前言
本节重点讲解了 H.264 编码以及 AAC 编码,在对其进行讲解前先介绍了视频编码的实现原理。
一、视频编码的实现原理
1、视频编码技术的基本原理
编码就是为了压缩。要实现压缩,就要设计各种算法,将视频数据中的冗余信息去除。
| 种类 | 内容 | 压缩方法 |
|---|---|---|
| 空间冗余 | 像素间的相关性 | 变换编码,预测编码 |
| 时间冗余 | 时间方向上的相关性 | 帧间预测,运动补偿 |
| 图像构造冗余 | 图像本身的构造 | 轮廓编码,区域分割 |
| 知识冗余 | 收发两端对人物的共有认识 | 基于知识的编码 |
| 视觉冗余 | 人的视觉特性 | 非线性量化,位分配 |
| 其他 | 不确定因素 |
视频编码技术优先消除的目标,就是空间冗余和时间冗余。
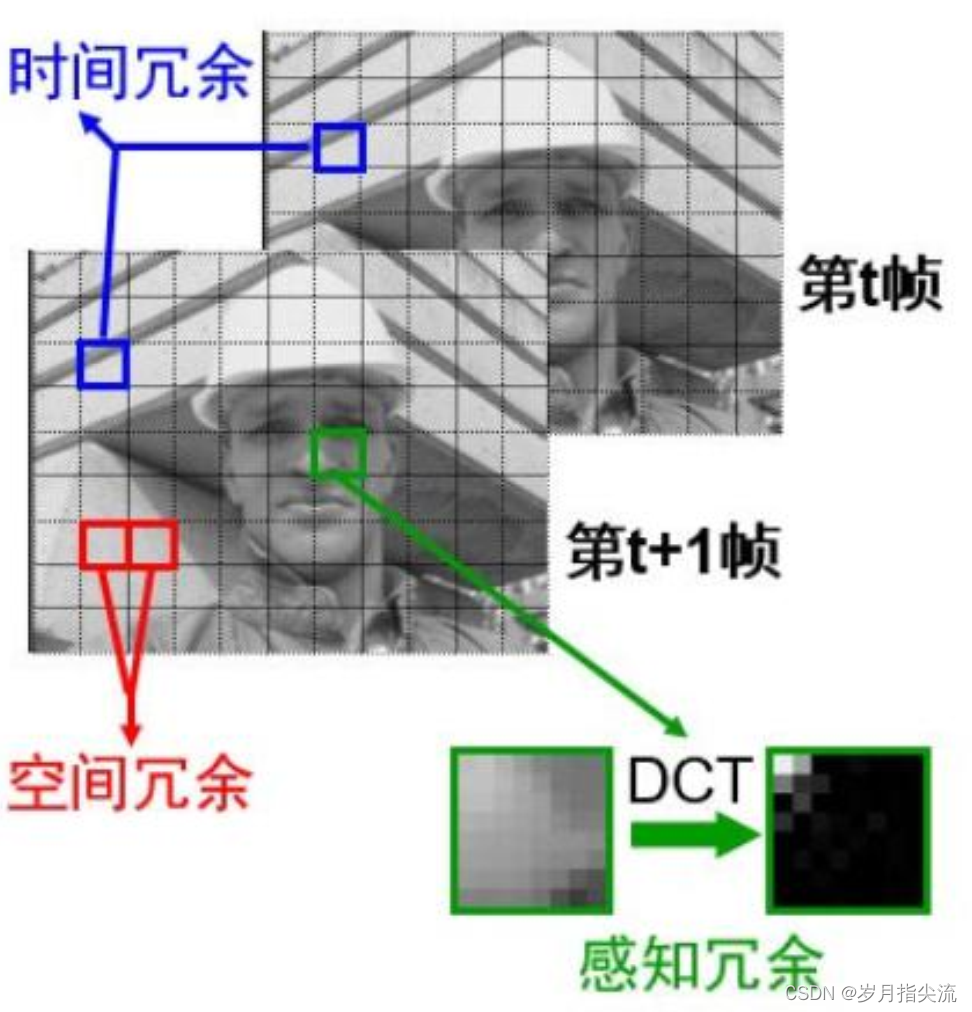
2、视频编码技术的实现方法
视频是由不同的帧画面连续播放形成的。这些帧,主要分为三类,分别是:
- I 帧
- 是自带全部信息的独立帧,是最完整的画面(占用的空间最大),无需参考其它图像便可独立进行解码。视频序列中的第一个帧,始终都是 I 帧。
- B 帧
- “双向预测编码帧”,以前帧后帧作为参考帧。不仅参考前面,还参考后面的帧,所以,它的压缩率最高,可以达到 200:1。不过,因为依赖后面的帧,所以不适合实时传输(例如视频会议)。
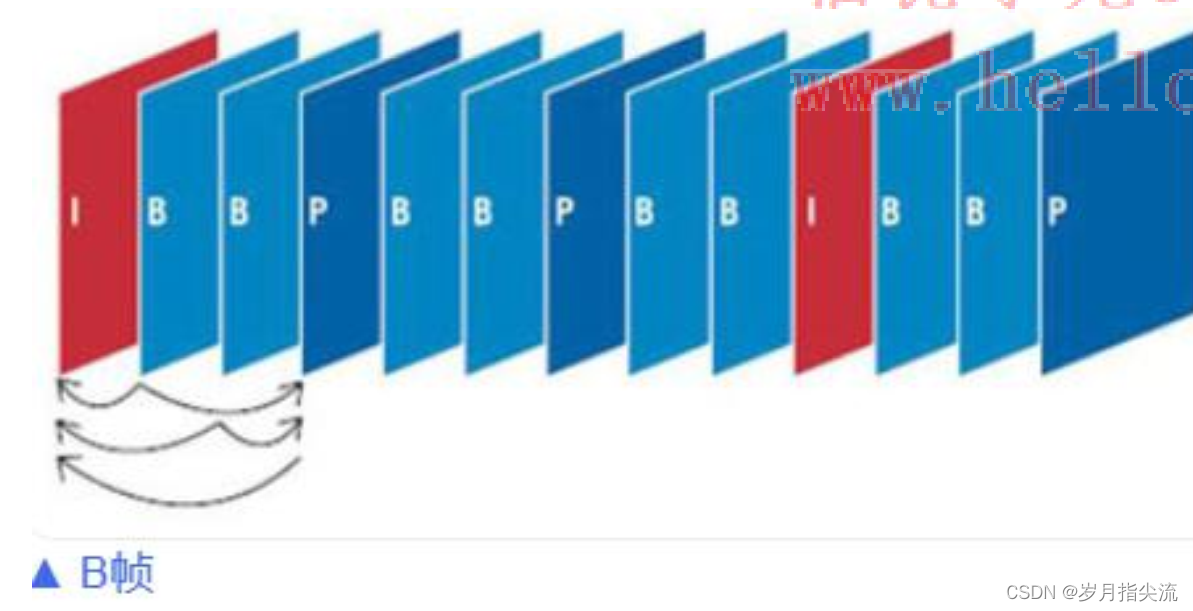
- “双向预测编码帧”,以前帧后帧作为参考帧。不仅参考前面,还参考后面的帧,所以,它的压缩率最高,可以达到 200:1。不过,因为依赖后面的帧,所以不适合实时传输(例如视频会议)。
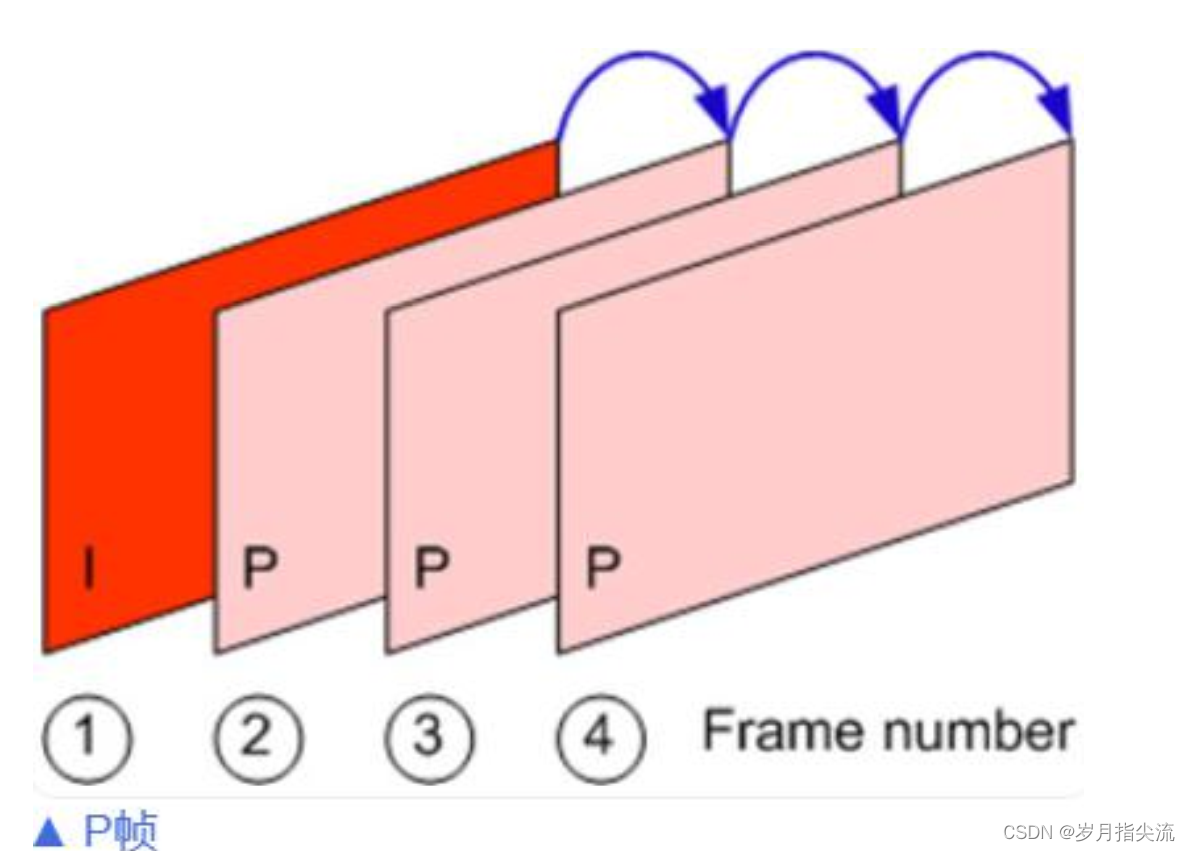
- P 帧
- “帧间预测编码帧”,需要参考前面的 I 帧和/或 P 帧的不同部分,才能进行编码。P 帧对前面的 P 和 I 参考帧有依赖性。但是,P 帧压缩率比较高,占用的空间较小。
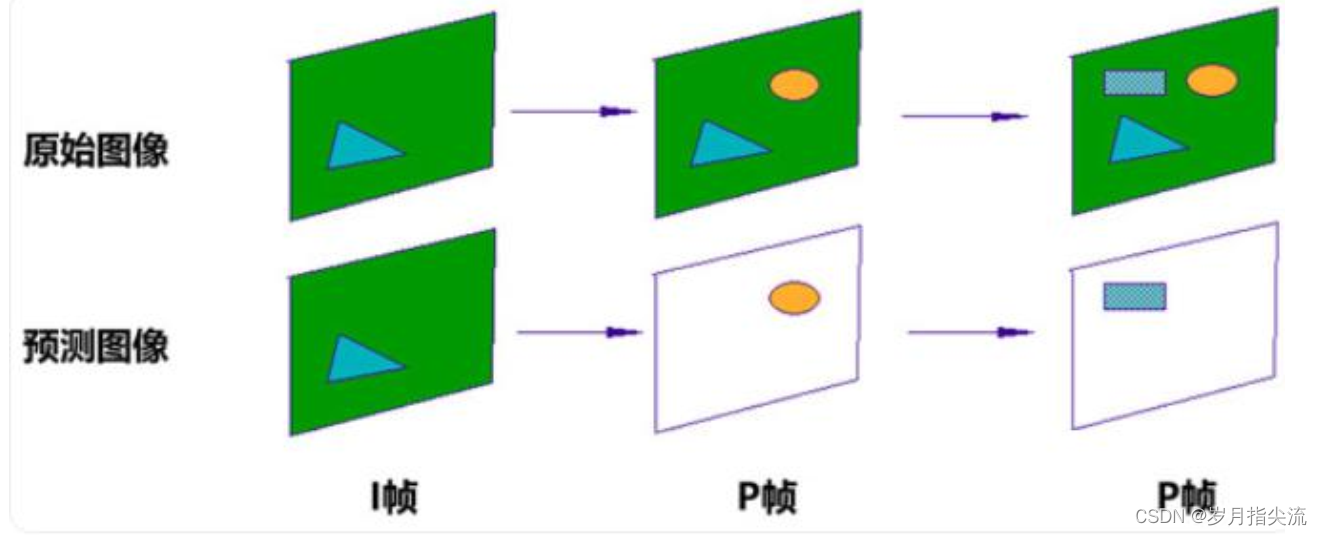
通过对帧的分类处理,可以大幅压缩视频的大小。
- “帧间预测编码帧”,需要参考前面的 I 帧和/或 P 帧的不同部分,才能进行编码。P 帧对前面的 P 和 I 参考帧有依赖性。但是,P 帧压缩率比较高,占用的空间较小。
毕竟,要处理的对象,大幅减少了(从整个图像,变成图像中的一个区域)。
3、运动估计和补偿
①、块(Block)与宏块(MicroBlock)
如果总是按照像素来算,数据量会比较大,所以,一般都是把图像切割为不同的“块(Block)”或“宏块(MacroBlock)”,对它们进行计算。
一个宏块一般为 16 像素×16 像素。

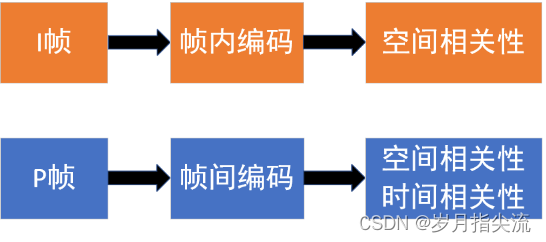
②、I 帧、P 帧、B 帧的小结
- 对 I 帧的处理,是采用帧内编码方式,只利用本帧图像内的空间相关性。
- 对 P 帧的处理,采用帧间编码(前向运动估计) ,同时利用空间和时间上的相关性。
简单来说,采用运动补偿(motion compensation)算法来去掉冗余信息。
③、I 帧(帧内编码)
需要特别注意,I 帧(帧内编码),虽然只有空间相关性,但整个编码过程也不简单。
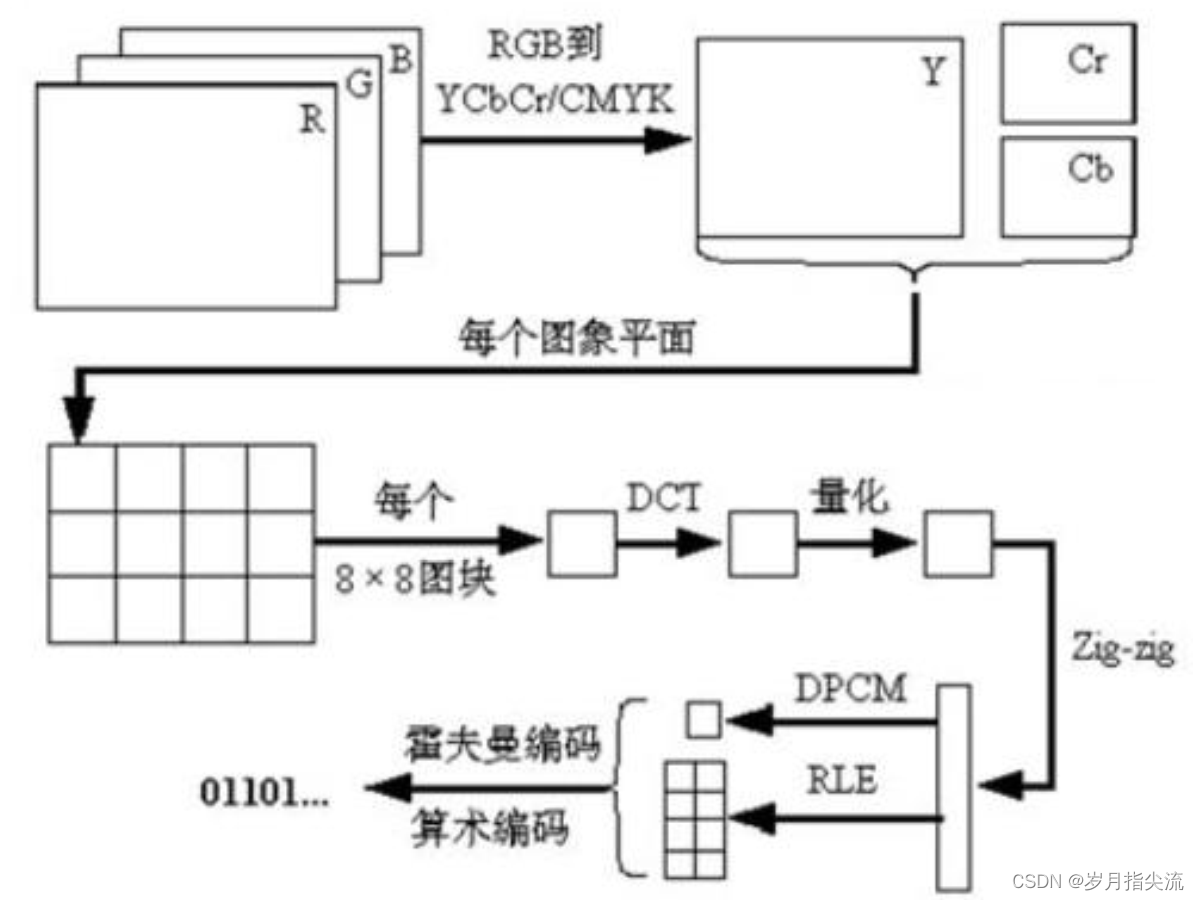
如上图所示,整个帧内编码,还要经过 DCT(离散余弦变换)、量化、编码等多个过程。
- RGB 转 YUV:固定公式
- 图片宏块切割:宏块 16x16
- DCT:离散余弦变换
- 量化:取样
- ZigZag 扫描:
- DPCM:差值脉冲编码调制
- RLE:游程编码
- 算数编码:
④、如何衡量和评价编解码的效果
一般来说,分为客观评价和主观评价。客观评价,就是拿数字来说话。例如计算“信噪比/峰值信噪比”
一般来说,分为客观评价和主观评价。
- 客观评价,就是拿数字来说话。例如计算“信噪比/峰值信噪比”。
- 主观评价,就是用人的主观感知直接测量。
二、H.264 编码基础
1、H.264 快速入门
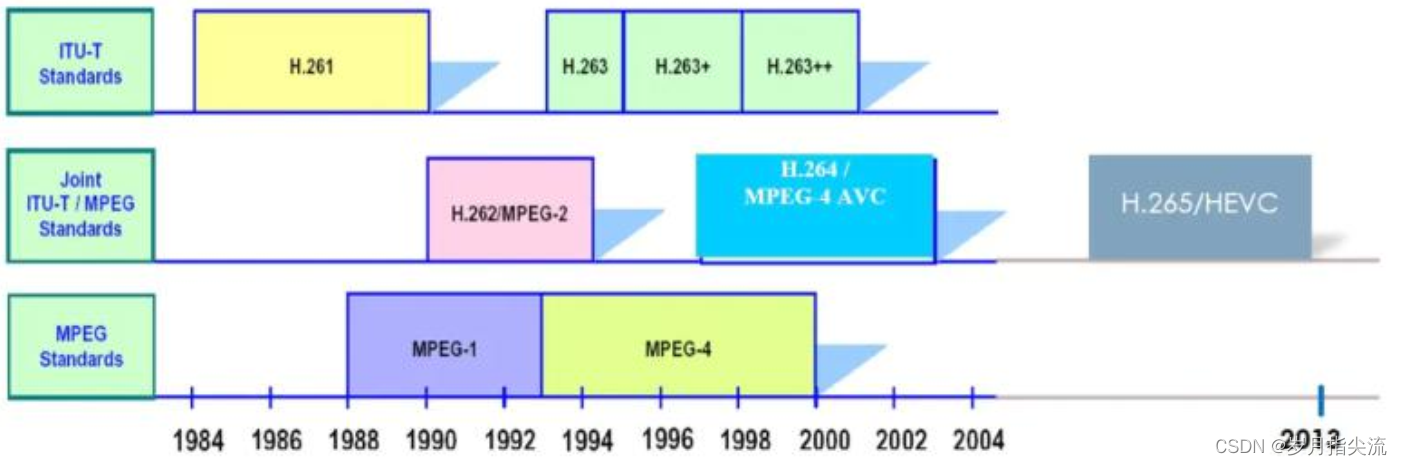
①、视频编码标准化组织
从事视频编码算法的标准化组织主要有两个,ITU-T 和 ISO。
- ITU-T,国际电信联盟——电信标准分局,主要制定了 H.261/H263/H263+/H263++ 等标准
- ISO,国际标准化组织,主要制定了 MPEG-1/MPEG-4 等
比如 MPEG-2、 H.264/AVC 和 H.265/HEVC 等。不同标准组织制定的视频编码标准的发展如下图所示:
