学习:“如果一个系统能够通过执行某个过程改进它的性能,这就是学习。”按照这一观点,统计学习就是计算机系统通过运用数据及统计方法提供系统性能的机器学习。
机器学习的对象是数据,它从数据出发,提取数据特征,抽象出数据模型,发现数据中的知识,又回到对数据的分析和预测中去。[机器学习关于数据的基本假设是:同类数据具有一定的统计规律性。由于它们具有统计规律性,所以可以用概率统计方法来处理。]
1. 何时使用机器学习?
根据机器学习的性质,我们可以得出:
- 存在“underlying pattern”需要我们学习,因为机器学习依靠的就是从数据中抽象模型。
- 没有programmable(easy)definition。这可以类比于:编程方法是问题的精确解、规则化的解;而机器学习是概率统计上的解。那么,可以用编程方式解决的问题,传统编程方式自然是首选。
- 必须有data,因为机器学习的对象就是data。
2. 机器学习问题的形式化描述
2.1 机器学习形式化描述图
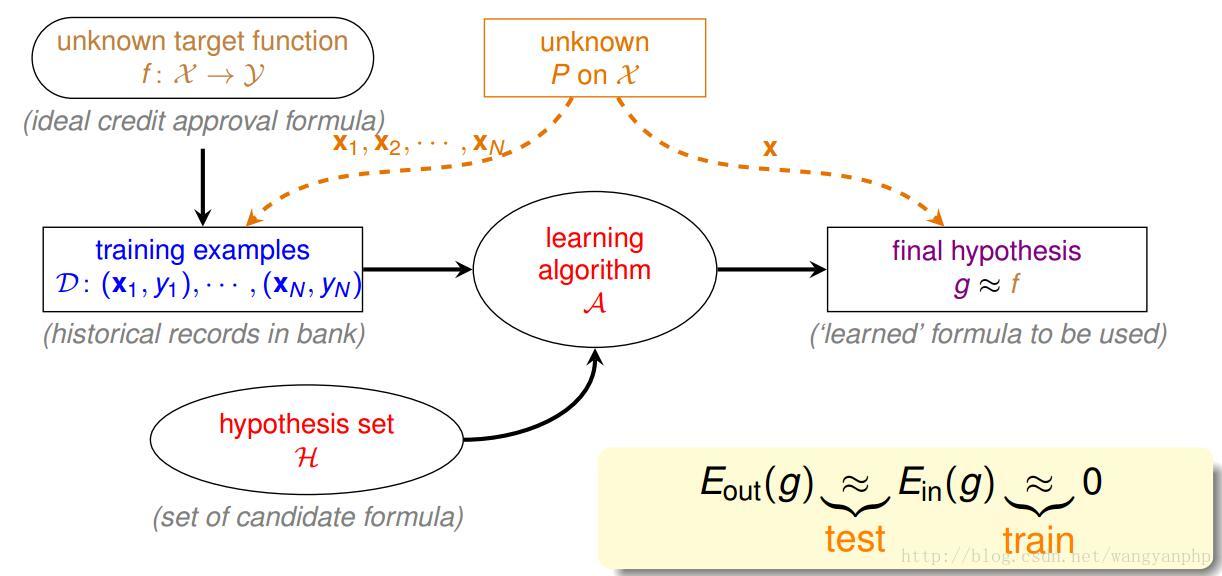
几个术语:[输入输出变量用大写表示;输入输出变量所取的值用小写表示]
- 输入空间X:输入x的所有可能取值的集合;
- 输出空间Y:输出y的所有可能取值集合;
- 训练数据D;
- 未知的目标函数
- 假设空间H:由输入空间到输出空间的映射的集合。H的确定意味着学习范围的确定
监督学习问题的文字描述:假设存在某目标函数
2.2 机器学习方法的步骤
根据上面的描述,我们可以得到实现机器学习方法的步骤:
1. 得到一个有限的训练数据集合;
2. 确定包含所有可能的模型的假设空间,即学习模型的集合;
3. 确定模型选择的准则,即学习的策略;
