BP(back propagation)神经网络是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络,是目前应用最广泛的神经网络。
在一般的BP神经网络中,单个样本有m个输入和n个输出,在输入层和输出层之间还有若干个隐藏层h,实际上 1989年时就已经有人证明了一个万能逼近定理 :
在任何闭区间的连续函数都可以用一个隐藏层的BP神经网络进行任意精度的逼近。
所以说一个三层的神经网络就可以实现一个任意从m维到n维的一个映射,这三层分别是 输入层、隐藏层、输出层 。
一般来说,在BP神经网络中,输入层和输出层的节点数目都是固定的,关键的就是在于隐藏层数目的选择,隐藏层数目的选择决定了神经网络工作的效果。
这里有一个选择隐藏层数目的经验公式: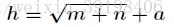
- h 隐藏层
- m 输入层
- n 输出层
- a 调节常数数(一般介于1~10之间,如果数据多的话我们可以设a稍微大一点,而数据不是太多的时候就设置的小一点防止过拟合。)
BP神经网络的工作原理分为两个过程 :
1. 工作信号正向传递子过程
2. 误差信号逆向传递过程
标准BP神经网络的缺陷:
(1)容易形成局部极小值而得不到全局最优值。
BP神经网络中极小值比较多,所以很容易陷入局部极小值,这就要求对初始权值和阀值有要求,要使得初始权值和阀值随机性足够好,可以多次随机来实现。
(2)训练次数多使得学习效率低,收敛速度慢。
(3)隐含层的选取缺乏理论的指导。
(4)训练时学习新样本有遗忘旧样本的趋势。
通常BP神经网络在训练之前会对数据归一化处理,即将数据
映射到更小的区间内,比如[0,1]或[-1,1]。
下面是基于tensorflow实现的BP神经网络的例子:
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
mnist = input_data.read_data_sets('./data/', one_hot = True)
num_classes = 10 # 输出大小
input_size = 784 # 输入大小
hidden_units_size = 30 # 隐藏层节点数量
batch_size = 100
training_iterations = 10000
X = tf.placeholder(tf.float32, shape = [None, input_size])
Y = tf.placeholder(tf.float32, shape = [None, num_classes])
W1 = tf.Variable(tf.random_normal ([input_size, hidden_units_size], stddev = 0.1))
B1 = tf.Variable(tf.constant (0.1), [hidden_units_size])
W2 = tf.Variable(tf.random_normal ([hidden_units_size, num_classes], stddev = 0.1))
B2 = tf.Variable(tf.constant (0.1), [num_classes])
hidden_opt = tf.matmul(X, W1) + B1 # 输入层到隐藏层正向传播
hidden_opt = tf.nn.relu(hidden_opt) # 激活函数,用于计算节点输出值
final_opt = tf.matmul(hidden_opt, W2) + B2 # 隐藏层到输出层正向传播
# 对输出层计算交叉熵损失
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=Y, logits=final_opt))
# 梯度下降算法,这里使用了反向传播算法用于修改权重,减小损失
opt = tf.train.GradientDescentOptimizer(0.05).minimize(loss)
# 初始化变量
init = tf.global_variables_initializer()
# 计算准确率
correct_prediction =tf.equal (tf.argmax (Y, 1), tf.argmax(final_opt, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, 'float'))
sess = tf.Session ()
sess.run (init)
for i in range (training_iterations) :
batch = mnist.train.next_batch (batch_size)
batch_input = batch[0]
batch_labels = batch[1]
# 训练
training_loss = sess.run ([opt, loss], feed_dict = {X: batch_input, Y: batch_labels})
if i % 1000 == 0 :
train_accuracy = accuracy.eval (session = sess, feed_dict = {X: batch_input,Y: batch_labels})
print ("step : %d, training accuracy = %g " % (i, train_accuracy))目前,在人工神经网络的实际应用中,绝大部分的神经网络模型都采用BP网络及其变化形式。它也是前向网络的核心部分,体现了人工神经网络的精华。
BP网络主要用于以下四个方面。
1)函数逼近:用输入向量和相应的输出向量训练一个网络逼近一个函数。
2)模式识别:用一个待定的输出向量将它与输入向量联系起来。
3)分类:把输入向量所定义的合适方式进行分类。
4)数据压缩:减少输出向量维数以便于传输或存储。参考:https://blog.csdn.net/zhelong3205/article/details/78688476
参考:https://www.baidu.com/link?url=QtggY8ZFEMUGhqFBBn6g2ZrzuVYLJx6oXvais1_bBHolMtdgmMhar6EQL26oa7lfQwOYNugBBLyxHP9iAhI0qDvoNdYCtUysRnbvI6r4fIVxg0VL7yzpqeFrEYJlJJrS&wd=&eqid=9a8a614000082d7c000000065b8649d9