②、视频压缩编码的基本技术
视频信息之所以存在大量可以被压缩的空间, 是因为其中本身就存在大量的数据冗余。
其主要类型有:
- 时间冗余:视频相邻的两帧之间内容相似,存在运动关系
- 空间冗余:视频的某一帧内部的相邻像素存在相似性
- 编码冗余:视频中不同数据出现的概率不同
- 视觉冗余: 观众的视觉系统对视频中不同的部分敏感度不同
针对这些不同类型的冗余信息,在各种视频编码的标准算法中都有不同的技术专门应对,以通过不同的角度提高压缩的比率。
<1>、预测编码
预测编码可以用于处理视频中的时间和空间域的冗余。
视频处理中的预测编码主要分为两大类:帧内预测和帧间预测。
- 帧内预测:预测值与实际值位于同一帧内,用于消除图像的空间冗余;帧内预测的特点是压缩率相对较低,然而可以独立解码,不依赖其他帧的数据;通常视频中的关键帧都采用帧内预测。
- 帧间预测:帧间预测的实际值位于当前帧,预测值位于参考帧,用于消除图像的时间冗余;帧间预测的压缩率高于帧内预测,然而不能独立解码,必须在获取参考帧数据之后才能重建当前帧。
通常在视频码流中,I 帧全部使用帧内编码,P 帧/B 帧中的数据可能使用帧内或者帧间编码。
<2>、变换编码
所谓变换编码是指,将给定的图象变换到另一个数据域如频域上,使得大量的信息能用较少的数据来表示,从而达到压缩的目的。
目前主流的视频编码算法均属于有损编码,通过对视频造成有限而可以容忍的损失,获取相对更高的编码效率。
而造成信息损失的部分即在于变换量化这一部分。
在进行量化之前,首先需要将图像信息从空间域通过变换编码变换至频域,并计算其变换系数供后续的编码。
在视频编码算法中通常使用正交变换进行变换编码,常用的正交变换方法有:离散余弦变换(DCT)、 离散正弦变换(DST)、K-L 变换等。
<3>、熵编码
视频编码中的熵编码方法主要用于消除视频信息中的统计冗余。
由于信源中每一个符号出现的概率并不一致,这就导致使用同样长度的码字表示所有的符号会造成浪费。
通过熵编码,针对不同的语法元素分配不同长度的码元,可以有效消除视频信息中由于符号概率导致的冗余。
在视频编码算法中常用的熵编码方法有变长编码和算术编码等,具体来说主要有:
- UVLC(Universal Variable Length Coding):主要采用指数哥伦布编码
- CAVLC(Context Adaptive Variable Length Coding):上下文自适应的变长编码
- CABAC(Context Adaptive Binary Arithmetic Coding):上下文自适应的二进制算数编码
根据不同的语法元素类型指定不同的编码方式。 通过这两种熵编码方式达到一种编码效率与
运算复杂度之间的平衡。
③、VCL NAL
视频编码中采用的如预测编码、变化量化、熵编码等编码工具主要工作在 slice 层或以下,这一层通常被称为“视频编码层”(Video Coding Layer, VCL)。
相对的,在 slice 以上所进行的数据和算法通常称之为“网络抽象层”(Network Abstraction Layer, NAL)。
设计定义 NAL 层的主要意义在于提升 H.264 格式的视频对网络传输和数据存储的亲和性。
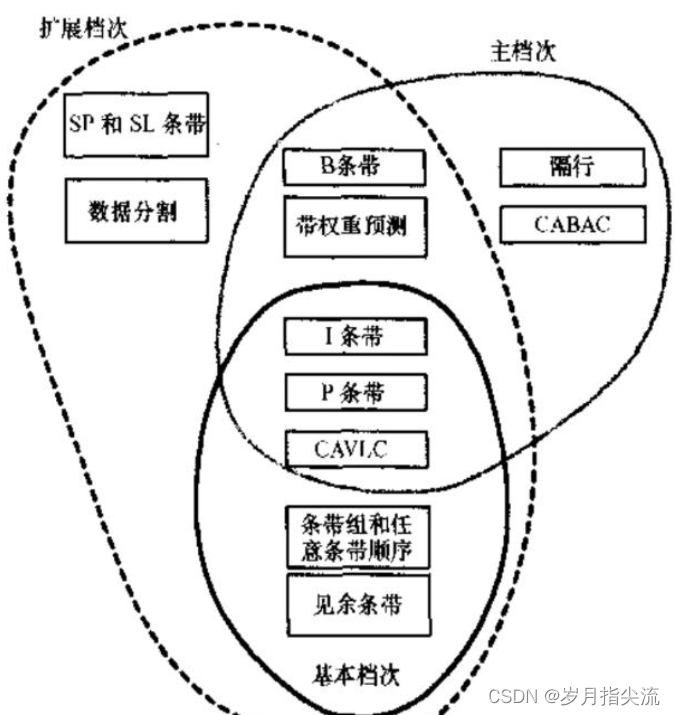
④、档次与级别
为了适应不同的应用场景,H.264 也定义了三种不同的档次:
- 基准档次(Baseline Profile):主要用于视频会议、可视电话等低延时实时通信领域;支持 I 条带和 P 条带,熵编码支持 CAVLC 算法。
- 主要档次(Main Profile):主要用于数字电视广播、数字视频数据存储等;支持视频场编码、B 条带双向预测和加权预测,熵编码支持 CAVLC 和 CABAC 算法。
- 扩展档次(Extended Profile):主要用于网络视频直播与点播等;支持基准档次的所有特性,并支持 SI 和 SP 条带,支持数据分割以改进误码性能,支持 B 条带和加权预测,但不支持 CABAC 和场编码。
CAVLC 支持所有的 H.264 profiles,CABAC 则不支援 Baseline 以及 Extended profiles。
⑤、常见编码器
H.264 是一种视频压缩标准, 其只规定了符合标准的码流的格式, 以及码流中各个语法元素的解析方法。H.264 标准并未规定编码器的实现或流程,这给了不同的厂商或组织在编码实现方面极大的自由度, 并产生了一些比较著名的开源 H.264 编解码器工程。
其中 H.264 编码器中最著名的两个当属 JM 和 X264, 这二者都属于 H.264 编码标准的一种实现形式。
JM encoder 实在太慢了,x264则相当快.