4. 确定求解最优模型的算法,即学习的算法;
5. 通过学习方法选择最优模型;[3、4、5合起来就是学习算法A]
6. 利用学习的最优模型对新数据进行预测和分析。
上述的6个步骤都很重要,我们会逐个讲解,其中模型的假设空间、模型选择的准则和魔性学习的算法称为机器学习算法三要素,简称:模型(model)、策略(strategy)和算法(algorithm)。
2.3 进阶版机器学习形式化描述图
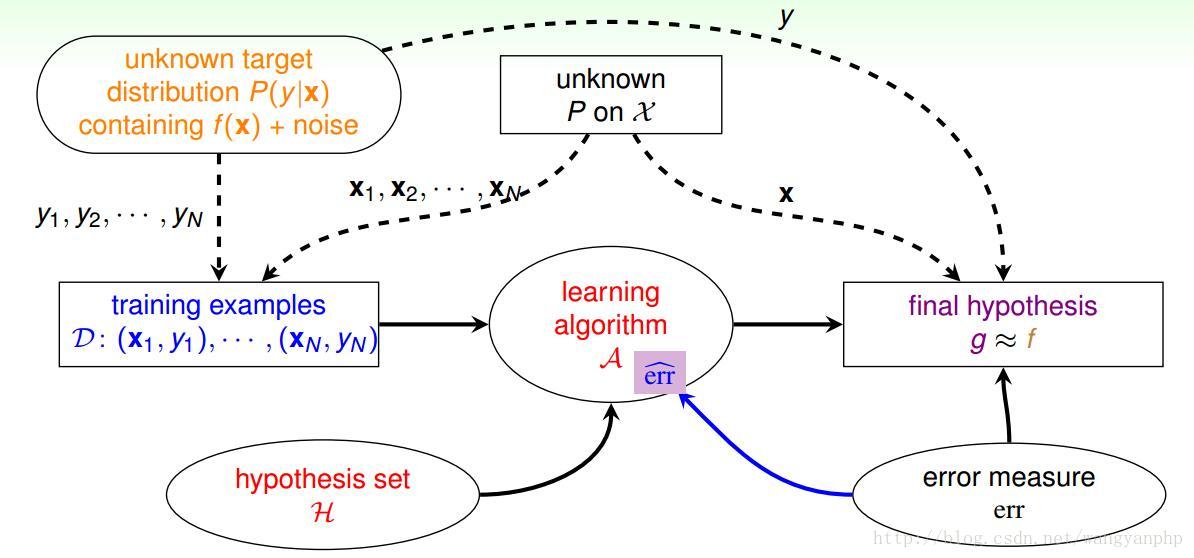
这与之间的图有两点不同;
1. 之前的training data D的来源是:(x,f(x))。其中x从服从某一概率分布P(x);现在我们假设D来源于(x,f(x)),其中x服从某一P(x),f(x)+Noise服从某一P(y);也即:X和Y服从某一联合概率分布P(x,y)。
2. 加入了error measure err和学习算法A中的
根据上述的形式化描述,我们自然而然的产生如下问题:
3. Q1:学习策略是怎么的?
也即给定假设空间H,按照什么样的准则学习或选择出最优的模型g?
对于监督学习问题,假设从H中选择了一个决策函数f,那么f(X)与Y可能有差距,用一个损失函数(loss function)或代价函数(cost function)来度量预测错误的程度。
- 0-1损失函数
- 平方损失函数
- 绝对损失函数
- 对数损失函数
对于y={-1,1}的二分类问题有:
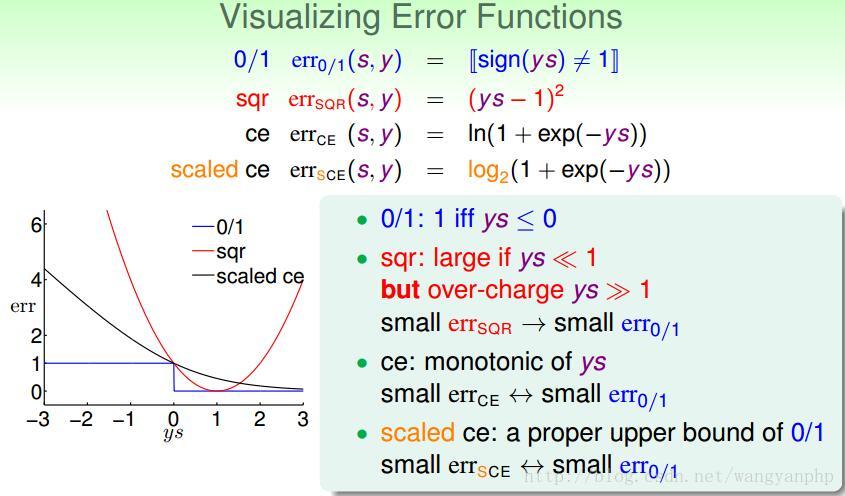
损失函数越小,模型就越好。损失函数的期望是:
问题是
根据大数定律,当N足够大时,

至此,我们得出的结论是:
