如下图所示,为H.264编码流图,首先,输入一组YUV数据,以一个GOP为例,每个GOP包含若干帧数据(IPPP结构或者IPBBP结构);然后,将GOP拆分为一帧输入到编码器中进行编码,一帧数据又包含至少一个Slice;其次,进一步将一帧图像拆分为多个Slice,一个Slice又包含若干个宏块;再次,将Slice拆分为若干个16*16大小宏块,则宏块即为编码的最小单元了,针对不同情况宏块仍然可再细分为若干个16*8、8*16、8*8、8*4、4*8和4*4子块类型,最后再对这些子块进行编码处理。
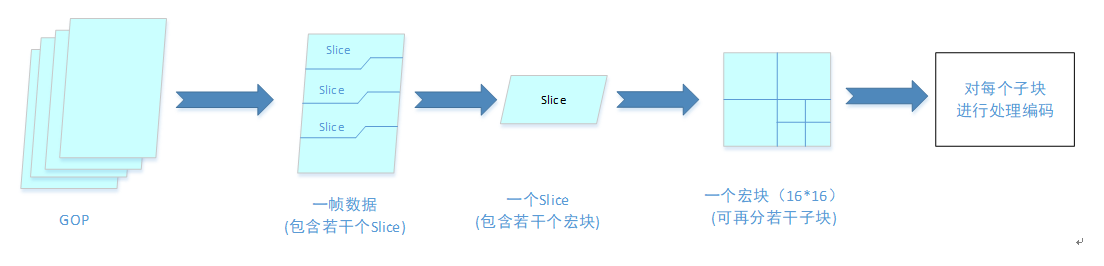
看到图中所描述的信息,首先会想到这么几个问题?
- 编码器是如何区分GOP中的I、P、B帧类型的呢?
- 一帧数据是通过什么方式拆分成Slice的呢?
- 一个宏块是通过什么方式拆分成若干个子块呢?
- 还有个问题图中并未体现,运动向量是基于16*16宏块的呢还是基于最小子块的呢?1/2像素精度和1/4像素精度具体又是怎样的含义呢?
本文将一一给出我的见解,如果有什么错误请大家多多指正。
- 首先针对1)问题,对于I、P、B帧类型是由参数进行设定的,比如设置GOP的范围,B帧间隔等,通过这些参数信息可以推断出I、P、B帧类型;

- 针对2)问题,同样的可以通过参数设置进行推断出Slice类型和大小,个人理解应该是先对一帧图像进行16*16宏块的全划分,然后再将若干个宏块划归为一个Slice;

- 针对3)问题,H.264中是通过比较宏块SSD的大小来决定如何分块的。例如,一个16*16的宏块可能分为2个8*16或2个16*8或4个8*8或16个4*4子块等,则计算一个16*16的SSD、2个8*16的SSD总和、2个16*8的SSD总和、4个8*8的SSD总和、16个4*4的SSD总和等,然后比较所有SSD值的大小,取SSD(即残差)最小的分块方式为最终的分块模式;
- 针对4)问题,目前我的理解是基于最小分块进行运动搜索的,即最小分块为16*16则以16*16宏块进行运动搜索,最小分块为4*8,则以4*8块进行运动搜索。而1/2像素精度则是先以整像素进行运动搜索,得到最优运动向量时,则再以此向量为中心进行以1/2像素为步长的运动搜索;同理,1/4像素精度则在1/2像素最优运动向量的基础上进行以1/4像素为步长的运动搜索,找到最优的运动向量。