2、H.264 编码原理与实现
①、前言
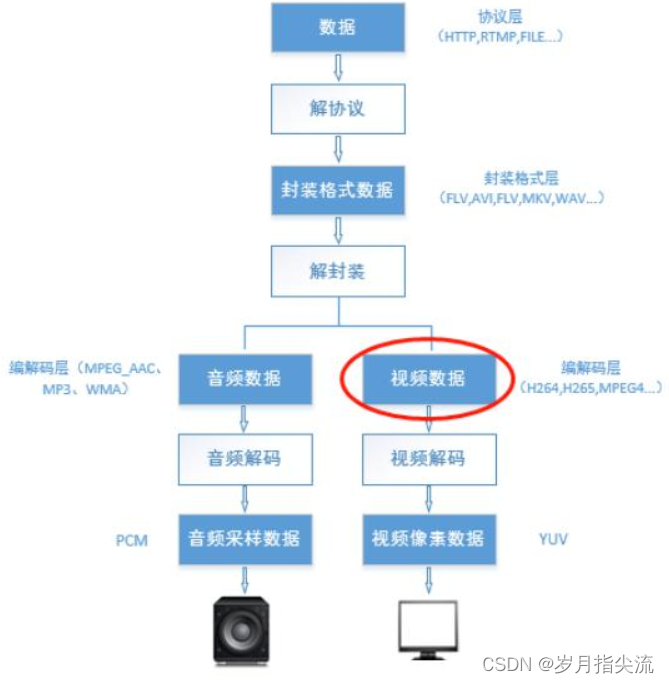
H264 在视频采集到输出中属于编解码层次的数据,如下图所示,是在采集数据后做编码压缩时通过编码标准编码后所呈现的数据。
②、H264 相关概念
<1>、序列
H264 编码标准中所遵循的理论依据个人理解成:参照一段时间内相邻的图像中, 像素、 亮度与色温的差别很小。
所以当面对一段时间内图像我们没必要去对每一幅图像进行完整一帧的编码,而是可以选取这段时间的第一帧图像作为完整编码,而下一幅图像可以记录与第一帧完整编码图像像素、亮度与色温等的差别即可,以此类推循环下去。
什么叫序列呢?上述的这段时间内图像变化不大的图像集我们就可以称之为一个序列。 序列可以理解为有相同特点的一段数据。
<2>、帧类型
H264 结构中,一个视频图像编码后的数据叫做一帧,一帧由一个片(slice)或多个片组成,一个片由一个或多个宏块(MB)组成,一个宏块由 16x16 的 yuv 数据组成。宏块作为 H264 编码的基本单位。
在 H264 协议内定义了三种帧,分别是 I 帧、B 帧与 P 帧。
<3>、GOP(画面组,图像组)
GOP 我个人也理解为跟序列差不多意思,就是一段时间内变化不大的图像集。
GOP 结构一般有两个数字,如 M=3,N=12。M 指定 I 帧和 P 帧之间的距离,N 指定两个 I 帧之间的距离。
上面的 M=3,N=12,GOP 结构为: IBBPBBPBBPBBI。
在一个 GOP 内 I frame 解码不依赖任何的其它帧,p frame 解码则依赖前面的 I frame 或 P frame,B frame 解码依赖前最近的一个 I frame 或 P frame 及其后最近的一个 P frame。
<4>、IDR 帧(关键帧)
在编码解码中为了方便,将 GOP 中首个 I 帧要和其他 I 帧区别开,把第一个 I 帧叫 IDR,这样方便控制编码和解码流程,所以 IDR 帧一定是 I 帧,但 I 帧不一定是 IDR 帧;IDR 帧的作用是立刻刷新,使错误不致传播,从 IDR 帧开始算新的序列开始编码。I 帧有被跨帧参考的可能,IDR 不会。
I 帧不用参考任何帧,但是之后的 P 帧和 B 帧是有可能参考这个 I 帧之前的帧的。
IDR 就不允许这样, 例如:
IDR1 P4 B2 B3 P7 B5 B6 I10 B8 B9 P13 B11 B12 P16 B14 B15
这里的 B8 可以跨过 I10 去参考 P7
IDR1 P4 B2 B3 P7 B5 B6 IDR8 P11 B9 B10 P14 B11 B12
这里的 B9 就只能参照 IDR8 和 P11,不可以参考 IDR8 前面的帧
作用:
H.264 引入 IDR 图像是为了解码的重同步,当解码器解码到 IDR 图像时,立即将参考帧队列清空,将已解码的数据全部输出或抛弃,重新查找参数集, 开始一个新的序列。 这样,如果前一个序列出现重大错误,在这里可以获得重新同步的机会。IDR 图像之后的图像永远不会使用 IDR 之前的图像的数据来解码。
③、H264 压缩方式
H264 采用的核心算法是帧内压缩和帧间压缩, 帧内压缩是生成 I 帧的算法, 帧间压缩是生成 B 帧和 P 帧的算法。
- 帧内(Intraframe)压缩也称为空间压缩(Spatialcompression)。当压缩一帧图像时,仅考虑本帧的数据而不考虑相邻帧之间的冗余信息,这实际上与静态图像压缩类似。帧内一般采用有损压缩算法,由于帧内压缩是编码一个完整的图像,所以可以独立的解码、显示。帧内压缩一般达不到很高的压缩,跟编码 jpeg 差不多