策略1:选择假设空间H中使得经验损失最小的函数作为最优模型g。
4. Q2:学习算法A采用策略1是正确的吗?
以二分类问题为例,我们来论述此问题,
那么策略1就是:在假设空间H中选择
我们的问题是:g是不是H中使得
在N非常大的情况下,根据大数定律,
4.1 在N有限的情况下
4.1.1 Hoeffding不定式
对于H中某一模型h,对于数据集D(size=N)必然有
也即:如果N足够大,
4.1.2 学习算法使用策略1的效果
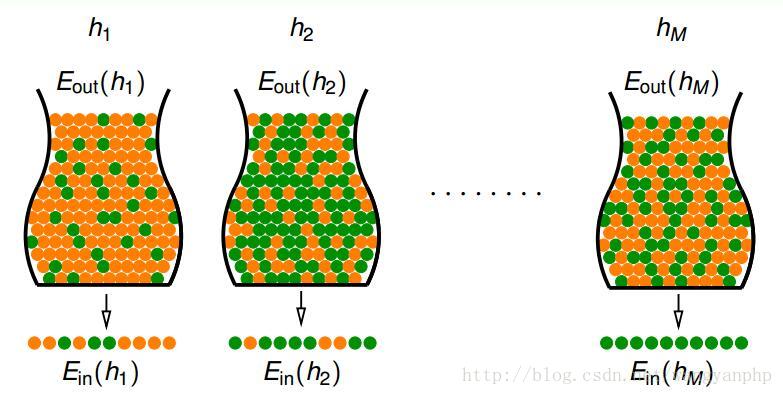
橘色表示h预测错误的样本,绿色表示h预测正确的样本。罐子里代表所有样本,抓出来的代表训练样本。
那么,按照策略1,学习算法A就是在寻找
这是什么意思呢?
对于A算法选择h过程,我们要考虑的问题是:h在D上的表现能不能代表h在整体上的表现。假设hypothesis set H无限多,那么总有瞎猫碰上死耗子的可能性:有一个h在D上表现完美,而在整体上表现很差。也即问题是:h1,…,h5在D上的表现可以代表在整体上的表现,而h6在D上的表现不能代表其在整体上的表现。但是A选择了h6,那么结果就与我们的预期大相径庭了。
于是,策略1的使用条件是:对于hypothesis set中的所有的h,h在D上的表现都能代表h在整体上的表现。
4.1.3 “H在D上的表现能代表H在整体上的表现”的概率
h在D上的表现都能代表h在整体上的表现我们称为GOOD D for h。
假设对于D,根据Hoeffding定理,只有指定了
那么对于某一个D,只有对于H中所有的h都是GOOD,才是对于H是GOOD
也即:H在D上表现能代表H在整体上表现的概率是
4.1.4 公式推导
根据上面的结论,有:
假设我们指定以
有
4.2实际运算
现实情况下,我们使用测试误差来评价
假设我们有一个测试数据集,数据从来没有使用过。根据Hoeffding不等式,我们有
只要测试数据集的size N足够大,我们就可以用测试误差来评价
4.3总结
学习方法的泛化能力(generalization ability)是指由该方法学习到的模型对未知数据的预测能力,是学习方法本质上重要的性质。现实中采用最多的方法是通过测试误差来评价学习方法的泛化能力。
