Quick Thoughts(以下简称QT 论文)可以理解为升级版本的Skip-thought,方法简单很多,但是效果上略优于InferSent等算法。
Skip-thought
了解QT绕不开Skip-thought(论文)。Skip-thought顾名思义,可以理解为句子版本的Skip-gram(word2vec论文)。在word2vec算法的skip-gram版本中,中心词可以用来预测context中的词汇; 对应的,Skip-thought利用中心词预测context中的句子。

如图所示,中间的句子”I could see the cat on the steps” 可以拿来预测前面的句子”I got back home”和后面的句子”This was strange”。
那么这种预测具体怎么实现呢?
作者利用了一个encoder来压缩中心句子的信息,然后用一个decoder来产生context里的句子。对于这种sequence modeling, 一般的最佳选择是LSTM或者GRU,论文中encoder和decoder都是GRU。相应的,负的loss function是:
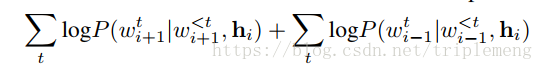
这里的
代表第i个句子通过encoder的输出,
代表第i+1个句子的前t-1个词,基于它们,得到
即第i+1个句子的第t个词的概率为
。这个公式的两项分别对应了下一句和上一句出现的概率。本质上,(在decoder这部分)这个问题是作为language modeling来处理的。
(另外,论文里提供了一个小“彩蛋”:如果encoder遇到在training set里从未出现的词怎么办呢?这里不写了,原论文里有一个很简单的办法。)
改进
看上去,Skip-thought和Skip-gram挺象。唯一的遗憾是Skip-thought的decoder那部分,它是作为language modeling来处理的。而Skip-gram则是利用一个classifier预测周围的词(通过hierarchical softmax 或者negative sampling)。QT针对这个问题,对decoder部分做了大的调整,它直接把decoder拿掉,取而代之的是一个classifier。这个classifier负责预测哪些句子才是context sentences。
假设f和g是encoder,s是中心句子,
是context sentences,
是candidate sentences, 它包括
, 也包括不相关的句子。
目标函数可以写为:
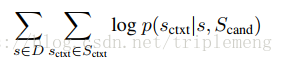
这里的概率p可表达为下式:
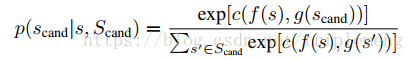
f, 和g在这里是encoder, c是classifier。c的函数形式和word2vec保持一致:
对比而言,这两种方法可以用论文中的图表示为:
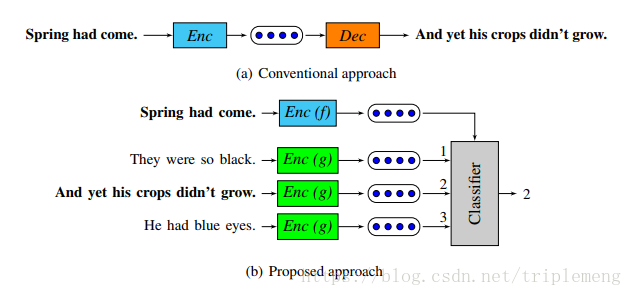
QT的classifier取代了Skip-thought的Decoder。这样做的好处是运行的速度大大提升了,用判别问题取代了生成式问题。有趣的是,虽然QT出现的比Skip-thought更晚,但是方法更简单,也更加接近Word2Vec算法。
实验
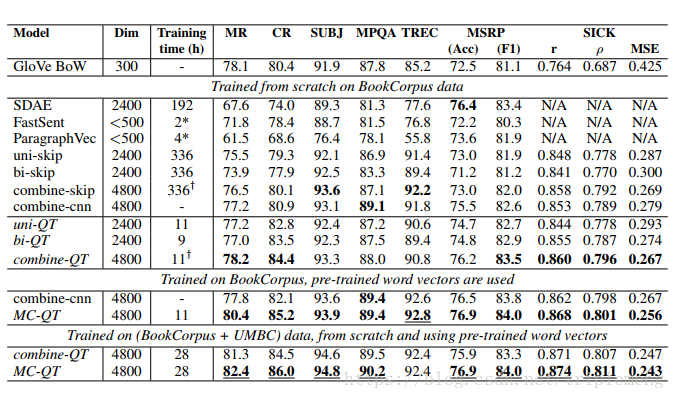
和unsupervised representation learning方法的比较:
在大多数情况下,uni/bi/combine-QT的表现好于其他模型,并且训练时间大大缩短。这里uni-QT和bi-QT分别指使用了单向和双向RNN作为encoder的模型。combine-QT在test time使用了uni-QT和bi-QT学习得到的句子表征(由于它同时使用了两种表征,我们可以看到在dim一栏值是其它值的两倍)。在这里uni/bi/combine-QT都没有使用pre-trained word vectors。
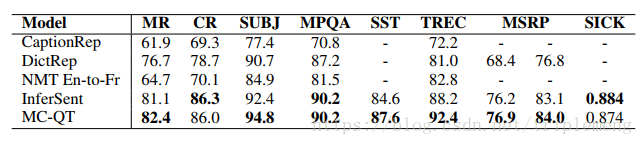
注意MC-QT模型在各个任务上最优。MC-QT就是MultiChannel-QT,作者模仿了Yoon Kim 在Convolutional neural networks for sentence classification(2014)中的做法,分别用一个pretrained word embedding(Glove)和一个tunable word embedding(trained from scratch)来作为输入。和supervised representation learning方法的比较:
注意和前文中介绍过的InferSent的比较,MC-QT在多数任务中效果更好。但是我个人在这里存有疑虑:InferSent仅使用了pre-trained word vectors(Glove)。 如果也采取MultiChannel embedding的做法,不知道会不会有同样的提升?和Skip-thought进行Nearest neighbors提取的比较:
感受以下两种方法从Wikipedia里1M个句子中寻找最近邻的表现。

总结
QT是一种新的state-of-art的算法。它不光效果好,而且训练时间要远小于其他算法。在算法方法上和效果上,都可称为是句子表征界的Word2Vec一般的存在。和前面几篇介绍的不同算法放在一起比较,同样都是为了找到好的句子表征,它们采取了不同的路径:InferSent在寻找NLP领域的ImageNet, 它的成功更像是在寻找数据集和任务上的成功,当然它成功的找到了SNLI; Concatenated p-means在寻找NLP领域的convolutional filter, 即怎样才能更好的提炼出句子级别的特征,它找到了p-means操作,以及利用了不同的embeddings; QT则是直接在算法层面上,寻找句子级别的Word2Vec, 算法上的改进让它受益。我们看到不同的方法在不同的方向上都作出了努力和取得了成效,很难讲哪种努力会更有效或者更有潜力。唯一唯一可以肯定的是,从应用层面上来讲,合适的才是最好的。
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关计算机视觉
