随着时代的发展、Internet的普及,以及对视频传输需求不断提高,现有的这些视频压缩标准明显存在着一些缺陷和局限性。为了克服这些缺点, ITU-T在继H.261,H.263等视频压缩标准之后,制定了新一代视频压缩标准,并正式命名为H.264。新一代标准H.264可以得到更好的压缩图像效果、拥有更多的功能和更大的灵活性。
本文首先介绍了多媒体技术发展的状况以及视频压缩的基本概念和方法,然后分析了H.264编解码器的基本结构和实现流程,本文在细致的分析了其编解码器后,对于解码器,编码器都采用了多种方式进行优化。本文最后还将H.264做和MPEG4编码进行对比做性能分析。本系统开发的视频编码器具有高效,稳定,在保证其优良性能的前提下,达到了缩短运行时间的目的。
H.264是一种视频高压缩技术,全称是MPEG-4 AVC,用中文说是“活动图像专家组-4的高等视频编码”,或称为MPEG-4 Part10。它是由国际电信标准化部门ITU-T和规定MPEG的国际标准化组织ISO/国际电工协会IEC共同制订的一种活动图像编码方式的国际标准格式。原来国际电信标准化部门从1998年就H.26L的H.26S两个分组,前者研制节目时间较长的高压缩编码技术,后者则指短节目标准制订部门。H.26S 的标准化技术的名称为H.263,听起来很耳生,但实质上却早在用了,还被骂得很激烈。因为,H.263先入为大,一直以MPEG-4大内涵的名字在用。 H.263的全称为MPEG-4 Visual或MPEG-4 Pall Ⅱ,即MPEG-4视频简单层面的基础编码方式。2001年后,国际电信标准化部门ITU-T和MPEG的上级组织国际标准化组织ISO/国际电气标准会议IEC成立了联合视频组JVT,在H.26L基础进行H.264的标准化。
1.1视频编码标准的发展状况
MPEG是活动图像专家组Moving Pictures Expert Group的简称。它制定了MPEG-1/2/4/7等视频标准。MPEG-1适用于码率为1.5Mbps的活动图像及其伴音的编码。它主要应用于多媒体计算机、教育与训练等领域,特别是基于CD的数字视听系统,如VCD,它还可以应用于VOD和交互式电视等更广阔的应用领域。MPEG-2是活动图像及其伴音信息的通用编码标准,用于对标准清晰度电视(SDTV)和高清晰度电视(HDTV)的编码,码率可达到100Mbps。它主要应用于数字视频存储、视频广播和通信,是对MPEG-1的重大改进和发展,并且从技术上促进了计算机、广播电视、数字通信三大领域的交汇融合,发挥出巨大作用。这两个协议使得多媒体视频编码技术迈上了一个新的台阶。
MPEG-4的初衷是针对视频会议、视频电话的甚低比特率编码,但在制定过程中,随着多媒体技术的发展和应用需求的变化,引入了视频对象(VO)的概念。和传统的基于图像帧的压缩方法相比,基于视频对象的策略更易于操作和控制编码,并能更灵活的适应在基于内容的多种应用中。
MPEG-7全称是多媒体内容描述接口,它对各种不同类型的多媒体信息进行标准化描述,并将该描述与所描述的内容相联系,力求能够更快速并且有效的搜索出用户所需的不同类型的多媒体资料。MPEG-7重点在于影音内容的描述和定义,以明确的资料结构和语法来定义影音资料的内容。与此同时,ITU-T为满足可视电话和视频会议等方面的应用,指定了H.261,H.263等标准。
1990年制定完成的H.261标准(ITU-T Recommendation H.261,Video codec for audiovisual services at p×64kbps)简称为p×64,当p=1或2时,码率最大为128kbps。由于该码率太低,能传输图像的清晰度不太高,所以只能适用于面对面的可视电话。当p≥6时,码率为384kbps,可以传输清晰度尚好的图像,适用于会议电视。
ITU-T的H.263标准(ITU-T Recommendation H.263,Video Coding for LowBit rate Communication)是ITU-T于1996年制定的用于低码率声像服务的压缩标准,它是ITU-T H.324系列标准所规定的多媒体通信终端的视频编解码标准。H.263实现了码率在64kbps以下的视频压缩。由于要在低码率下实现多媒体通信,技术上实现就更为困难和复杂,因此,H.263采用了多种先进技术以降低码率。
在H.263以后还有一些改进的版本,如H.263+,是对H.263的进一步完善和发展,使得H.263在灵活性和编码效率等方面有了很大的提高,能适应更加广泛的应用要求。随着在低码率,网络应用,可扩展性等方面的一致性,ITU-T的VCEG(视频编码专家组)和ISO/IEC的MPEG(运动图像编码专家组)成立了一个联合视频小组(JVT:joint video team),共同开发一个新的视频编码标准。它既是ITU-T的H.264,又是MPEG-4的第10部分。
第三章 视频编码原理

