书接上回。这篇文章介绍一下2017年影响力非常大的一篇论文 : Supervised Learning of Universal Sentence Representation from Natural Language Inference Data, by Alexis Conneau et al. 迄今为止它在NLP很多任务上都取得了state of art的成绩。
贡献
关于句子embedding已经有过很多的研究了,按照学习方法可以分为无监督和监督学习两大类。一般来讲如果我们需要的是比较generalized,能够用在各种task中的句子embedding, 无监督方法是一个更好的选择,因为它不太容易受到特定的NLP任务的影响,比如说skip-thought就是很好的利用无监督方法产生句子embedding的算法。
然而论文的作者注意到在Computer Vision领域中,很多模型都是先利用ImageNet预先训练好(图像分类任务),之后再用在别的任务上去(迁移学习)。也就是说,监督学习一样可以产生transferrable的特征。基于这样的观察,作者希望以监督学习的方式,找到通用的句子表征。但是作者需要回答两个问题:
- 什么样的数据是NLP领域的ImageNet
数据和任务是紧密联系在一起的,也可以说,什么样的数据+任务是产生好的universal sentence representations 的数据+任务? - 什么样的模型是NLP领域的Le-Net(VGG-Net, Google-Net, Res-Net, etc)
让我们看看作者给出的答案:
- NLP领域的ImageNet
作者给出的答案是SNLI。 SNLI全称为Stanford Natural Language Inference Corpus, 它由570k个人造句子对组成。每一对句子都被标记为三个分类之一:entailment(蕴含), contradiction(矛盾) 和 neutral(中立)。正如ImageNet的任务是image classification, SNLI的任务是NLI。 NLI task目的就是对句子对做分类。
作者选中了SNLI的原因是,NLI任务的语义学特性应该会使SNLI成为很好的产生universal sentence embeddings的数据(任务)。我觉得找到SNLI是本篇论文的重大贡献。的确,NLI是很好的理解语义的任务,该任务足够具体,以致于好的模型需要区分三种句子对分类,从而产生足够好的对语义的理解;同时又足够一般化,以致于能够避免产生过于task-specific的特征。比如,拿我们熟悉的sentiment analysis任务举例,其句子表征会含有很多有强烈情感信息的特征,这些特征对于情感分析是非常有用的,但是transfer到其他任务中(比如句子分类), 它们可能带来很多噪音。
对比一下CV和NLP,
| 领域 | 数据 | 任务 | 模型(编码器) |
|---|---|---|---|
| CV | ImageNet | image classification | Le-Net, VGG-Net, Google-Net, ResNet, DenseNet etc. |
| NLP | SNLI | NLI | ? |
NLI任务设计
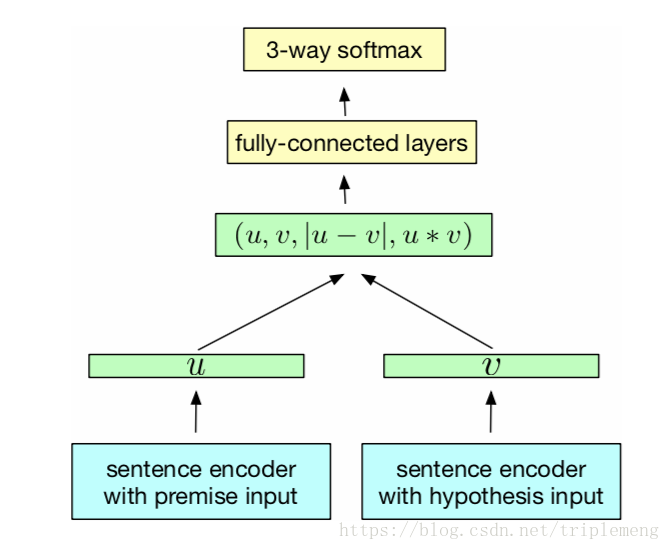
在介绍句子encoder之前,先看一看NLI任务的整体训练设计。如下图所示:
具体流程是:句子对中的每一个句子都传给同样一个sentence encoder, 这个encoder产生的sentence embeddings (图中的 和 ) 要经过3种匹配函数:连接,element-wise的向量差(取绝对值),element-wise的向量积。在这之后经过全连接层传给3-way softmax进行句子关系的预测。编码器模型
作者尝试了不同的编码器模型:LSTM and GRU; BiLSTM with mean/max pooling; Self-attentive network; Hierarchical ConvNet。在关注实验结果之前,我们可以预测一下哪个模型会是合适的编码器模型。
首先,BiLSTM由于包含了两个方向的信息,一般要好于LSTM/GRU。
然后,ConvNet强于抓取local的信息但缺点是不能很好地概括句子中global的信息。
在各种NLP任务中,attention+(Bi)LSTM效果要强于(Bi)LSTM:因为有了attention机制,我们可以找到每个隐向量在任务中合适的权重,而不是简单的对隐向量做简单的平均。 self-attentive利用一个jointly learned context query vector,来找到隐向量的weight(详见我的另一篇文章:一个Hierarchical Attention神经网络的实现) ,从而实现对隐向量更好的总结(即,找到更好的sentence embedding)。但是,这里找到的对SNLI任务有用的weights,并不一定能很好地迁移到其他任务中去。换言之,这里的attention机制会有“过拟合”之嫌。这里的“过拟合”表现为在SNLI任务中表现很好,但是在其他任务中不能一样优秀。
综上所述,我们可以预测(Bi)LSTM是最好的句子编码器。
实验
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关计算机视觉