- 帧间(Interframe)压缩的原理是:相邻几帧的数据有很大的相关性,或者说前后两帧信息变化很小的特点。也即连续的视频其相邻帧之间具有冗余信息,根据这一特性,压缩相邻帧之间的冗余量就可以进一步提高压缩量,减小压缩比。帧间压缩也称为时间压缩(Temporalcompression),它通过比较时间轴上不同帧之间的数据进行压缩。帧间压缩一般是无损的。帧差值(Framedifferencing)算法是一种典型的时间压缩法,它通过比较本帧与相邻帧之间的差异,仅记录本帧与其相邻帧的差值,这样可以大大减少数据量。
压缩方式说明
- Step1:分组,也就是将一系列变换不大的图像归为一个组,也就是一个序列,也可以叫 GOP(画面组) ;
- Step2:定义帧,将每组的图像帧归分为 I 帧、P 帧和 B 帧三种类型;
- Step3:预测帧,以 I 帧做为基础帧,以 I 帧预测 P 帧,再由 I 帧和 P 帧预测 B 帧;
- Step4:数据传输,最后将 I 帧数据与预测的差值信息进行存储和传输。
④、H264 分层结构
H.264 原始码流(裸流)是由一个接一个 NALU 组成,它的功能分为两层,VCL(视频编码层)和 NAL(网络提取层)
H264 的主要目标是为了有高的视频压缩比和良好的网络亲和性,为了达成这两个目标,H264 的解决方案是将系统框架分为两个层面,分别是视频编码层面(VCL) 和网络抽象层面(NAL),如下图;
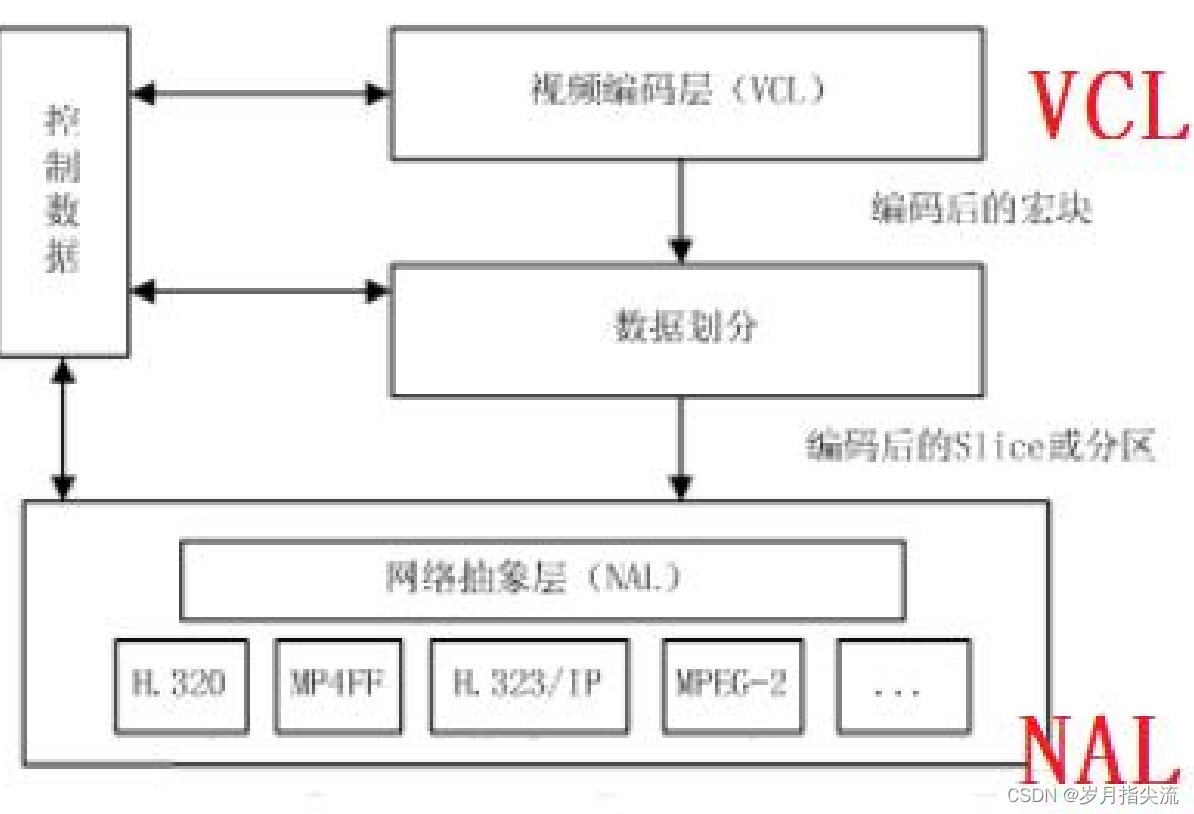
- VCL 层(视频编码层)是对核心算法引擎、块、宏块及片的语法级别的定义,负责有效表示视频数据的内容,最终输出编码完的数据 SODB
- 对视频的原始数据进行压缩。
- NAL 层(视频数据网络抽象层)定义了片级以上的语法级别(如序列参数集参数集和图像参数集,针对网络传输,后面会描述到),负责以网络所要求的恰当方式去格式化数据并提供头信息,以保证数据适合各种信道和存储介质上的传输。NAL 层将 SODB 打包成RBSP 然后加上 NAL 头组成一个 NALU 单元。
- 因为 H264 最终还是要在网络上进行传输,在传输的时候,网络包的最大传输单元是 1500 字节,一个 H264 的帧往往是大于 1500 字节的,所以需要将一个帧拆成多个包进行传输。这些拆包、组包等工作都在 NAL 层去处理。
<1>、SODB 与 RBSP 的关联
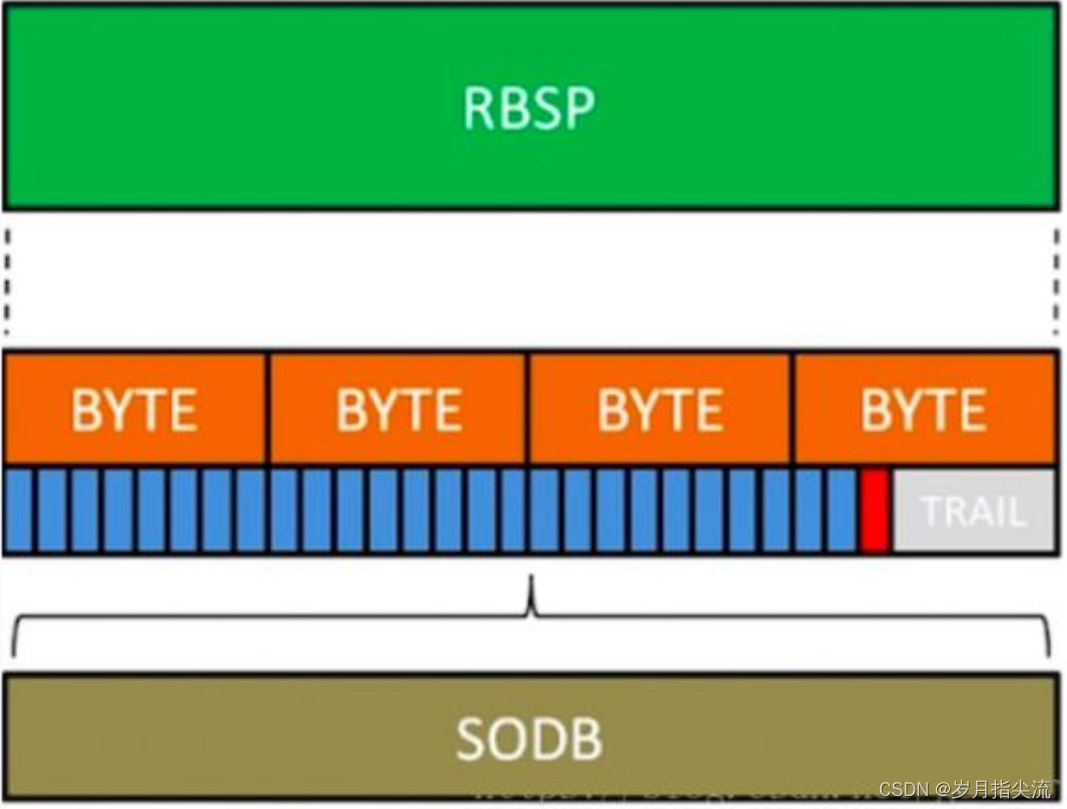
具体结构如下图所示:
- SODB:数据比特串,是编码后的原始数据;
- RBSP:原始字节序列载荷,是在原始编码数据后面添加了结尾比特,一个 bit“1”和若干个比特“0”,用于字节对齐。
<2>、SODB RBSP EBSP 的区别
- SODB(String of Data Bits,数据比特串)
- 最原始, 未经过处理的编码数据
- 因为它是流的形式,所以长度不一定是 8 倍数,它是由 VLC 层产生的。由于我们计算机是以 8 倍数去处理数据所以计算机在处理 H264 时,就需要 RBSP。
- RBSP(Raw Byte Sequence Payload,原始字节序列载荷)
- 在 SODB 的后面填加了结尾 bit(RBSP trailing bits 一个 bit ‘1’) 若干 bit ‘0’,以便字节对齐。
- 由于它是一个压缩流,SODB 不知道是在何处结束,所以算法在 SODB 最后一位补一个 1,没有按字节对齐的则补 0。
- EBSP(Encapsulated Byte Sequence Payload,扩展字节序列载荷)
- NALU 的起始码为 0x000001 或 0x00000001(起始码包括两种:3 字节(0x000001)和 4 字节(0x00000001),在 SPS、PPS 和 Access Unit 的第一个 NALU 使用 4 字节起始码,其余情况均使用 3 字节起始码。)