3.1 H.264的发展
随着HDTV的兴起,H.264这个规范频频出现在我们眼前,HD-DVD和蓝光DVD均计划采用这一标准进行节目制作。而且自2005年下半年以来,无论是NVIDIA还是ATI都把支持H.264硬件解码加速作为自己最值得夸耀的视频技术。H.264到底是何方“神圣”呢?
H.264,同时也是MPEG-4第十部分,是由ITU-T视频编码专家组(VCEG)和ISO/IEC动态图像专家组(MPEG)联合组成的联合视频组(JVT,Joint Video Team)提出的高度压缩数字视频编解码器标准。
H.264是一种高性能的视频编解码技术。目前国际上制定视频编解码技术的组织有两个,一个是“国际电联(ITU-T)“,它制定的标准有H.261、H.263、H.263+等,另一个是“国际标准化组织(ISO)”它制定的标准有MPEG-1、MPEG-2、MPEG-4等。而H.264则是由两个组织联合组建的联合视频组(JVT)共同制定的新数字视频编码标准,所以它既是ITU-T的H.264,又是ISO/IEC的MPEG-4高级视频编码(Advanced Video Coding,AVC),而且它将成为MPEG-4标准的第10部分。因此,不论是MPEG-4 AVC、MPEG-4 Part 10,还是ISO/IEC 14496-10,都是指H.264。
H.264最大的优势是具有很高的数据压缩比率,在同等图像质量的条件下,H.264的压缩比是MPEG-2的2倍以上,是MPEG-4的1.5~2倍。举个例子,原始文件的大小如果为88GB,采用MPEG-2压缩标准压缩后变成3.5GB,压缩比为25∶1,而采用H.264压缩标准压缩后变为879MB,从88GB到879MB,H.264的压缩比达到惊人的102∶1!H.264为什么有那么高的压缩比?低码率(Low Bit Rate)起了重要的作用,和MPEG-2和MPEG-4 ASP等压缩技术相比,H.264压缩技术将大大节省用户的下载时间和数据流量收费。尤其值得一提的是,H.264在具有高压缩比的同时还拥有高质量流畅的图像。
H.264算法的优势
H.264是在MPEG-4技术的基础之上建立起来的,其编解码流程主要包括5个部分:帧间和帧内预测(Estimation)、变换(Transform)和反变换、量化(Quantization)和反量化、环路滤波(Loop Filter)、熵编码(Entropy Coding)。
H.264/MPEG-4 AVC(H.264)是1995年自MPEG-2视频压缩标准发布以后的最新、最有前途的视频压缩标准。H.264是由ITU-T和ISO/IEC的联合开发组共同开发的最新国际视频编码标准。通过该标准,在同等图象质量下的压缩效率比以前的标准提高了2倍以上,因此,H.264被普遍认为是最有影响力的行业标准。
3.2 H.264标准概述
H.264和以前的标准一样,也是DPCM加变换编码的混合编码模式。但它采用“回归基本”的简洁设计,不用众多的选项,获得比H.263++好得多的压缩性能;加强了对各种信道的适应能力,采用“网络友好”的结构和语法,有利于对误码和丢包的处理;应用目标范围较宽,以满足不同速率、不同解析度以及不同传输(存储)场合的需求。
技术上,它集中了以往标准的优点,并吸收了标准制定中积累的经验。与H.263 v2(H.263+)或MPEG-4简单类(Simple Profile)相比,H.264在使用与上述编码方法类似的最佳编码器时,在大多数码率下最多可节省50%的码率。H.264在所有码率下都能持续提供较高的视频质量。H.264能工作在低延时模式以适应实时通信的应用(如视频会议),同时又能很好地工作在没有延时限制的应用,如视频存储和以服务器为基础的视频流式应用。H.264提供包传输网中处理包丢失所需的工具,以及在易误码的无线网中处理比特误码的工具。
在系统层面上,H.264提出了一个新的概念,在视频编码层(Video Coding Layer, VCL)和网络提取层(Network Abstraction Layer, NAL)之间进行概念性分割,前者是视频内容的核心压缩内容之表述,后者是通过特定类型网络进行递送的表述,这样的结构便于信息的封装和对信息进行更好的优先级控制。
3.3 H.264标准的关键技术
·帧内预测编码
