斥离散分类任务是因为,在这些任务中类与类之间是独立但是不互斥的,拿多分类任务中的多目标检测来举例子,一张图中可以有各种instance,比如有一只狗和一只猫。对于一个总共有五类的多目标检测任务,假如网络的输出层有5个节点,label的形式是[1,1,0,0,1]这种,1表示该图片有某种instance,0表示没有。那么,每个instance在这张图中有没有这显然是独立事件,但是多个instance可以存在一张图中,这就说明事件们并不是互斥的。所以我们可以直接将上一层网络的输出用作该方法的logits输入,从而进行输出与label的cross entropy loss。
更加直白的来说,这种网络的labels不需要进行one hot处理。不同于softmax系列函数是张量中向量与向量间的运算。sigmoid_cross_entropy_with_logits函数则是张量中标量与标量间的运算。 剖开函数内部,因为labels和logits的形状都是[batch_size, num_classes],那么如何计算他们的交叉熵呢,毕竟它们都不是有效的概率分布(一个batch内输出结果经过sigmoid后和不为1)。因为它的loss的计算是element-wise的,方法返回的loss的形状和labels是相同的,也是[batch_size, num_classes],再调用reduce_mean方法计算batch内的平均loss。所以这里的cross entropy其实是一种class-wise的cross entropy,每一个class是否存在都是一个事件,对每一个事件都求cross entropy loss,再对所有的求平均,作为最终的loss。
3、优化器
经过损失函数处理之后,最后一步就是tf.train.XxxOptimizer().
常见的优化算法有如下几种
train_step=tf.train.GradientDescentOptimizer(learning rate).minimize(cross_entropy)
这是最基础的梯度下降算法,更新权重W,不多解释。
算法如下:
W += - α * dx
其中 α是learning rate(学习速率)。我们可以把下降的损失函数看成一个机器人,由于在下降的时候坡度不是均匀的,机器人会左右摇摆,所以下降速度会比较慢,有时候遇到局部最优,还可能在原地徘徊好长时间。
顾名思义这个优化算法实际上给了一个动量,让机器人下降的的时候带一个惯性,下降的速度就加快了。
算法如下:
m = b1*m - α * dx
W += m
