这是《简介》系列的最后一篇文章。原本我是想写一下Universal Sentence Encoder这篇文章,但是我觉得其实很多工作包括之前介绍的几篇文章都是在寻找”Universal Sentence Encoder”,没有理由起这么个名字。再者文章本身写得不够详细,相比之下,同样的作者所写的这篇Learning Semantic Textual Similarity from Conversations要更全面。论文
方法
Input-Response Prediction
论文基于这样的观察:在对话中,如果两个问句的回答是相似的,那么这两个问句的相似度就高。比如”How old are you” 和 “What is your age”的回答都是”I am 20 years old”。相反,问句“How are you”和“How old are you”的用词虽然很相似,但是回答不一致,那么它们的意义也不一样。
整个算法的任务就是从一堆候选句子中,找到给定问句正确的回答,如下图:

具体而言,作者利用conversational input-response model来预测正确的response,做法如下:
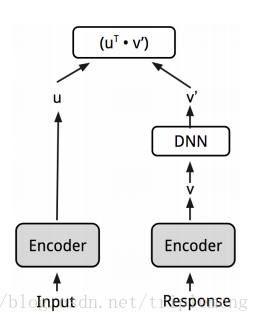
注意这里并不是一个对称的图形,为了反映输入(input)和回答(response)的不同,response embedding传给了feed-forward network,经过一系列操作后产生的新的embedding和input这边的embedding做点积。
图中Input和Response的Encoder是共享的。作者选取了DAN(论文)和Transformer(论文)。二者的差异在于后者精度更高,当然内存和时间方面的损耗也更高。作为输入的embedding全部是在训练中学习得来。
Multitask Encoder
作者认为加入多任务学习以后模型应该能学习到更好的语义表征。原因是多任务可以覆盖到更多的语义现象,而这在单任务中是无法学习到的。于是作者在原本的conversational input-response prediction的基础上增加了自然语言推断任务(NLI),对应的数据是SNLI。注意第一个任务是无监督学习,其数据由input-response这种对话性质的句子对组成; 第二个任务是监督学习,其数据也是句子对,但是这些句子对不是对话中的句子。而label是entailment, neutral和contradiction三者之一。通过同时处理第二个任务,作者希望模型能够学习到互补的信号。
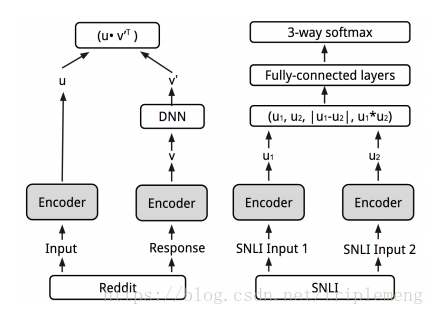
注意第一个任务的模型没有改变,第二个任务的模型和我们前文介绍过的InferSent是一模一样的。两个任务共享encoder(即图中阴影部分)。
数据
Input-Response的句子对从哪里来?这里用的是从Reddit conversation里抽取的数据。Reddit数据的优点在于它的结构化,如果comment B回答comment A, 它往往是作为comment A的子评论出现。
实验
(下面的实验中,因为transformer远优于DAN,所以以下所有的实验数据都以transformer为encoder。)
STS
前面介绍过STS(Semantic Textual Similarity),在实验中Reddit+SNLI tuned的结果要比其他算法好。“tuned”的意思是说利用一个transformation matrix把模型中产生的句子的表征做一个投影,这个matrix是利用STS的数据进行训练得到。
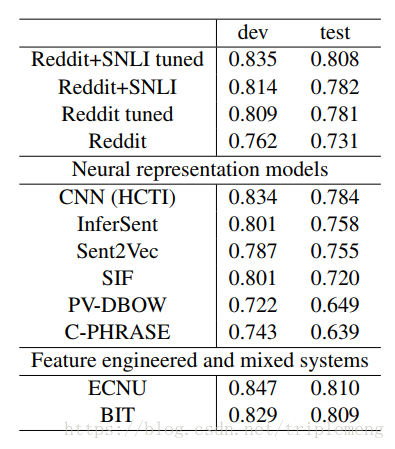
明显比同样利用SNLI训练得到的InferSent要好,作者的解释是可能Reddit的数据起到了regularizer的效果,从而避免了句子embedding去过拟合 SNLI。
CQA Subtask B
CQA是指Community Question Answering。 它的subtask B指的是给定原始问题Q和前十个候选问题,根据它们和原始问题的相似度来排序。任务的metrics是MAP(mean average precision)。 Q和候选问题之间的关系可标记为”PeferctMatch”,”Relevant”或者”Irrelevant”。
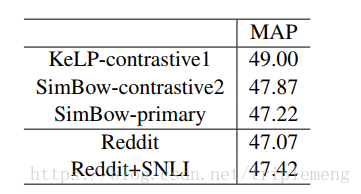
实验结果如下所示,和曾经的state-of-art比较很接近。
总结
一点感想:
- 过去有研究表明利用conversational data训练对email response prediction非常有效。这篇论文里作者把对话的作用推广了,希望能够学到更通用的语义信息。
- 方法上来讲有点像上一篇介绍过的Quick thoughts。 QT是在预测前面和后面的句子,本文则是在预测问题的回答。
- 很显然Transformer要好于DAN,但是从研究的角度上来讲可以用DAN先做一个好的基线模型。
多任务学习在这里应用的非常成功。从实验的结果看,在做其他任务的transfer learning时,从SNLI里学到的信息可以成为Input-Response模型有益的补充。这像各种不同的word embedding之间互相补充的关系(比如前文介绍的p-means)
关注公众号《没啥深度》有关自然语言处理的深度学习应用,偶尔也有关计算机视觉