帧内编码用来缩减图像的空间冗余。为了提高H.264帧内编码的效率,在给定帧中充分利用相邻宏块的空间相关性,相邻的宏块通常含有相似的属性。因此,在对一给定宏块编码时,首先可以根据周围的宏块预测(典型的是根据左上角的宏块,因为此宏块已经被编码处理),然后对预测值与实际值的差值进行编码,这样,相对于直接对该帧编码而言,可以大大减小码率。
H.264提供6种模式进行4×4像素宏块预测,包括1种直流预测和5种方向预测,如图2所示。在图中,相邻块的A到I共9个像素均已经被编码,可以被用以预测,如果我们选择模式4,那么,a、b、c、d4个像素被预测为与E相等的值,e、f、g、h4个像素被预测为与F相等的值,对于图像中含有很少空间信息的平坦区,H.264也支持16×16的帧内编码。
·帧间预测编码
帧间预测编码利用连续帧中的时间冗余来进行运动估计和补偿。H.264的运动补偿支持以往的视频编码标准中的大部分关键特性,而且灵活地添加了更多的功能,除了支持P帧、B帧外,H.264还支持一种新的流间传送帧——SP帧。码流中包含SP帧后,能在有类似内容但有不同码率的码流之间快速切换,同时支持随机接入和快速回放模式。图3 SP-帧示意图H.264的运动估计有以下4个特性。
(1)不同大小和形状的宏块分割
对每一个16×16像素宏块的运动补偿可以采用不同的大小和形状,H.264支持7种模式,如图4所示。小块模式的运动补偿为运动详细信息的处理提高了性能,减少了方块效应,提高了图像的质量。
(2)高精度的亚像素运动补偿
在H.263中采用的是半像素精度的运动估计,而在H.264中可以采用1/4或者1/8像素精度的运动估值。在要求相同精度的情况下,H.264使用1/4或者1/8像素精度的运动估计后的残差要比H.263采用半像素精度运动估计后的残差来得小。这样在相同精度下,H.264在帧间编码中所需的码率更小。
(3)多帧预测
H.264提供可选的多帧预测功能,在帧间编码时,可选5个不同的参考帧,提供了更好的纠错性能,这样更可以改善视频图像质量。这一特性主要应用于以下场合:周期性的运动、平移运动、在两个不同的场景之间来回变换摄像机的镜头。
(4)去块滤波器
H.264定义了自适应去除块效应的滤波器,这可以处理预测环路中的水平和垂直块边缘,大大减少了方块效应。
·整数变换
在变换方面,H.264使用了基于4×4像素块的类似于DCT的变换,但使用的是以整数为基础的空间变换,不存在反变换,因为取舍而存在误差的问题。与浮点运算相比,整数DCT变换会引起一些额外的误差,但因为DCT变换后的量化也存在量化误差,与之相比,整数DCT变换引起的量化误差影响并不大。此外,整数DCT变换还具有减少运算量和复杂度,有利于向定点DSP移植的优点。
·量化
H.264中可选32种不同的量化步长,这与H.263中有31个量化步长很相似,但是在H.264中,步长是以12.5%的复合率递进的,而不是一个固定常数。在H.264中,变换系数的读出方式也有两种:之字形(Zigzag)扫描和双扫描。大多数情况下使用简单的之字形扫描;双扫描仅用于使用较小量化级的块内,有助于提高编码效率。
·.熵编码
视频编码处理的最后一步就是熵编码,在H.264中采用了两种不同的熵编码方法:通用可变长编码(UVLC)和基于文本的自适应二进制算术编码(CABAC)。
在H.263等标准中,根据要编码的数据类型如变换系数、运动矢量等,采用不同的VLC码表。H.264中的UVLC码表提供了一个简单的方法,不管符号表述什么类型的数据,都使用统一变字长编码表。其优点是简单;缺点是单一的码表是从概率统计分布模型得出的,没有考虑编码符号间的相关性,在中高码率时效果不是很好。
因此,H.264中还提供了可选的CABAC方法。算术编码使编码和解码两边都能使用所有句法元素(变换系数、运动矢量)的概率模型。为了提高算术编码的效率,通过内容建模的过程,使基本概率模型能适应随视频帧而改变的统计特性。内容建模提供了编码符号的条件概率估计,利用合适的内容模型,存在于符号间的相关性可以通过选择目前要编码符号邻近的已编码符号的相应概率模型来去除,不同的句法元素通常保持不同的模型。
·基本结构
H.264的编码器如图3-1所示,包含两条数据流路径,一条“前向”路径(从左到右,蓝色表示)和一条“重建”路径(从右到左,紫色表示)。