这个算法是通过动态改变学习速率,提高下降速度,相当于给机器人穿上一个左右侧滑有阻力的鞋子,让它只好沿着正确的方向下滑。
算法如下:
v = dx^2
W += -(α/sqrt(v)) * dx
-
RMSProp
这个算法相当于在AdaGrad中引入了Momentum的惯性
v = b1 * v + (1-b1)*dx^2
W += -(α/sqrt(v)) * dx
但是RMSprop缺少了Momentum的变量m -
Adam
tf.train.AdamOptimizer(learning_rate).minimize(cross_entropy)
Adam是目前用得最广的优化算法,它结合了AdaGrad和Momentum的优点(所以叫才Adam嘛)
算法如下:
m = b1m + (1-b1)dx
v = b2v + (1-b2)dx^2
W += -(α*m/sqrt(v)) * dx
这个算法相当于给机器人一个惯性,同时还让它穿上了防止侧滑的鞋子,当然就相当好用用啦。所以在很多机器学习和深度学习的应用中,我们用的最多的优化器是 Adam。
各优化器收敛速度的比较
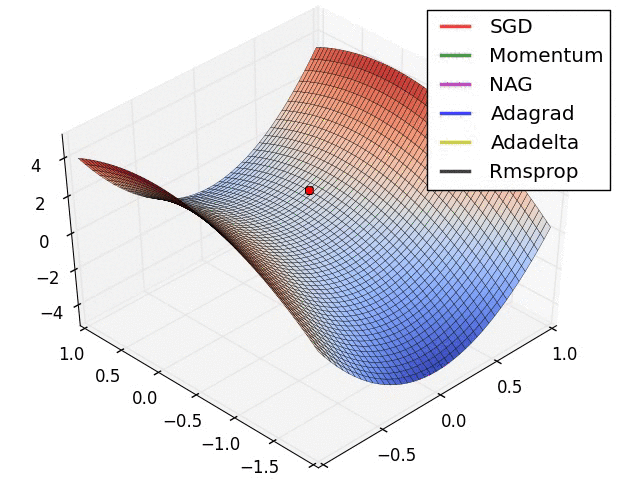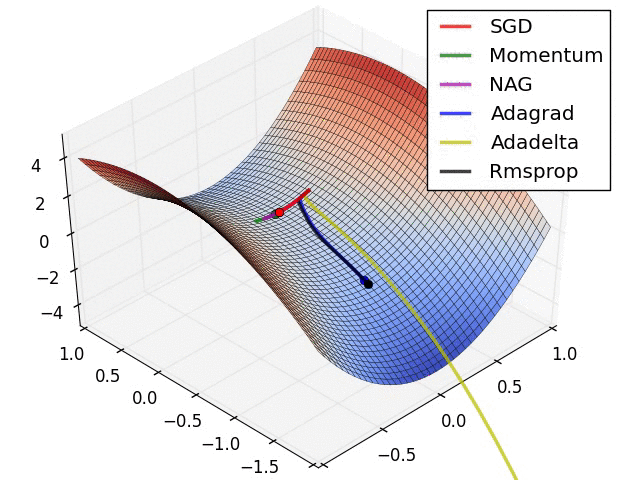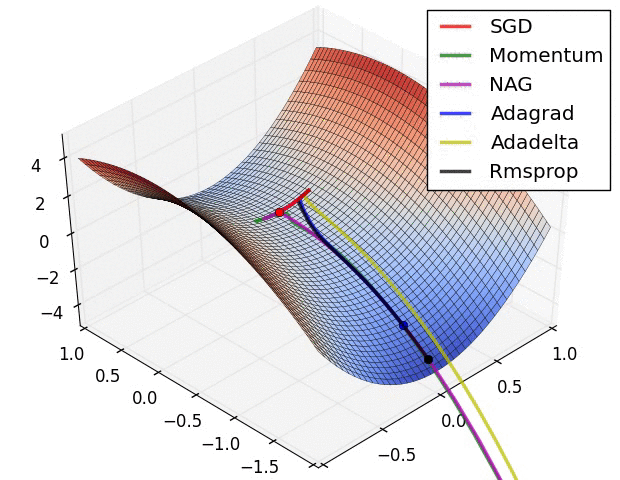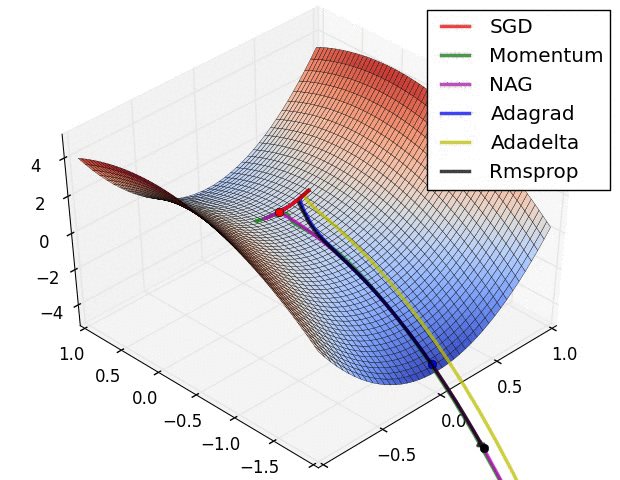

上面两种情况都可以看出,Adagrad, Adadelta, RMSprop 几乎很快就找到了正确的方向并前进,收敛速度也相当快,而其它方法要么很慢,要么走了很多弯路才找到。
如果需要更快的收敛,或者是训练更深更复杂的神经网络,需要用一种自适应的算法。
由图可知自适应学习率方法即 Adagrad, Adadelta, RMSprop, Adam 在这种情景下会更合适而且收敛性更好。如果数据是稀疏的,就用自适应方法,即 Adagrad, Adadelta, RMSprop, Adam。RMSprop, Adadelta, Adam 在很多情况下的效果是相似的。
Adam 就是在 RMSprop 的基础上加了 bias-correction 和 momentum。随着梯度变的稀疏,Adam 比 RMSprop 效果会好。
整体来讲,Adam 是最好的选择。
你是否碰到过这样一种情况:你的模型在训练集上表现异常好,但在预测测试数据时表现平平。这其中涉及到了模型过拟合的问题。
4、避免过拟合
什么是过拟合?