- 在生成压缩流之后,在每一帧的开头加一个起始位,这个起始位一般是 00 00 00 01 或者是 00 00 01。所以在 h264 码流中规定每有两个连续的 00 00,就增加一个 0x03。
- 仿校验字节(0x03)
- 同时 H264 规定,当检测到 0x000000 时,也可以表示当前 NALU 的结束。那这样就会产生一个问题,就是如果在 NALU 的内部,出现了 0x000001 或 0x000000 时该怎么办?
- 在 RBSP 基础上填加了仿校验字节(0x03)它的原因是:在 NALU 加到 Annexb 上时,需要填加每组 NALU 之前的开始码 StartCodePrefix,如果该 NALU 对应的 slice为一帧的开始则用 4 位字节表示,0x00000001,否则用 3 位字节表示 0x000001,为了使 NALU 主体中不包括与开始码相冲突的,在编码时,每遇到两个字节连续为 0,就插入一个字节的 0x03。解码时将 0x03 去掉。也称为脱壳操作。
关系图:

为什么要弄一个 EBSP 呢?
EBSP 相较于 RBSP, 多了防止竞争的一个字节: 0x03。
我们知道,NALU 的起始码为 0x000001 或 0x00000001,同时 H264 规定,当检测到 0x000000 时,也可以表示当前 NALU 的结束。那这样就会产生一个问题,就是如果在 NALU 的内部,出现了 0x000001 或 0x000000 时该怎么办?
所以 H264 就提出了“防止竞争”这样一种机制,当编码器编码完一个 NAL 时,应该检测 NALU 内部,是否出现如下左侧的四个序列。当检测到它们存在时,编码器就在最后一个字节, 插入一个新的字节:0x03。
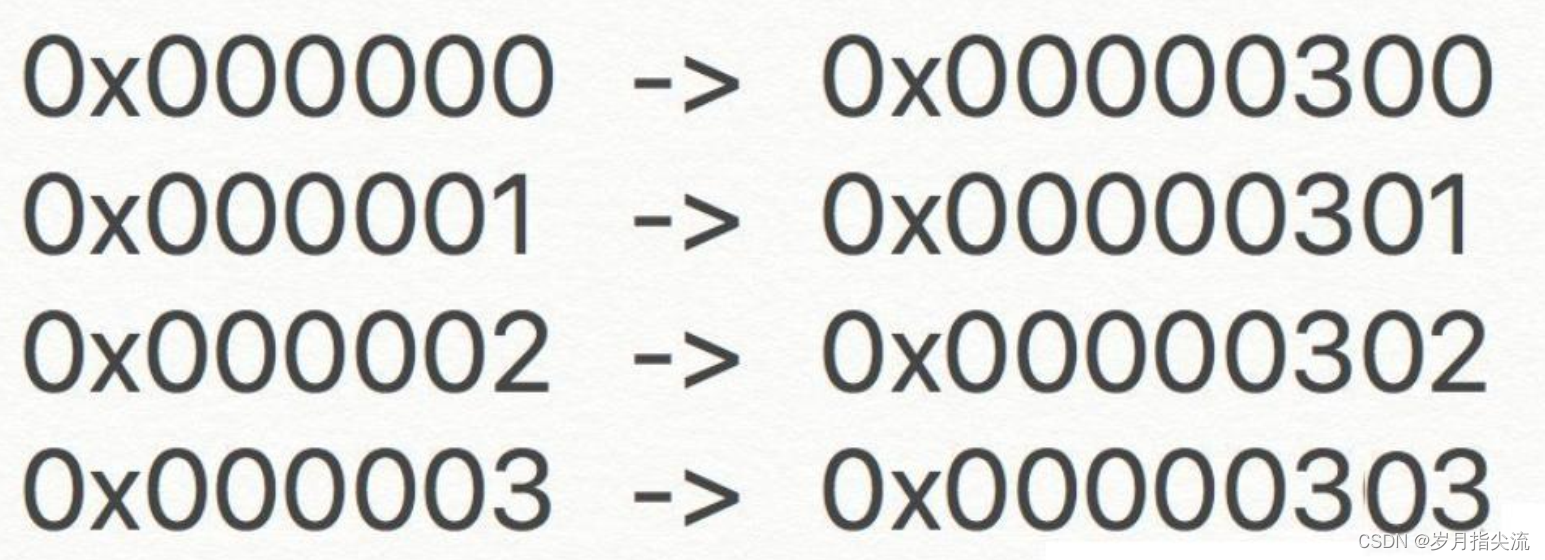
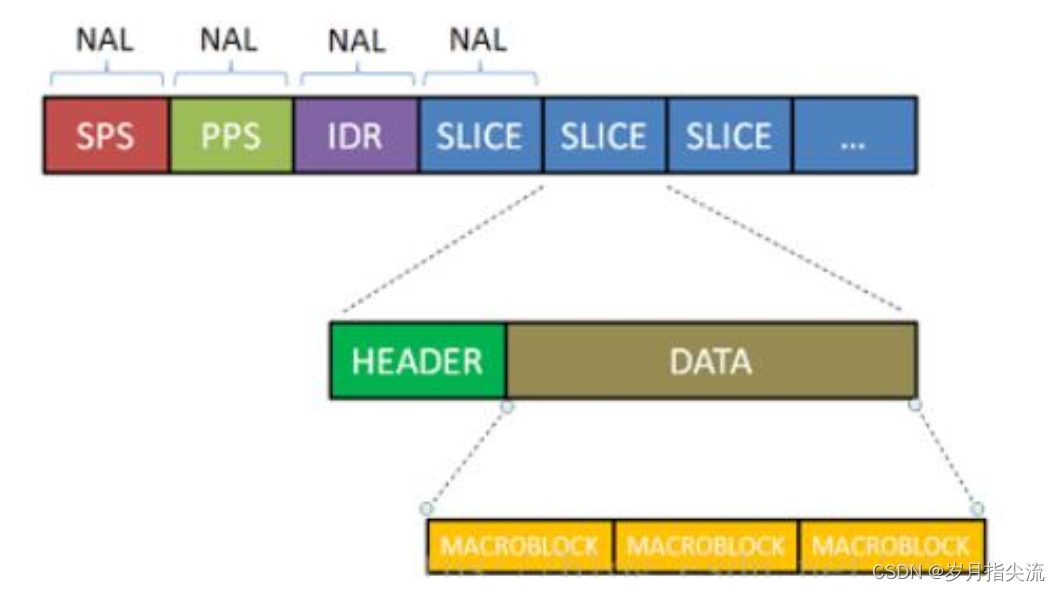
⑤、H264 码流结构
在具体讲述 NAL 单元前,十分有必要先了解一下 H264 的码流结构;在经过编码后的 H264 的码流如下图所示,从图中我们需要得到一个概念,H264 码流是由一个个的 NAL 单元组成,其中 SPS、PPS、IDR 和 SLICE 是 NAL 单元某一类型的数据。
⑥、H264 的 NAL 单元
<1>、H264 的 NAL 结构
在实际的网络数据传输过程中 H264 的数据结构是以 NALU(NAL 单元)进行传输的,传输数据结构组成为 [NALU Header]+[RBSP],如下图所示:

VCL 层编码后的视频帧数据,帧有可能是 I/B/P 帧,这些帧也可能是属于不同的序列之中,同一序列也还有相应的序列参数集与图片参数集;想要完成准确无误视频的解码,除了需要 VCL 层编码出来的视频帧数据,同时还需要传输 序列参数集和 图像参数集等等。
上面知道 NAL 单元是作为实际视频数据传输的基本单元,NALU 头是用来标识后面 RBSP 是什么类型的数据,同时记录 RBSP 数据是否会被其他帧参考以及网络传输是否有错误。
<2>、NAL 头
NAL 单元的头部是由 forbidden_bit(1bit),nal_reference_bit(2bits)(优先级),nal_unit_type(5bits)(类型)三个部分组成的, 组成如下图所示:
- F(forbiden):禁止位,占用 NAL 头的第一个位,当禁止位值为 1 时表示语法错误
- NRl:参考级别,占用 NAL 头的第二到第三个位;值越大, 该 NAL 越重要
- Type:Nal 单元数据类型,也就是标识该 NAL 单元的数据类型是哪种,占用 NAL 头的第四到第 8 个位