图3-1 H.264编码器模型
·前向路径:
Fn为当前输入帧。它以宏块为单元进行处理(对应原来图像的16×16个像素)。每个宏块按照帧内或者帧间模式被编码。无论那种模式,都会由重建帧形成一个预测块P。如果是帧内模式,P由当前已经被编码,解码并且重建的帧n的采样值来预测。如果是帧间模式,P从以前的一个或者多个运动参考帧的运动补偿中获得。即图中的F’n-1,每个宏块的预测可由以前的一帧或者几帧已经编码,重建的图像得到。
当前宏块减去预测值得到差值宏块Dn。Dn经过变换和量化后得到X(经过量化的变换系数)。这些系数被扫描后进行熵编码。然后和其他一些信息(比如宏块预测类型,量化步长以及运动矢量信息)形成压缩后的码流。最后送到NAL传输。重建路径:
量化好的宏块系数X将被解码以形成重建帧以供继续编码。X经过反量化,反变换后得到差值宏块D’n,因为量化产生误差,所以和原差值Dn不一样。预测宏块P加上D’n生成重建宏块uF’n。uF’n经过一个滤波器来减少块失真,得到F’n,由一系列的F’n得到重建帧。
·JM模型采用的搜索方法
在JM中运动搜索采用了一种更先进的快速搜索方法叫做非对称十字型多层次六边形格点搜索算法Search)。这是一项有中国专利的算法,由于它在低码率大运动的图像序列编码时,在保持较好率失真性能的条件下,运算量十分低,相对于H.264中原有的快速全搜索算法可节约90%以上的计算。现已被H.264标准正式采纳。
它的搜索过程也比较复杂,采用了非对称交叉搜索,不均匀多六边形格点搜索,扩展六边形搜索等多种先进的方法,是一种混合的搜索方式。
它主要有以下的四个步骤如下图所示:

图3-2 搜索步骤
其搜索方法主要有:1-根据预测信息初始化搜索中心;2-非对称交叉搜索;3-不均匀多六边形网格搜索;3-扩展六边形搜索;
3.5 H.264解码器的分析
解码器模型如图3-3所示:解码器从网络适配层接收码流。经过熵解码和重新排序后得到量化系数X。然后,再经过反量化,反变换后得到D`n。从码流的头信息,解码器建立一个预测宏块P,它和编码器中原来的P是一样的。P加上D`n得到Uf`n,滤波后得到解码宏块F`n,其基本结构如下所示:
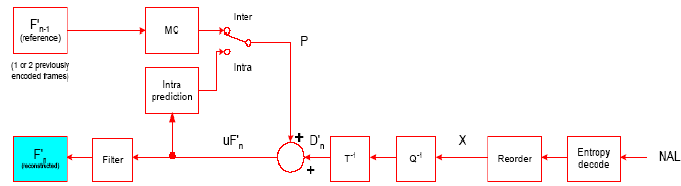
图3-3 解码器结构
H.264所采用的一些先进技术在解码器的各个部分中得到了相应的体现。在解码器的反变换中采用了由DCT变换改进而来的整数变换,它的预测不但有帧间预测模式还有帧内预测模式,解码后使用了去块效应的滤波器。
·变换和量化
无论是经过帧内预测还是帧间预测,残差宏块都需要进行变换和量化。以前的标准一般采用8×8的DCT变换。H.264根据残差数据的类型采用三种不同的方式:帧内编码宏块的亮度DC系数采用4×4的矩阵(仅对于16×16的预测模式);色度DC系数使用2×2的矩阵;其他的都采用4×4的块变换。宏块里数据块按图3-4所示的顺序传输。如果是16×16的帧内预测宏块,首先传输编号-1的亮度DC系数,然后是编号0-15的亮度残差数据,最后是编号16-25的色度DC和色度残差数据。
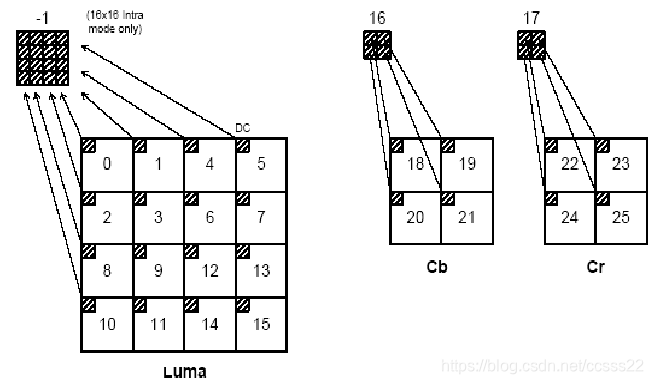
图3-4 宏块中残差块的扫描顺序
·帧间编码宏块的预测
帧间预测是从已经编码过的一帧或者几帧得到的。它是在参考帧采样点平面上进行平移(运动补偿预测)。相对于以前的视频标准,H.264支持更多种的块的划分(到4×4大小)和亚像素精度的运动矢量(到1/4像素精度)。帧内编码的每个块都是由参考帧中相同大小的的区域预测得到的。它们间的偏移量就是运动矢量。因为参考帧本身不可能有亚像素采样点,所以需要利用附近的像素内插产生亚像素的采样点。图3-5解释了它的内插过程。