由于测试样本有限,所以测试结果不一定可靠,我们也可以从理论上来分析泛化能力。
5 Q3:如何确定假设空间?
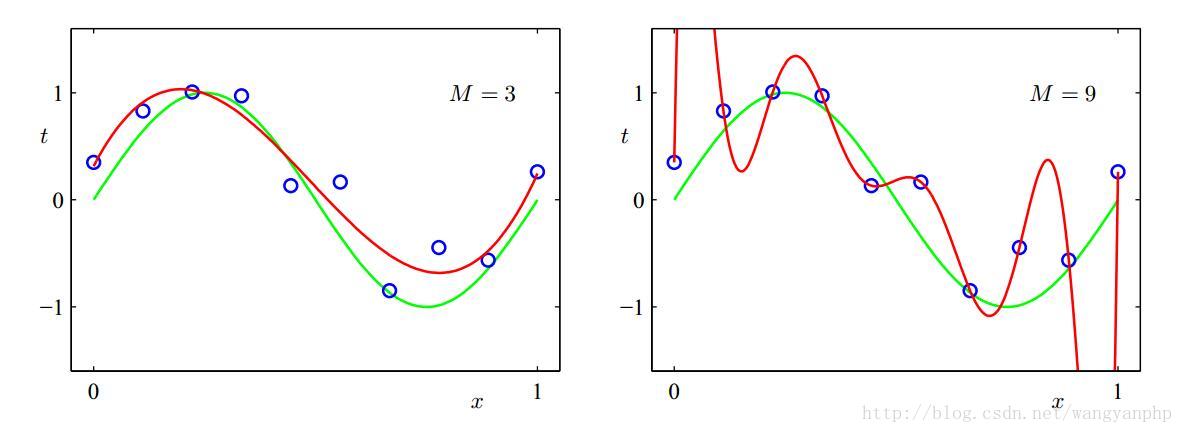
两个假设空间:一个是三阶多项式空间;一个是9阶多项式空间。
根据我们第4节的学习算法,可知:应该选择9阶假设空间里的最优模型g。
但是很明显,3阶多项式空间的模型更好。
这里发生了了什么?
根据
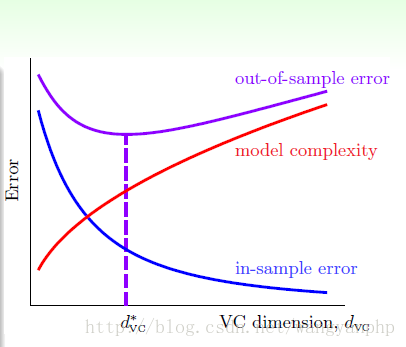
当模型太简单时,
5.1什么时候发生过度拟合?
我们主要关注与影响
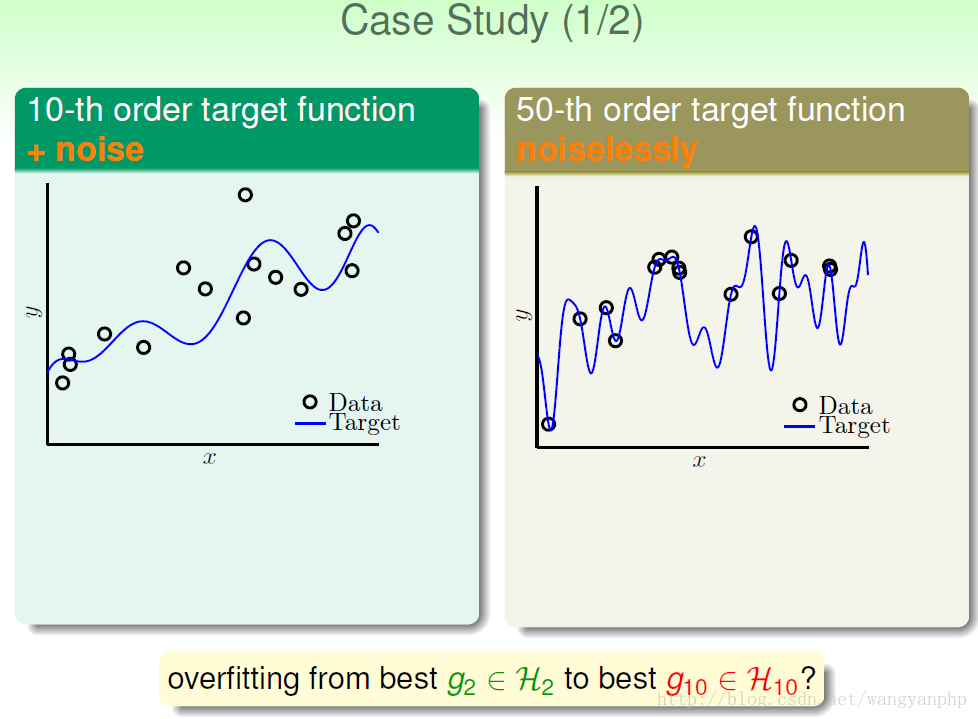
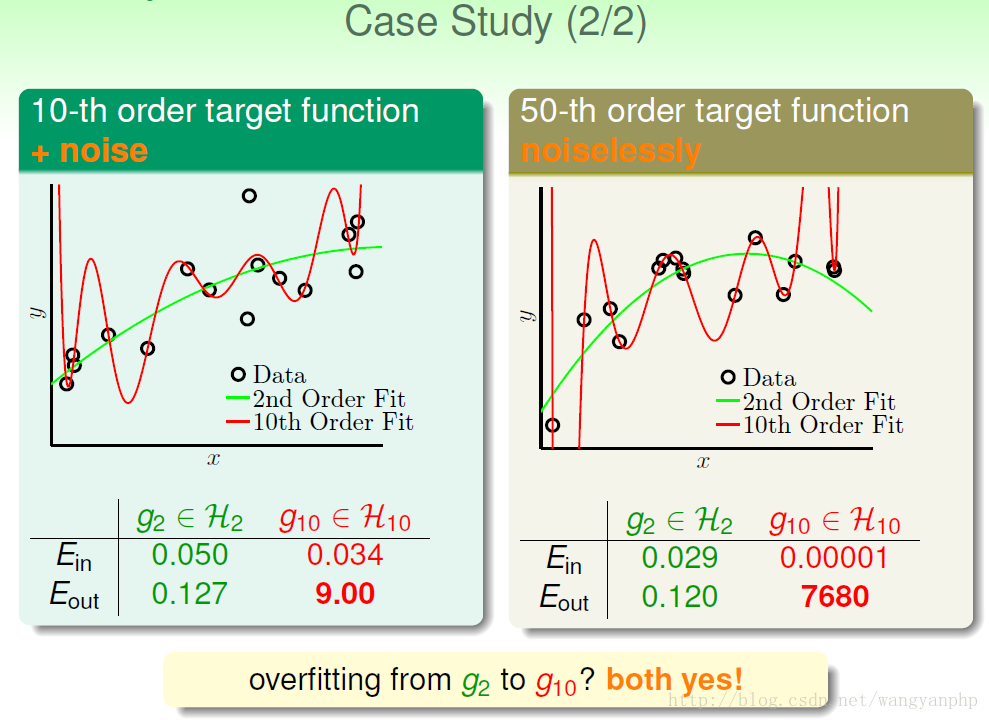
我们可以看到:训练数据集D的size N的大小,非常重要:
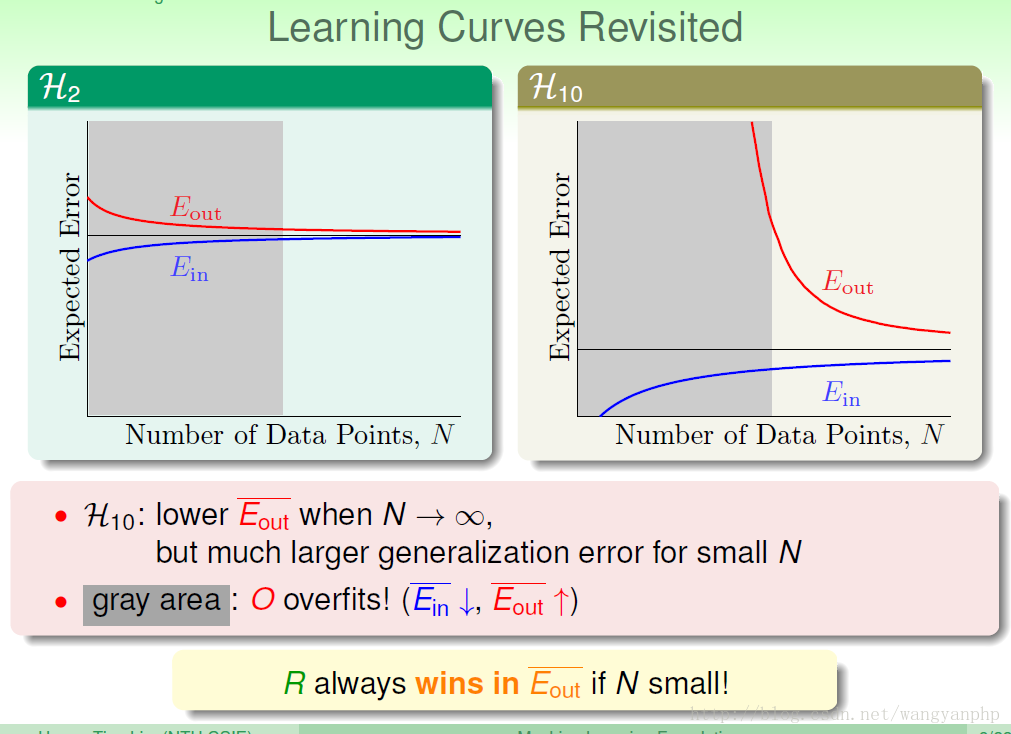
我们可以看到,当N偏少的时候,简单模型的表现要比复杂模型的表现要好;但是当N足够大的时候,复杂模型的表现一定要比简单模型的表现要好。