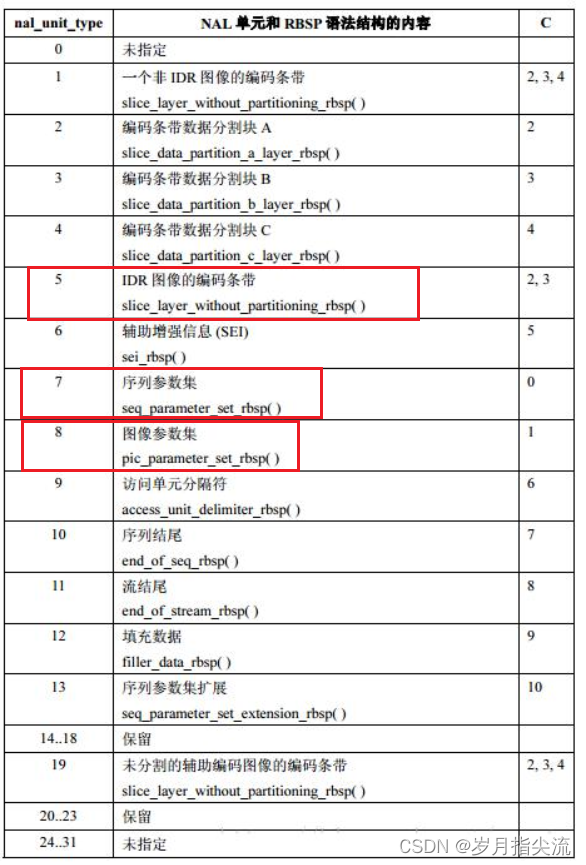
<3>、NAL 单元数据类型
NAL 类型主要就是下面图中这些类型每个类型都有特殊的作用;
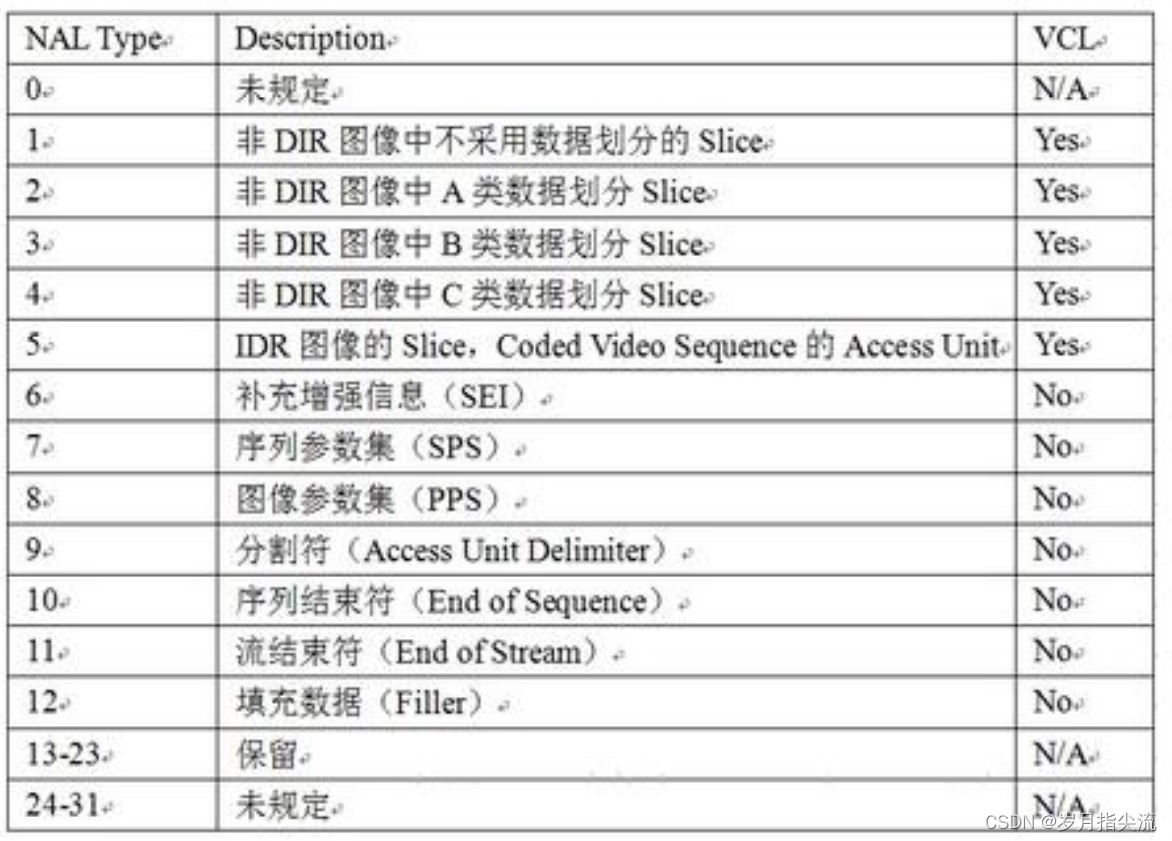
在具体介绍 NAL 数据类型前, 有必要知道 NAL 分为 VCL 和非 VCL 的 NAL 单元。
而另外一个需要了解的概念就是参数集(Parameter sets) ,参数集是携带解码参数的 NAL 单元,参数集对于正确解码是非常重要的,在一个有损耗的传输场景中,传输过程中比特列或包可能丢失或损坏,在这种网络环境下,参数集可以通过高质量的服务来发送,比如向前纠错机制或优先级机制。
-
非 VCL 的 NAL 数据类型:
- SPS(序列参数集):SPS 对如标识符、帧数以及参考帧数目、解码图像尺寸和帧场模式等解码参数进行标识记录。
- PPS(图像参数集):PPS 对如熵编码类型、有效参考图像的数目和初始化等解码参数进行标志记录。
- SEI(补充增强信息):这部分参数可作为 H264 的比特流数据而被传输,每一个 SEI 信息被封装成一个 NAL 单元。SEI 对于解码器来说可能是有用的,但是对于基本的解码过程来说,并不是必须的。
-
VCL 的 NAL 数据类型:
- 头信息块,包括宏块类型,量化参数,运动矢量。这些信息是最重要的,因为离开他们,被的数据块种的码元都无法使用。 该数据分块称为 A 类数据分块。
- 帧内编码信息数据块,称为 B 类数据分块。它包含帧内编码宏块类型,帧内编码系数。对应的 slice 来说,B 类数据分块的可用性依赖于 A 类数据分块。和帧间编码信息数据块不通的是,帧内编码信息能防止进一步的偏差,因此比帧间编码信息更重要。
- 帧间编码信息数据块,称为 C 类数据分块。它包含帧间编码宏块类型,帧间编码系数。它通常是 slice 种最大的一部分。帧间编码信息数据块是不重要的一部分。它所包含的信息并不提供编解码器之间的同步。C 类数据分块的可用性也依赖于 A 类数据分块,但于 B类数据分块无关。
以上三种数据块每种分割被单独的存放在一个 NAL 单元中,因此可以被单独传输
<4>、NAL Unit
一个 H264 的帧至少由一个切片组成,不能没有切片,可以是一个到多个。
在网络传输的时候一个 H264 帧可能需要切开去传,一个一次传不完,这就按照切片来切。
每一个切片组成一个 NAL Unit。
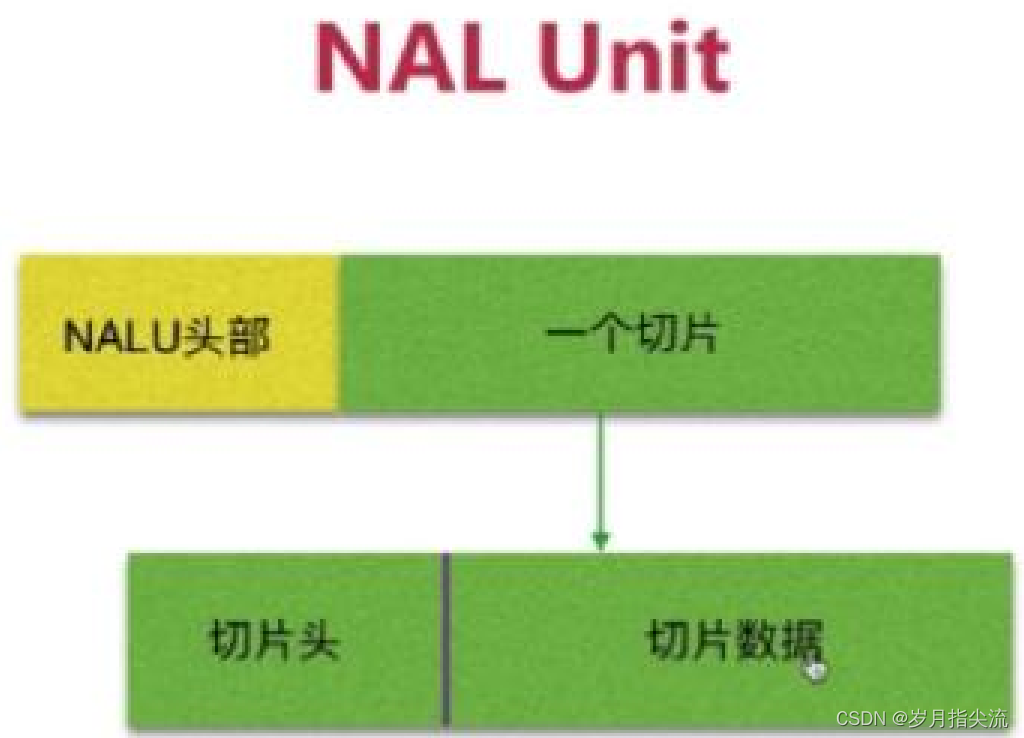
<5>、切片与宏块的关系
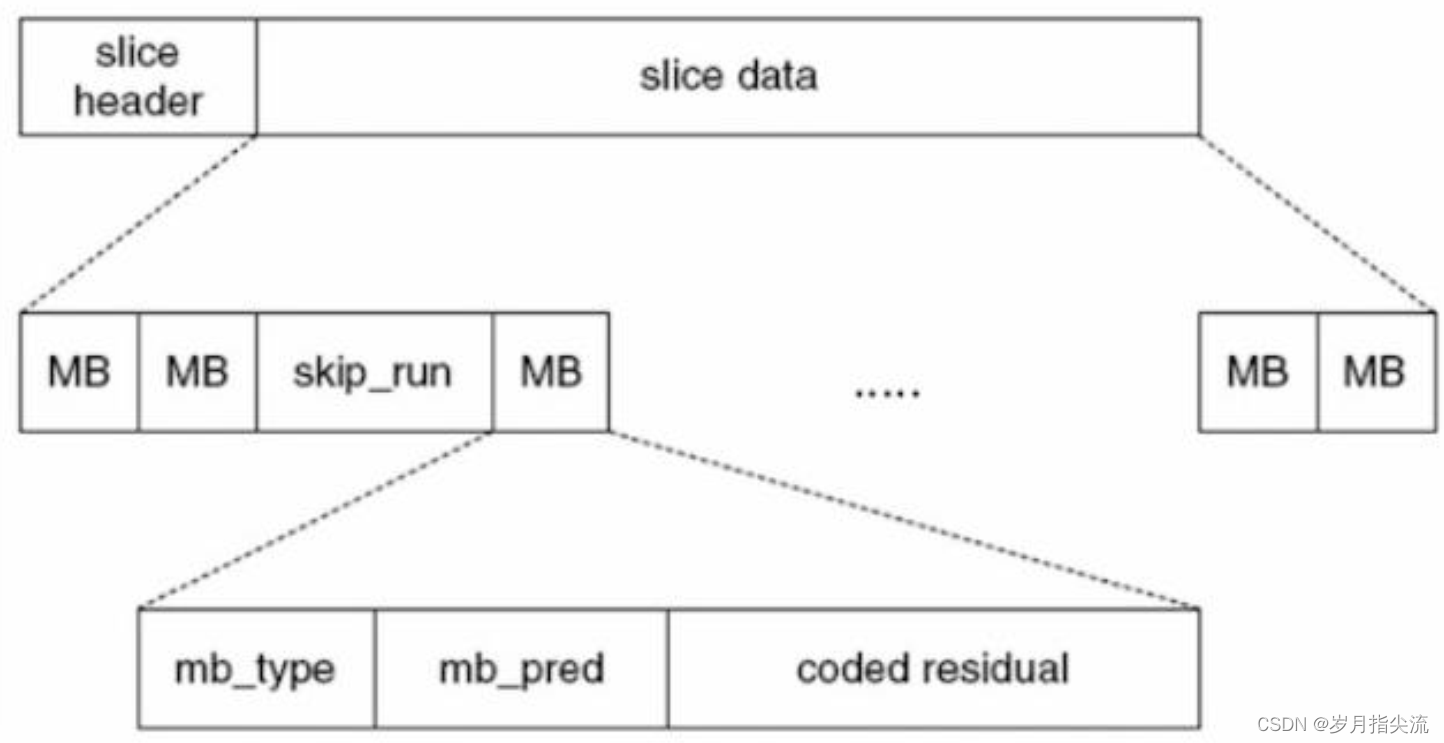
在切片数据中,包含若干个宏块。
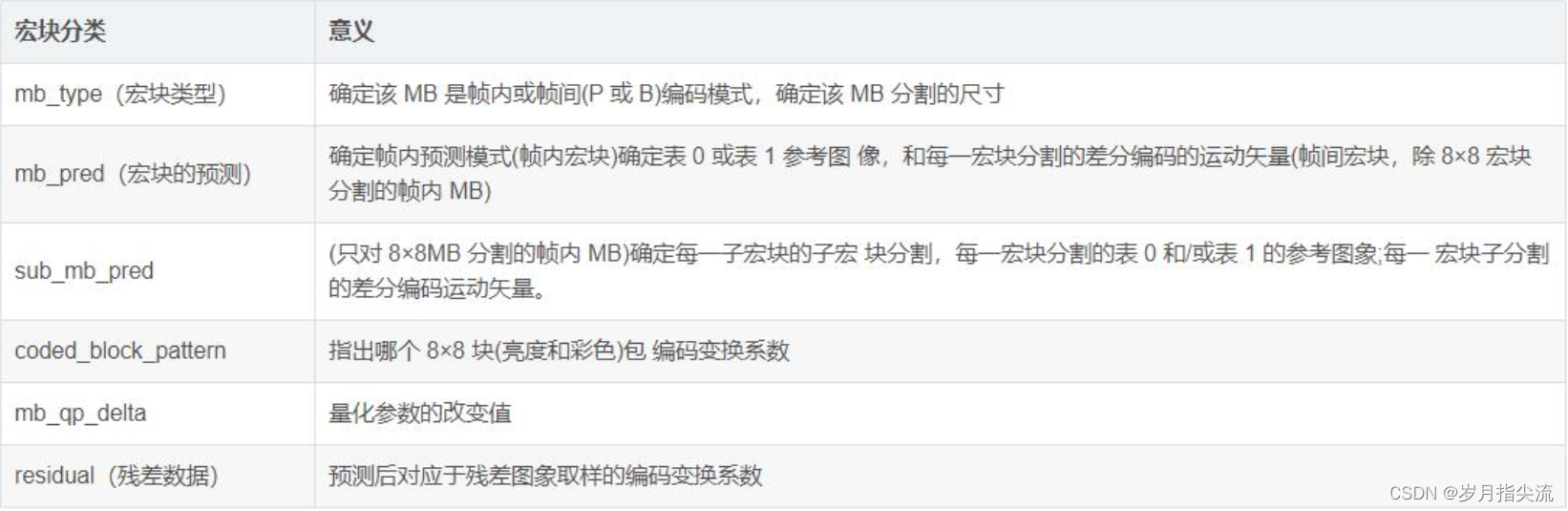
在一个宏块中,又包含了宏块类型、宏块预测、残差数据。
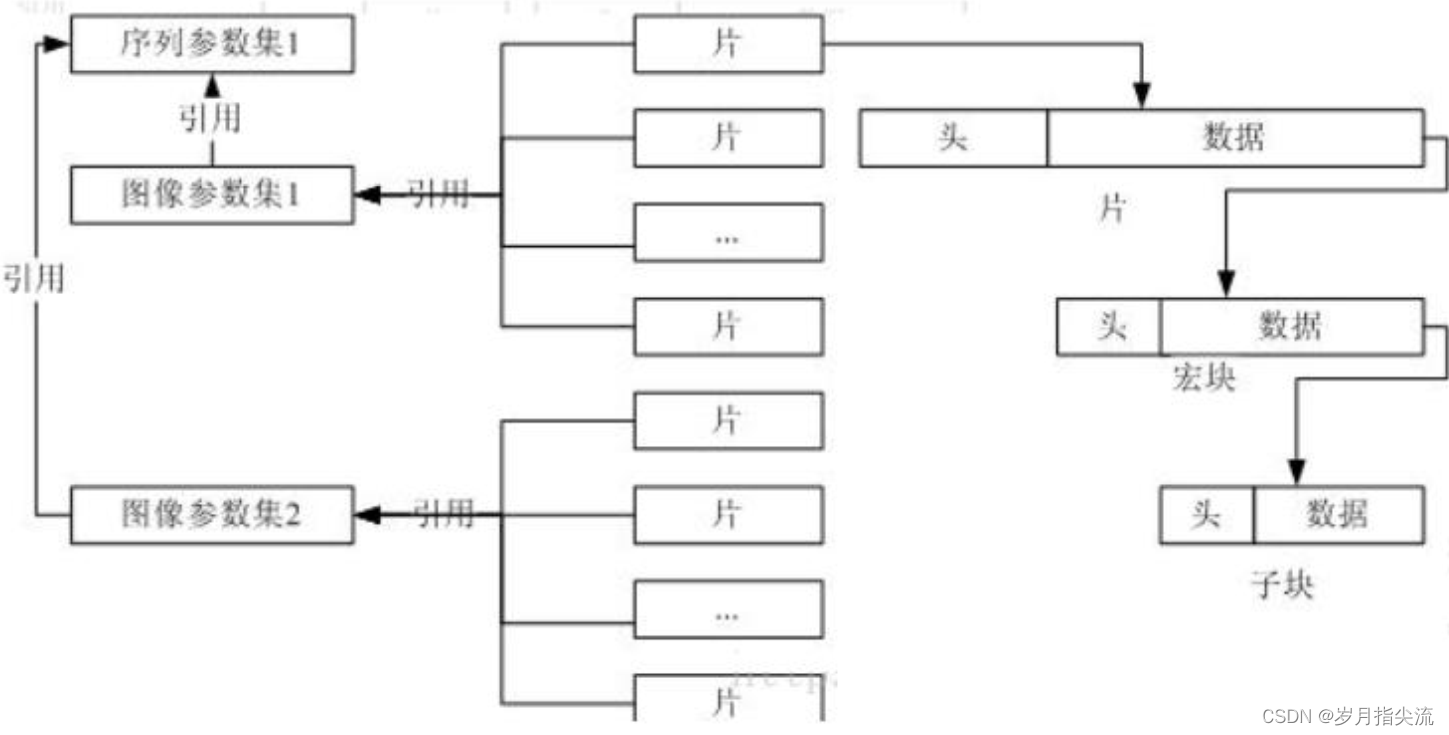
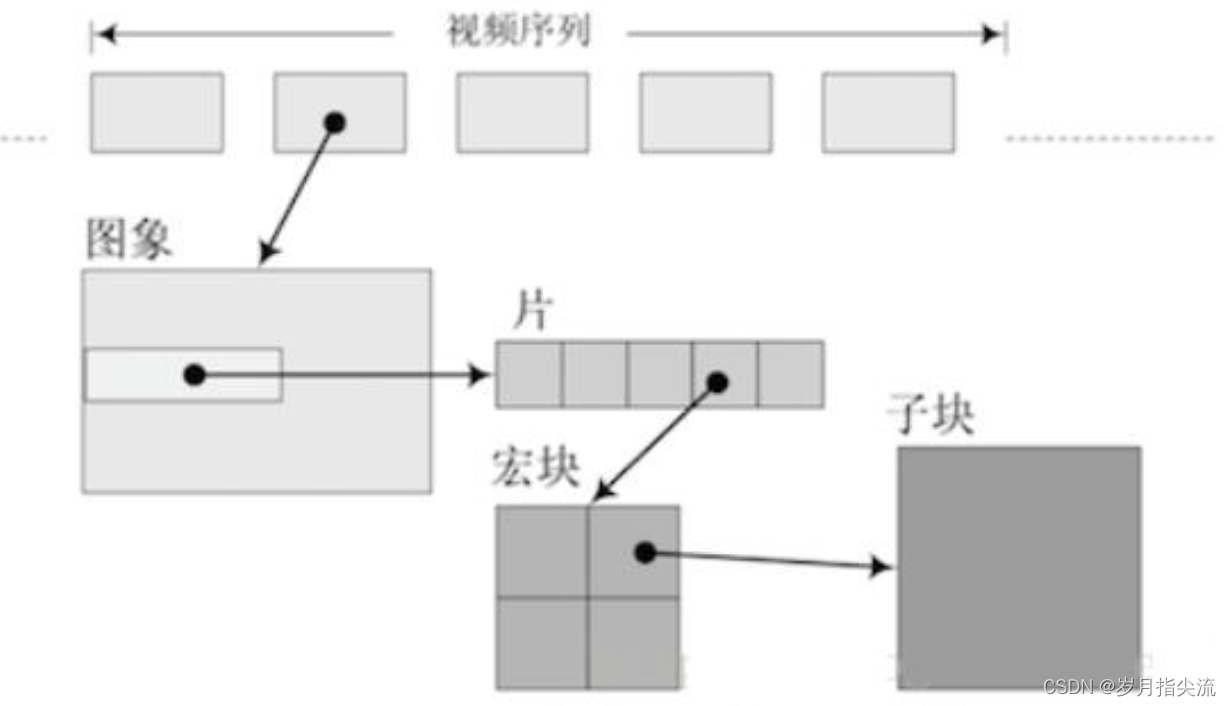
<6>、H264 的 NAL 单元与片、宏之间的联系
- 1 帧(一幅图像)= 1~N 个片(slice) //也可以说 1 到多个片为一个片组
- 1 个片 = 1~N 个宏块(Marcroblock)
- 1 个宏块 = 16X16 的 YUV 数据(原始视频采集数据)
从数据层次角度来说,一幅原始的图片可以算作广义上的一帧,帧包含片组和片,片组由片来组成,片由宏块来组成,每个宏块可以是 44、88、16*16 像素规模的大小,它们之间的联系如图所示。
同时有几点需要说明一下,这样能便于理解 NAL 单元:
- 如果不采用 FMO(灵活宏块排序)机制,则一幅图像只有一个片组;
- 如果不使用多个片,则一个片组只有一个片;