图3-5 亚像素点产生示意图
半像素点的插值分别由水平和垂直方向的6阶的FIR滤波器产生。1/4像素点在整数像素点和半像素点上进行插值。
3.6 H.264的变换算法
H.264中的整型变换方式主要有3种:4*4残差变换,4*4亮度DC系数变换(16*16帧内模式下),2*2色度DC系数变换。H.264协议中的量化采用分级量化原理。H.264的变换和量化如图3.6所示。

图3-6 H.264变换与量化
·H.264的4*4残留变换
4*4残留变换及图3-7所示的4*4变换1,它是以下式为变换核的整形变换,二维整型变换通常可以分解为一维的形式,先进行4行一维整数变换,再进行4列一维整数变换。一维整数变换公式为:
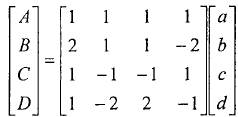
一维反变换公式:
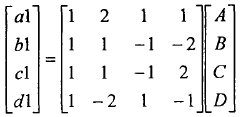
式中A,B,C,D表示变换系数;a,b,e,d表示输入象素;al,bl,cl,dl表示恢复系数。对上式分析可知,变换的系数均为整数,这样通过移位,加减就可以实现其算法。
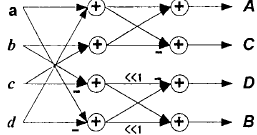
图3-7 整型正变换蝶形图
·H.264亮度直流系数变换
当宏块的编码在16*6l帧内模式下,此时整个16*16块的亮度分量是由相邻象素点预测得到。宏块的16个4*4块的直流分量组成一个4X4直流系数矩阵Xl,这个矩阵的变换采用离散哈达马变换(DiscretelldamaardTransform,DHT),如图所示4*4变换2。
正向变换公式:

反变换公式:
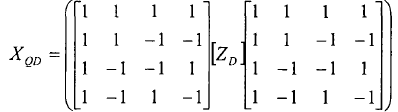
式中ZD是几量化后的矩阵,XQD经反量化可以得到.在帧内编码的宏块里,大多数的能量都集中在直流系数上,这种变换有利于进一步压缩4*4的亮度直流信号的相关性。
本课题,我们调试的JM7.3版本。首先下载并解压JM测试模型,在子目录在新建一个mybin的文件夹,把bin的文件拷入mybin的文件里:

图4-1 JM文件夹中所包含的文件
打开工程文件jm.dsw.进入VC界面。
在file选择new,新建一个myencoder.cfg(在lend工程下)在路径下选择mybin文件路径.确定。

图4-2 打开工程
这时在lendcod files下的Header Files下多了一个myencoder.cfg..电击encoder.cfg在右边出现的批配置。
. 
图4-3 参数配置文件
在lendcod files下的Header Files下的configfile.h文件的
#define DEFAULTCONFIGFILENAME “encoder.cfg”
改为
#define DEFAULTCONFIGFILENAME “myencoder.cfg”
然后在选中lencod files 在工程的菜单下setting的DEBUG设置如图参数设置:

图4-4 设置界面
然后编译,若要修改某个参数。可直接在myencoder.cfg中修改。比如YUV文件,设置文件的安放路径为E:\视频编码的其他版本\JM路径下的dancer_cif_ori90.yuv。我们在myencoder.cfg中InputFile = “E:\视频编码的其他版本\JM\dancer_cif_ori90.yuv”
4.2 H.264解码器库文件的使用方法
·接口函数信息
1.void JVT_init(struct inp_par*input,struct img_par*img,
StorablePicture*dec_picture,char*filename);
功能:解码器的初始化。
参数信息:struct inp_par*input――――配置信息参数
struct img_par*img――――图像信息参数
StorablePicture*dec_picture――――解码后的图像序列
Char*filename――――输入的H.264文件的文件名
2.void JVT_dec(struct inp_par*input,struct img_par*img,
NALU_t*nalu,int*current_header);
功能:解码第i帧。
参数信息:struct inp_par*input――――配置信息参数
struct img_par*img――――图像信息参数
NALU_t*nalu――――指向nalu单元的指针
int*current_header――――帧头信息
3.void JVT_free(struct inp_par*input,struct img_par*img,
ColocatedParams*Co_located);
功能:销毁解码器,释放资源。
参数信息:struct inp_par*input――――配置信息参数
struct img_par*img――――图像信息参数
ColocatedParams*Co_located――――存储单元分配参数
4.NALU_t*AllocNALU(int buffersize);
功能:分配NALU单元。
参数信息:int buffersize――――单元大小
5.void FreeNALU(NALU_t*n);
功能:释放NALU单元。
参数信息:NALU_t*n――――NALU单元地址
6.void CloseBitstreamFile();
功能:关闭文件。
由于jm进行编码的是都是YUV文件,所以我们首先下载一个YUV播放器。