在深入该主题之前,先来看看这几幅图:

之前见过这幅图吗?从左到右看,我们的模型从训练集的噪音数据中学习了过多的细节,最终导致模型在未知数据上的性能不好。
换句话说,从左向右,模型的复杂度在增加以至于训练误差减少,然而测试误差未必减少。

这种现象就是过拟合。所谓过拟合,就是当一个模型过于复杂后,它可以很好的处理训练数据的每一个数据,甚至包括其中的随机噪点。而没有总结训练数据中趋势。使得在应对未知数据时错误里一下变得很大。这明显不是我们要的结果。而我们想要的是在训练中,忽略噪点的干扰,总结整体趋势。在应对未知数据时也能保持训练时的正确率。
神经网络越复杂,过拟合的现象就越显著。

为了避免过拟合,通常使用的方法就是正则化(regularizer)和dropout。
① 正则化
正则化技术是对学习算法做轻微的修改使得它泛化能力更强,这反过来就改善了模型在未知数据上的性能。
正则化的思想就是在损失函数中加入一个刻画模型复杂度的正则项。
Cost function = Loss (say, binary cross entropy) +Regularization term
由于增加了这个正则项,权重矩阵的值减小了,因为这里假定了具有较小权重矩阵的神经网络会导致更简单的模型。因此,它也会在相当程度上减少过拟合。
假设用于刻画模型在训练数据上的表现的损失函数为loss(θ),那么在优化时不是直接优化J(θ),而是优化loss(θ) + λR(w)。其中R(w)表示的是模型复杂度。λ表示模型复杂度损失在总损失中的比例。对于θ表示的是一个神经网络中所有参数,包括weight和 biases。而复杂度只由权重(weight)来决定。
L1:所有学习参数w的绝对值的和
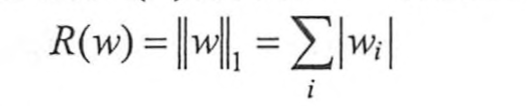
TensorFlow中的提供的函数为:
tf.contrib.layers.l1_regularizer(scale, scope=None)
L2:所有学习参数w的平方和然后求平方根。
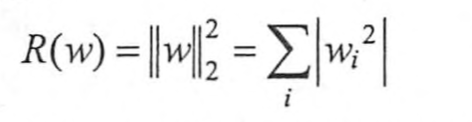
TensorFlow中的提供的函数为:为
tf.contrib.layers.l2_regularizer(scale, scope=None)
两种思想都是希望限制权重的大小,使得模型不能拟合训练数据中的随机噪点。
def get_weight(shape,regularizer):
w=tf.Variable(tf.truncated_normal(shape,stddev=0.1)) #随机生成w
if regularizer!=None:
tf.add_to_collection('losses',tf.contrib.layers.l2_regularizer(regularizer)(w))
#定义正则化,将每个变量的正则化加入到losses集合当中,以备后续相加
return w
在神经网络的权重函数中定义正则化tf.contrib.layers.l2_regularizer(regularizer)(w)),并将权重的L2正则化损失通过tf.add_to_collection加入到losses集合中,以备后续相加。
#定义均方差的损失函数
mse_loss = tf.reduce_mean(tf.square(y_ - y))
#将均方差孙函数添加到losses集合
tf.add_to_collection("losses",mse_loss)
#获取整个模型的损失函数,tf.get_collection("losses")返回集合中定义的损失
#将整个集合中的损失相加得到整个模型的损失函数
loss = tf.add_n(tf.get_collection("losses"))
通过tf.add_n和tf.get_collection函数将损失函数和正则项相加起来。
【拓展
tf.add_to_collection(‘list_name’, element):将元素element添加到列表list_name中
tf.get_collection(‘list_name’):返回名称为list_name的列表
tf.add_n(list_name):将列表元素相加并返回
】
② dropout
L1、L2正则化是通过修改代价函数来实现的,而Dropout则是通过修改神经网络本身来实现的,它是在训练网络时用的一种技巧(trike)。
dropout是一种常用的手段,用来防止过拟合的。L1、L2正则化是通过修改代价函数来实现的,它是通过修改神经网络本身来实现的是在训练过程中每次都随机选择一部分节点不要去学习,减少神经元的数量来降低模型的复杂度,同时增加模型的泛化能力。虽然会使得学习速度降低,因而需要合理的设置保留的节点数量。
在TensorFlow中dropout的函数原型如下:
def dropout(x, keep_prob, noise_shape=None, seed=None, name=None)
各个参数的意义如下:
x:输入的模型节点
keep_prob:保持节点的比率,如果为1,则表示全部节点参与学习,如果为0.8,则表示丢弃20%的节点。
noise_shape:设置指定的x中参与dropout计算的维度,如果为None,则表示所有的维度都参与计算,也可以设定某个维度,例如:x的形状为[ n, len, w, ch],使用noise_shape为[n, 1, 1, ch],这表明会对x中的第二维度和第三维度进行dropout。
dropout改变了神经网络的网络结构,它仅仅是属于训练时的方法,所以在进行测试时要将dropout的keep_porb的值为1。
- 实现代码
keep_prob = tf.placeholder('float')
L1 = ...
L1_d = tf.nn.dropout(L1, keep_prob)
#Train
sess.run(optimizer, feed_dict={X: batch_xs, Y: batch_ys, keep_prob: 0.7})
#Evaluation
print("Accuracy", accuracy.eval({X: mnist.test.images, Y: mnist.test.labels, keep_prob: 1}))