- 如果不采用 DP(数据分割)机制, 则一个片就是一个 NALU,一个 NALU 也就是一个片。否则,一个片的组成需要由 三个 NALU 组成,也就是上面说到的 A、 B、 C 类数据块
这时候在看下面这幅码流数据分层, 下图就比较能理解整体的码流结构组成了
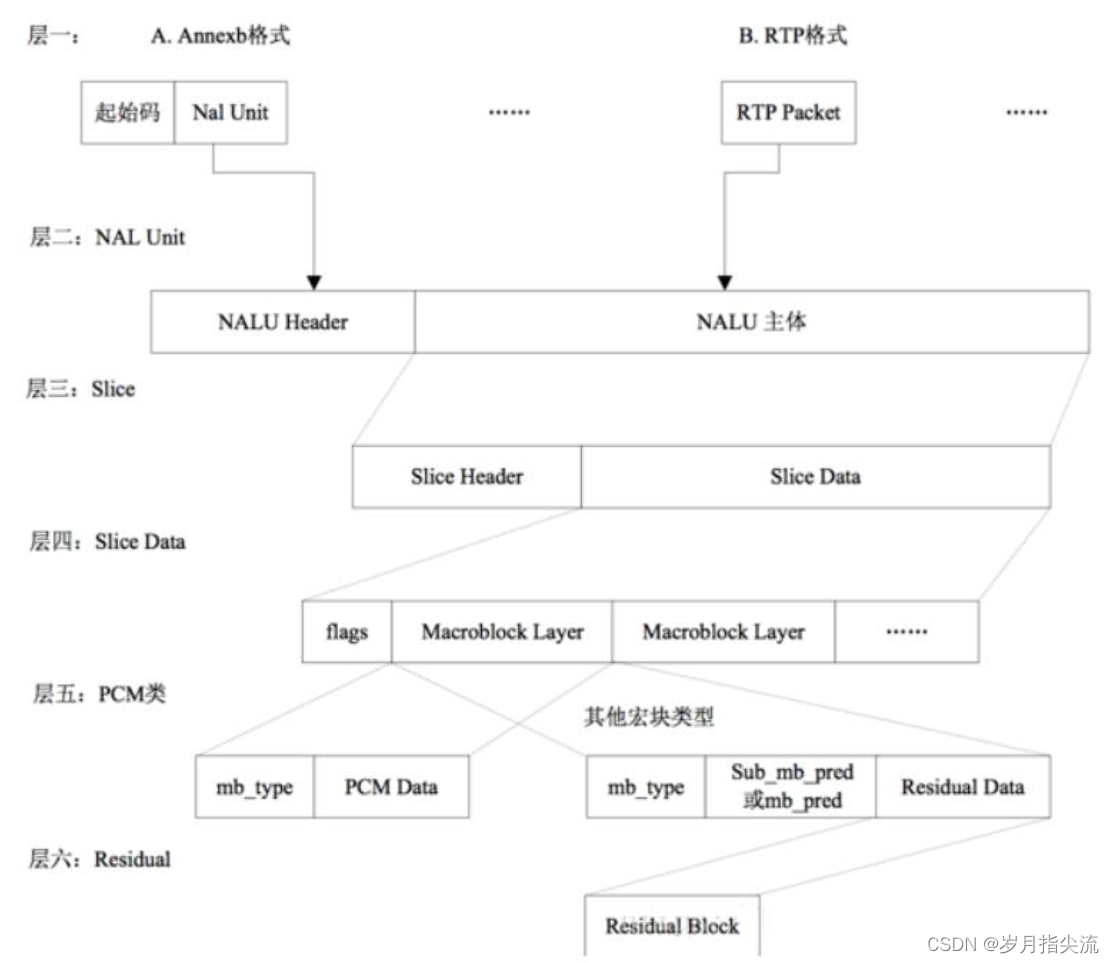
如我们所见,每个分片也包含着头和数据两部分;分片头中包含着分片类型、分片中的宏块类型、分片帧的数量以及对应的帧的设置和参数等信息;而分片数据中则是宏块,这里就是我们要找的存储像素数据的地方,宏块是视频信息的主要承载者,因为它包含着每一个像素的亮度和色度信息。
视频解码最主要的工作则是提供高效的方式从码流中获得宏块中的像素阵列。
宏块数据的组成如下图所示:
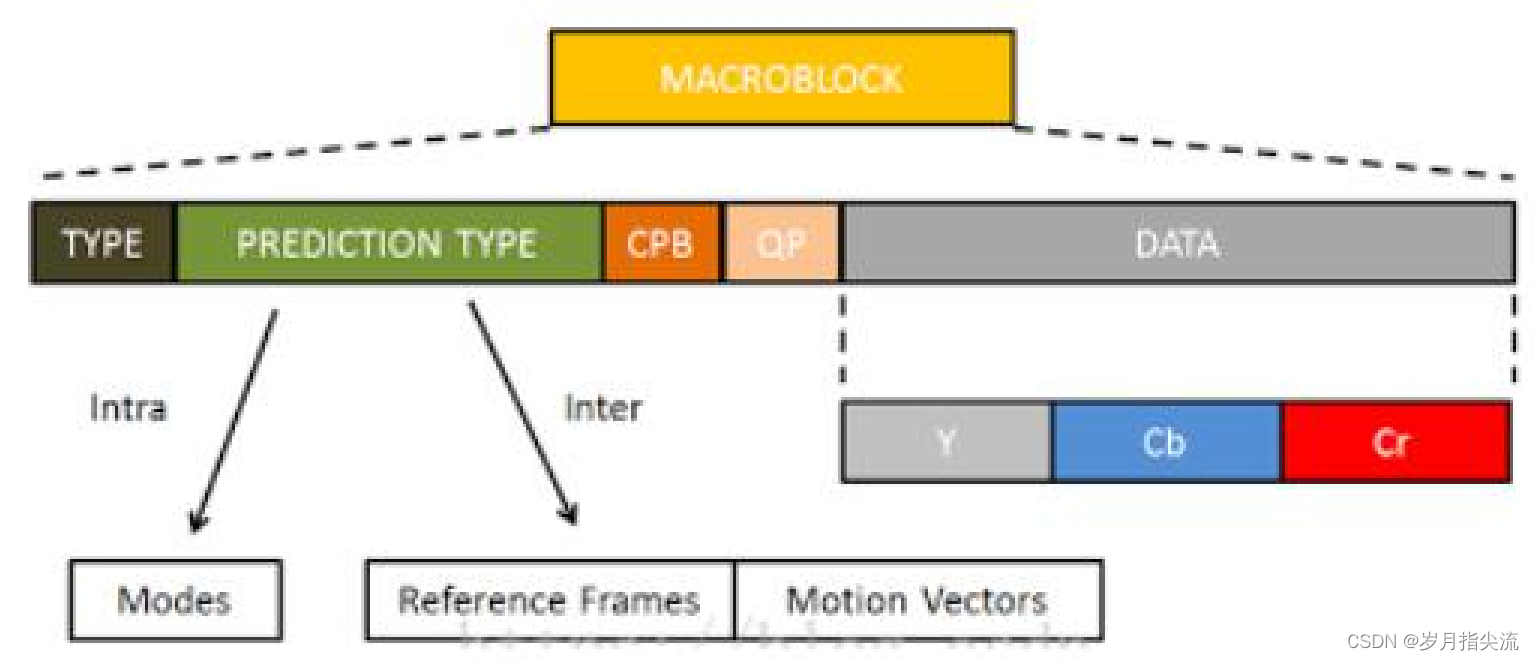
从上图中,可以看到,宏块中包含了宏块类型、预测类型、Coded Block Pattern、Quantization Parameter、像素的亮度和色度数据集等等信息。
需要注意的几点:
- H.264/AVC 标准对送到解码器的 NAL 单元顺序是有严格要求的,如果 NAL 单元的顺序是混乱的,必须将其重新依照规范组织后送入解码器,否则解码器不能够正确解码。
- 序列参数集(sps)NAL 单元必须在传送所有以此参数集为参考的其他 NAL 单元之前传送,不过允许这些 NAL 单元中间出现重复的序列参数集 NAL 单元。所谓重复的详细解释为:序列参数集 NAL 单元都有其专门的标识,如果两个序列参数集 NAL 单元的标识相同,就可以认为后一个只不过是前一个的拷贝,而非新的序列参数集。
- 图像参数集(pps)NAL 单元 必须在所有以此参数集为参考的其他 NAL 单元之前传送,不过允许这些 NAL 单元中间出现重复的图像参数集 NAL 单元,这一点与上述的序列参数集NAL 单元是相同
三、AAC 编码基础
AAC 是高级音频编码(Advanced Audio Coding)的缩写,AAC 是新一代的音频有损压缩技术
1、AAC 编码的特点
- AAC 是一种高压缩比的音频压缩算法,但它的压缩比要远超过较老的音频压缩算法,如 AC-3、MP3 等。并且其质量可以同未压缩的 CD 音质相媲美。
- 同其他类似的音频编码算法一样,AAC 也是采用了变换编码算法,但 AAC 使用了分辨率更高的滤波器组,因此它可以达到更高的压缩比。
- AAC 使用了临时噪声重整、后向自适应线性预测、联合立体声技术和量化哈夫曼编码等最新技术,这些新技术的使用都使压缩比得到进一步的提高。
- AAC 支持更多种采样率和比特率、支持 1 个到 48 个音轨、支持多达 15 个低频音轨、具有多种语言的兼容能力、还有多达 15 个内嵌数据流。
- AAC 支持更宽的声音频率范围,最高可达到 96kHz,最低可达 8KHz,远宽于 MP3 的 16KHz-48kHz 的范围。
- 不同于 MP3 及 WMA,AAC 几乎不损失声音频率中的甚高、甚低频率成分,并且比 WMA 在频谱结构上更接近于原始音频,因而声音的保真度更好。专业评测中表明,AAC 比 WMA 声音更清晰,而且更接近原音
- AAC 采用优化的算法达到了更高的解码效率,解码时只需较少的处理能力。
2、AAC 音频文件格式
①、ACC 音频文件格式类型
AAC 的音频文件格式有:ADIF,ADTS
- ADIF:Audio Data Interchange Format 音频数据交换格式。这种格式的特征是可以确定的找到这个音频数据的开始,不需进行在音频数据流中间开始的解码,即它的解码必须在明确定义的开始处进行。 故这种格式常用在磁盘文件中。