图4-5 YUV播放器
该播放器是由VC开发的。是一个WINDOWS下的播放器,它可以播放YUV,m4u和264多种格式的视频文件。可以同时打开多个窗口,可以单帧和连续播放视频。为了便于对不同格式图像的主观质量进行比较还加入了图像放大功能。
其具有VideoPlayer的播放部分和解码部分分开处理,解码部分采用单独的解码库delib.lib和libxvidcore.lib分别解码MPEG-4和H.264格式的视频文件等功能。
4.3 JM程序调试
我们首先运行JM程序,得到如下的结果。
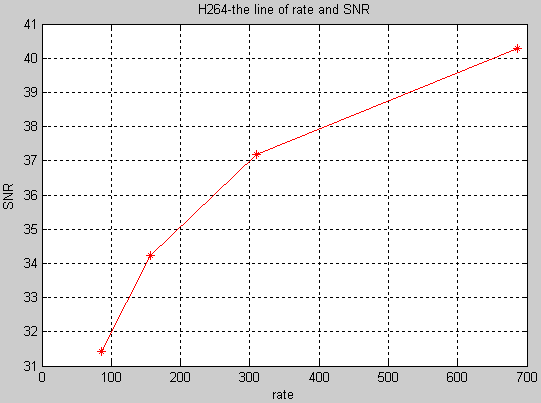
图4-6 JM运行结果
由此可知,输入的视频文件为foreman_part_qcif.yuv,输出文件有四个。且其中输出的播放文件是test_rec.yuv。我们首先来波形两个文件,来主管的对比效果。

图4-7 H.264压缩前后效果对比
下面我们对进行H.264压缩前后其信噪比进行分析。

图4-8 H.264信噪比分析
通过仿真,我们可以发现,当比特率越大的时候,信噪比就越大。
以前av信息被看作纯粹的数据,编码时没有结合自身包含的内容,例如视频序列被认为是象素的组合。MPEG4采用了对象的概念,不同的数据源被视作不同的对象,分别编码。数据的接收者不再是被动的,他可以对不同的对象进行自己的操作:删除、添加、移动等。语音、图像、视频等可以作为单独存在的对象,也可以集合成一个更高层的对象,我们称之为场景。MPEG4在编码前首先要对视频序列进行分析和理解以提取目标。
一幅复杂的画面就由这些可操作的原始目标组成。如果对这些目标分别进行编码 ,最终用户便可以自由地操纵这些原始目标 (如目标的坐标 ,视点 ,动画等 ),还可得到一些原始目标的信息。
优点:
不同对象的独立编码可以取得较高的压缩性能,如背景采用压缩比较高、损失较大的办法编码,运动物体采用压缩比较低、损失较小的办法,在压缩效率与解码质量间得到较好的平衡。同时也带来在终端处可以操纵内容的能力。而传统的压缩方法是基于帧、基于块的 ,压缩性能不高且无法对对象进行操作。MPEG4中的对象操作使得用户可以在用户端直接将不同对象进行拼接 ,得到用户自己合成的图像,这在传统方法中是无法直接实现的。
对比MPEG4和H.264其信号噪比如下所示:

图4-9 H.264和MPEG4信噪比分析
从上图分析,H.264的编码性能由于MPEG4新能,且当比特率越大的时候,性能优势更大。
TML-8为H.264的测试模式,用它来对H.264的视频编码效率进行比较和测试。测试结果所提供的PSNR已清楚地表明,相对于MPEG-4(ASP:Advanced Simple Profile)和H.263++(HLP:High Latency Profile)的性能,H.264的结果具有明显的优越性。
H.264的PSNR比MPEG-4(ASP)和H.263++(HLP)明显要好,在6种速率的对比测试中,H.264的PSNR比MPEG-4(ASP)平均要高2dB,比H.263(HLP)平均要高3dB。6个测试速率及其相关的条件分别为:32 kbit/s速率、10f/s帧率和QCIF格式;64 kbit/s速率、15f/s帧率和QCIF格式;128kbit/s速率、15f/s帧率和CIF格式;256kbit/s速率、15f/s帧率和QCIF格式;512 kbit/s速率、30f/s帧率和CIF格式;1024 kbit/s速率、30f/s帧率和CIF格式。