同时我们可以看到,数据的噪声也影响是否过拟合,
我们说:D的size N、noise、还有目标函数的complexity level(阶数)Q都会影响overfitting。
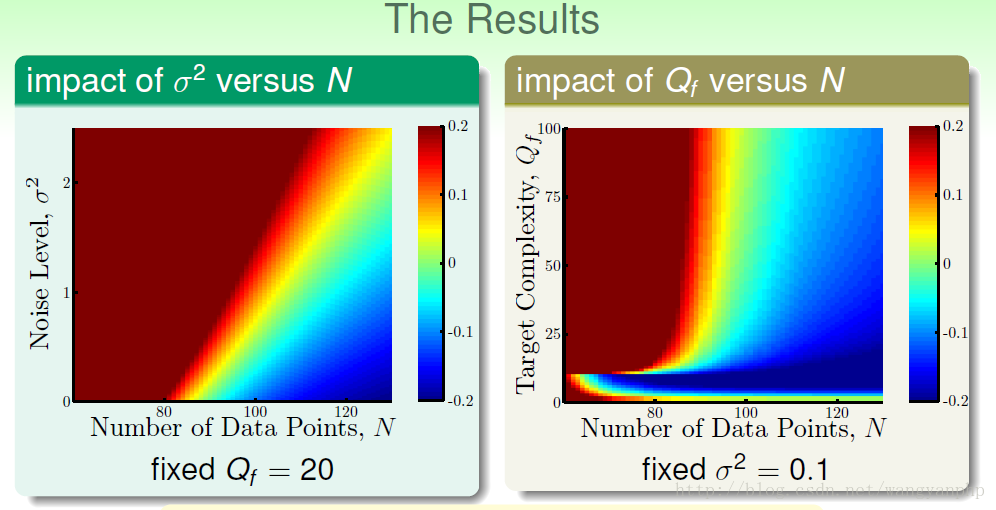
我们通常可以把模型复杂度看做是确定的噪声。
5.2怎么克服过拟合?
根据之前说的:但是当N足够大的时候,复杂模型的表现一定要比简单模型的表现要好。
通常为了模型表现良好,我们使用复杂假设空间,然后采用一些克服过拟合的技巧,会得到良好的g。
许多算法的设计都需要考虑如何克服过度拟合。
最常用的方法是正则化(regularization)。
正则化是在经验风险上加一个正则化项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化的值就越大。[具体细节可以参考这里]
5.3如何选择假设空间?
假设我有很多假设空间
其中我们对每一个假设空间学习计算出最优模型(已采用克服过拟合的技巧),我们得到
对比从一个假设空间中选择最优模型的过程:从
这两个过程是相同的,所以存在的问题也是相同的。
对于从
对于从
所以我们需要三个数据集:
- training data set用来训练模型;
- 验证集validation data set用来进行模型的选择;
- test set来用对学习方法进行评估。
倘若我们把数据一分为3,那么用来作为训练的数据量就大大减小了。也就是说,对于一个H来说,训练数据量减少,就会导致模型的性能下降。(根据统计学,N越大,模型越好)
5.3.1 K-fold交叉验证
为了解决上述问题,采用K-fold的方法,具体参加这里。
(待补充)
6. 总结
在按照机器学习的步骤梳理一遍:
1. 得到一个有限的数据集。然后将数据集分成三份:training set,validation set和test set(6:2:2);或者选用K-fold交叉验证,此时数据集分成两份:training set和test set(7:3)。
2. 确定包含的所有可能的模型的假设空间。可能需要选用多个假设空间,此时需要使用validation进行模型选择。
3. 确定模型选择的策略,以及求解最优模型的算法:需要考虑过拟合问题以及解决方法;需要确定损失函数;
4. 使用test set评估最优模型。