- ADTS:Audio Data Transport Stream 音频数据传输流。这种格式的特征是它是一个有同步字的比特流,解码可以在这个流中任何位置开始。它的特征类似于 mp3 数据流格式。
简单说,ADTS 可以在任意帧解码,也就是说它每一帧都有头信息。ADIF 只有一个统一的头,所以必须得到所有的数据后解码。这两种的 header 的格式也是不同的,一般编码后的和抽取出的都是 ADTS 格式的音频流。
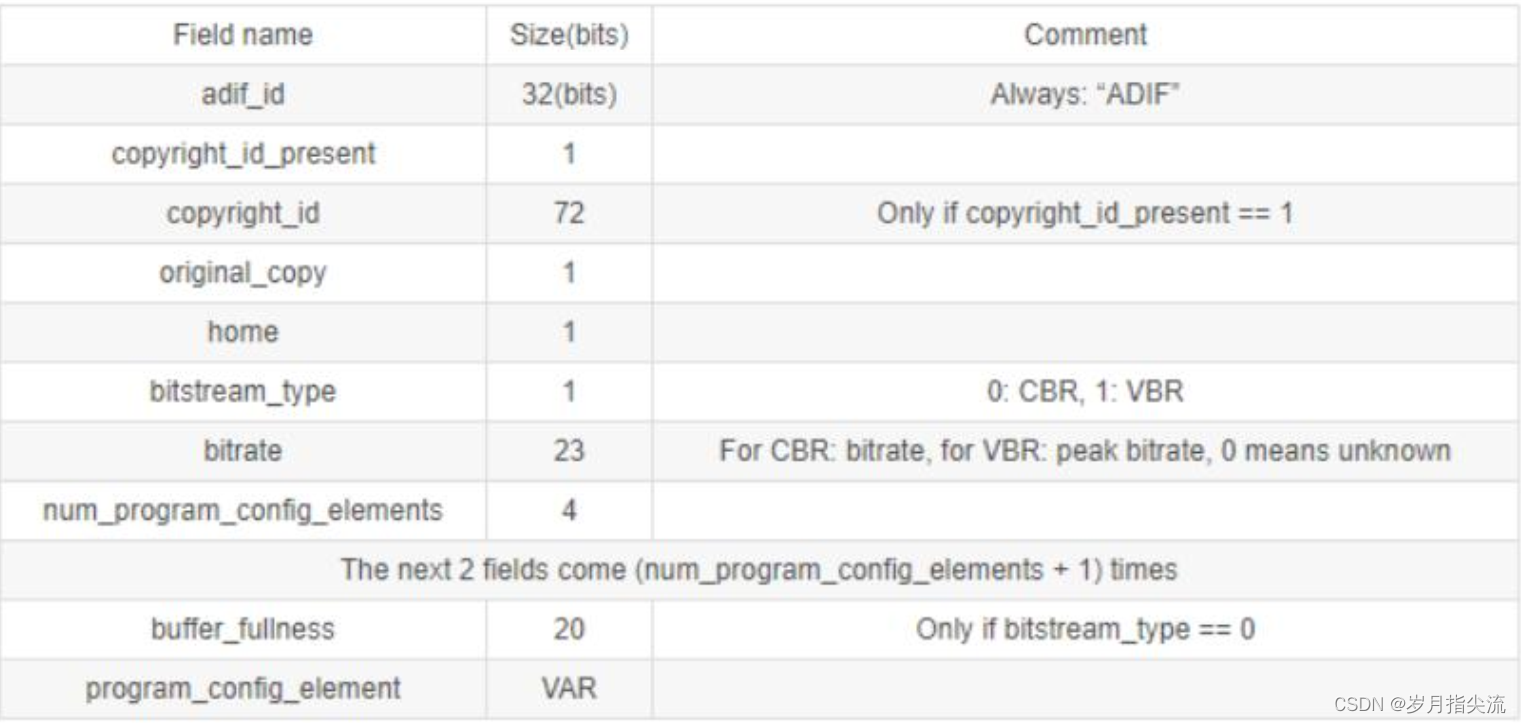
AAC 的 ADIF 文件格式如下图:

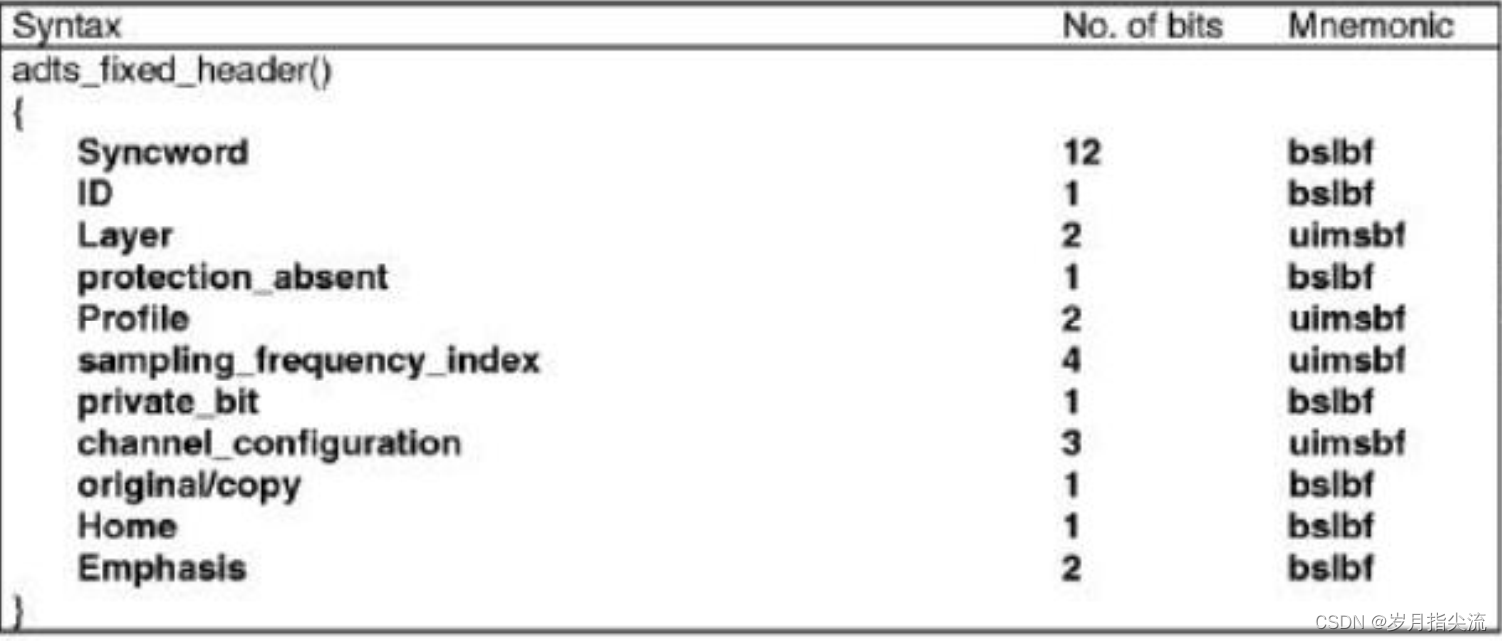
AAC 的 ADTS 文件中一帧的格式如下图:

②、ADIF 的 Header 结构
ADIF 的头信息如下图:

ADIF 头信息位于 AAC 文件的起始处, 接下来就是连续的 Raw Data Blocks。
组成 ADIF 头信息的各个域如下所示:
③、ADTS 的 Header 结构
ADTS 的固定头信息:
ADTS 的可变头信息:

- 帧同步目的在于找出帧头在比特流中的位置,13818-7 规定,AAC ADTS 格式的帧头同步字为 12 比特的“1111 1111 1111”。
- ADTS 的头信息为两部分组成,其一为固定头信息,紧接着是可变头信息。固定头信息中的数据每一帧都相同,而可变头信息则在帧与帧之间可变。
④、AAC 元素信息
在 AAC 中,原始数据块的组成可能有六种不同的元素:
- SCE: Single Channel Element 单通道元素。单通道元素基本上只由一个 ICS 组成。一个原始数据块最可能由 16 个 SCE 组成。
- CPE: Channel Pair Element 双通道元素,由两个可能共享边信息的 ICS 和一些联合立体声编码信息组成。一个原始数据块最多可能由 16 个 SCE 组成。
- CCE: Coupling Channel Element 藕合通道元素。代表一个块的多通道联合立体声信息或者多语种程序的对话信息。
- LFE: Low Frequency Element 低频元素。包含了一个加强低采样频率的通道。
- DSE: Data Stream Element 数据流元素,包含了一些并不属于音频的附加信息。
- PCE: Program Config Element 程序配置元素。包含了声道的配置信息。它可能出现在 ADIF 头部信息中。
- FIL: Fill Element 填充元素。包含了一些扩展信息。如 SBR,动态范围控制信息等。
⑤、AAC 文件处理流程
- (1)判断文件格式, 确定为 ADIF 或 ADTS
- (2)若为 ADIF,解 ADIF 头信息,跳至第 6 步
- (3)若为 ADTS,寻找同步头
- (4)解 ADTS 帧头信息
- (5)若有错误检测,进行错误检测
- (6)解块信息
- (7)解元素信息
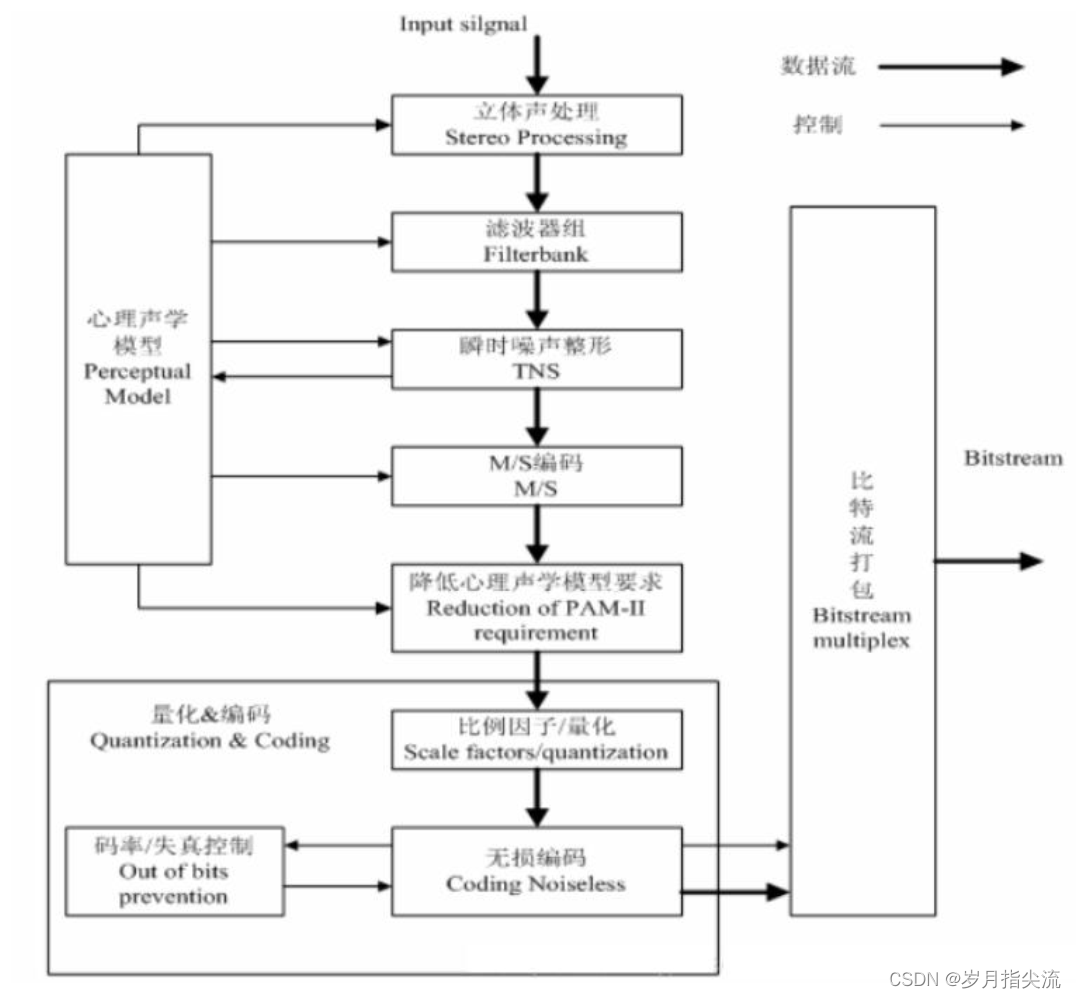
3、编码算法处理流程
首先对输入的 PCM 信号分段,每帧每声道 1024 个样本,采用 1/2 重叠,组合得到 2048 个样本。
加窗后,进行离散余弦变化(MDCT),输出 1024 个频谱分量,依据不同采样率和变换块类型划分成 10 个不同带宽的比例因子频带。其中变化块类型由 心理声学模型 计算分析得到,该模型还将输出 信掩比,用于后续模块的处理。
AAC 还使用了一种新的称为时域噪声整形的技术,简称为 TNS。TNS 的作用机理在于利用了时域和频域信号的对偶性
量化和编码使用一种两层嵌套循环算法,以权衡码率和失真之间的矛盾。
最后,进行比特流封装,得到压缩后的码流。
我的qq:2442391036,欢迎交流!