版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_34533544/article/details/78113146
BP神经网络以及在手写数字分类中python代码的详细注释
1、写在前面
传统的bp神经网络分为3层,输入层,隐含层以及输出层,其中隐含层可以分为多层,但最多不超过两层。每层的神经元个数具体问题具体设置,如本文手写数字图片,它是将图片28*28转换为784*1向量,则输入层就是一个784维的向量,则输入层神经元个数就为784,而输出层,本文是将数字0-9转换成一个10维的向量,比如数字9转换为输出层向量就是0000000001,即在第10位标注1,一种类似二进制的向量,那么输出层就定为了10层,而隐含层的个数,可如下根据公式:

在此定义为30个神经元,即将bp神经网络各层神经元个数确定了,那么剩下的步骤就是如何建立这个三层的神经网络模型。
2、建立BP神经网络
书中对输入层、隐含层、输出层的每一层的存储向量怎么得到的进行了介绍,输入层就是要输入的Xi,每一维对于的数据,相应的就有对于的权重Uij,而这只是计算得到隐藏层一个神经元的值,所有就有n个隐藏层神经元对应一个Uij矩阵,这个矩阵每一列就是所有输入层向量对应的权重。
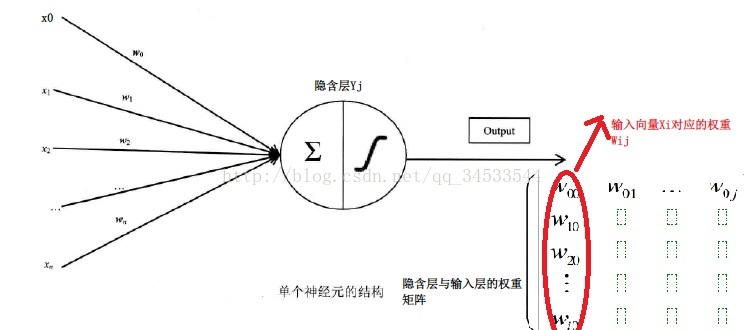
同理隐含层与输出层的权重Wjk也是由矩阵保存的,具体在代码中的存储情况将在代码解释部分注释。即这里矩阵内权重的更新在代码中是采取向量计算方式计算的。
根据梯度下降的思想,将输入层的向量输入进过层层权重相乘后得到的输出层的结果要与真实的标签误差要很小,即引入了全局误差函数E,这与二维向量利用梯度下降思想是一样的,即是网络输出层结果要与真实结果差距最小,对输入层与隐含层权重Uij以及隐含层与输出层的权重Wjk最优化问题,在此本人给出手写稿的推导过程,如下:


注意:草稿中双星标注的那段话,它结束了在BP网络神经随机梯度算法对一个小样本计算得到的权重的处理方法,以及最终的权重更新计算方法。
为了对推导公式(10),(11)计算过程理解的方便,在此举[2,3,2]的bp网络进行解释,如下:

3、BP网络的python实现(手写数据数据集的训练以及分类)
第一步:输入层的数据输入,数据连接,密码:lwjk
load_data_wrapper这个函数是将训练数据集reshape重塑成[array([784*1],[10*1]),.........]的结构,而测试集与验证集与训练集类似,只是将10*1矩阵表示的标签结果变成了这个图片的数据,[array([784*1],[数子9]),.........]#### Libraries
# Standard library
import cPickle
import gzip
# Third-party libraries
import numpy as np
def load_data():
f = gzip.open('./data/mnist.pkl.gz', 'rb')
training_data, validation_data, test_data = cPickle.load(f)
f.close()
return (training_data, validation_data, test_data)
def load_data_wrapper():
tr_d, va_d, te_d = load_data()
training_inputs = [np.reshape(x, (784, 1)) for x in tr_d[0]]
training_results = [vectorized_result(y) for y in tr_d[1]]
training_data = zip(training_inputs, training_results)
validation_inputs = [np.reshape(x, (784, 1)) for x in va_d[0]]
validation_data = zip(validation_inputs, va_d[1])
test_inputs = [np.reshape(x, (784, 1)) for x in te_d[0]]
test_data = zip(test_inputs, te_d[1])
return (training_data, validation_data, test_data)
def vectorized_result(j):
e = np.zeros((10, 1))
e[j] = 1.0
return e#!/usr/bin/env python
# -*- coding: UTF-8 -*-
#### Libraries
# Standard library
import random
# Third-party libraries
import numpy as np
class Network(object):
def __init__(self, sizes):
"""
:param sizes: list类型,储存每层神经网络的神经元数目
譬如说:sizes = [2, 3, 2] 表示输入层有两个神经元、
隐藏层有3个神经元以及输出层有2个神经元
"""
# 有几层神经网络
self.num_layers = len(sizes)
self.sizes = sizes
# 除去输入层,随机产生每层中 y 个神经元的 biase 值(0 - 1)
self.biases = [np.random.randn(y, 1) for y in sizes[1:]]
# 随机产生每条连接线的 weight 值(0 - 1)
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])]
def feedforward(self, a):
"""
前向传输计算每个神经元的值
:param a: 输入值
:return: 计算后每个神经元的值
"""
for b, w in zip(self.biases, self.weights):
# 加权求和以及加上 biase
a = sigmoid(np.dot(w, a) + b)
return a
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""
随机梯度下降
:param training_data: 输入的训练集
:param epochs: 迭代次数
:param mini_batch_size: 小样本数量
:param eta: 学习率
:param test_data: 测试数据集
"""
if test_data: n_test = len(test_data)
n = len(training_data)
for j in xrange(epochs):
# 搅乱训练集,让其排序顺序发生变化
random.shuffle(training_data)#那么mini_batches就是随机抽取了
# 按照小样本数量划分训练集
mini_batches = [
training_data[k:k+mini_batch_size]
for k in xrange(0, n, mini_batch_size)]
for mini_batch in mini_batches:
# 根据每个小样本来更新 w 和 b,代码在下一段
self.update_mini_batch(mini_batch, eta)
# 输出测试每轮结束后,神经网络的准确度
if test_data:
print "Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test)
else:
print "Epoch {0} complete".format(j)
def update_mini_batch(self, mini_batch, eta):
"""
更新 w 和 b 的值
:param mini_batch: 一部分的样本
:param eta: 学习率
"""
# 根据 biases 和 weights 的行列数创建对应的全部元素值为 0 的空矩阵
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
# 根据样本中的每一个输入 x 的其输出 y,计算 w 和 b 的偏导数
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
# 累加储存偏导值 delta_nabla_b 和 delta_nabla_w
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
# 更新根据累加的偏导值更新 w 和 b,这里因为用了小样本,
# 所以 eta 要除于小样本的长度
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
def backprop(self, x, y):
"""
:param x:
:param y:
:return:
"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# 前向传输
activation = x
# 储存每层的神经元的值的矩阵,下面循环会 append 每层的神经元的值
activations = [x]
# 储存每个未经过 sigmoid 计算的神经元的值
zs = []
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b#隐含层的输入
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# 求 δ 的值
# activations[-1]输出层结果
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])#公式(Dk-Ok)Ok(1-Ok)
nabla_b[-1] = delta#用于求隐含层与输出层之间的偏差b
# 乘于前一层的输出值
nabla_w[-1] = np.dot(delta, activations[-2].transpose())#输出层的权重Wjk
for l in xrange(2, self.num_layers):#第二层
# 从倒数第 **l** 层开始更新,**-l** 是 python 中特有的语法表示从倒数第 l 层开始计算
# 下面这里利用 **l+1** 层的 δ 值来计算 **l** 的 δ 值
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
def evaluate(self, test_data):
# 获得预测结果
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
# 返回正确识别的个数
return sum(int(x == y) for (x, y) in test_results)
def cost_derivative(self, output_activations, y):
"""
二次损失函数
:param output_activations:
:param y:
:return:
"""
return (output_activations-y)
#### Miscellaneous functions
def sigmoid(z):
"""
求 sigmoid 函数的值
:param z:
:return:
"""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""
求 sigmoid 函数的导数
:param z:
:return:
"""
return sigmoid(z)*(1-sigmoid(z))第三步:主函数对测试进行测试
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
import mnist_loader
import network
print "开始训练,较耗时,请稍等。。。"
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
# 784 个输入神经元,一层隐藏层,包含 30 个神经元,输出层包含 10 个神经元
net = network.Network([784, 30, 10])
net.SGD(training_data, 30, 10, 3.0, test_data = test_data)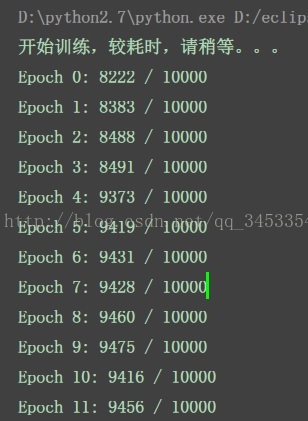
4、写在后面
bp神经网络是采取随机梯度下降算法的思想,对各个权重求其微分值,同时重点在于总体样本的权重微分是累加的,用于最终的权重更新。