小知识点:
法向量:垂直于平面的直线所表示的向量为该平面的法向量
法向量一般是方程的系数,比如:Ax+By+Cz+d = 0,那么法向量就是(A,B,C)
证明如下:

一、范数:
L0范数:向量中非0元素的个数
L1范数:向量中各元素的绝对值之和
L2范数:向量中各元素的平方和然后求平方根
二、经验风险与结构化风险:
经验风险:
在假设空间、损失函数以及训练数据集确定的情况下,经验风险函数式就可以确定,经验风险最小化的策略认为经验风险最小的模型是最优的模型。根据这一策略,按照经验风险最小化来求解最优模型就是求解最优化问题:

结构化风险:
是为了防止过拟合而提出来的策略,结构风险最小化等价于正则化,结构风险是在经验风险上加上表示模型复杂度的正则化项或者罚项
结构风险最小化的定义如下:

J(f)是模型的复杂度,不同的模型会用不同的J(f)表示;
比如:logistic回归和线性回归用参数的L2范数
而贝叶斯估计中就是最大后验概率估计(当模型是条件概率分布、损失函数是对数损失函数、模型复杂度由模型的先验概率表示,结构风险最小化就等价于最大后验概率估计)
三、正则化:
正则化是结构化风险最小策略的实现,是在经验风险上加一个正则化项。正则化项一般是模型复杂度的单调递增函数,模型越复杂,正则化值就越大。
正则化一般具有如下形式:
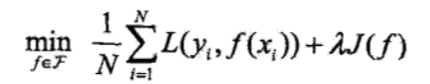
其中第一项是经验风险,第二项是正则化项,是正则化系数
正则化项可以去不同形式,在logistic和线性回归中可以是参数向量的L2范数
正则化的作用是选择经验风向和模型复杂度同时较小的模型
四、交叉验证
交叉验证的由来:如果给定的样本数据充足,进行模型选择的简单方法就是将数据分成三部分,分别为训练集、验证集、测试集。训练集用来训练模型,验证集用于模型的选择,而测试集用于最终对学习方法的评估。在学习到的不同复杂度的模型中,选择对验证集有最小预测误差的模型,由于验证集有足够多的数据,用它对模型进行选择也是有效的。但是在实际应用中往往数据是不充足的,为了选择好的模型,可以使用交叉验证的方法。
基本想法:
基本想法是重复的使用数据,把给定的数据进行切分,将切分得到的数据集组合为训练集与测试集,在此基础上反复地进行训练、测试以及模型选择。
1、简单交叉验证:
首先随机的将已给的数据分成两部分,一部分作为训练集,另一部分作为测试集;然后用训练集在不同的条件下(例如:不同的参数个数)训练模型,从而得到不同的模型;在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
2、S折交叉验证:
应用最多的就是S折交叉验证,方法如下:首先随机的将已知数据切分为S个互不相交的大小相同的子集,然后利用S-1个子集的数据训练模型,余下的一个自己测试模型;将这一过程对可能的S种选择重复进行,最后选出S此评测中平均测试误差最小的模型。
3、留一交叉验证:
S折交叉验证的特殊情况S=N,称为留一交叉验证,往往在数据缺乏的情况下使用,这里N是给定数据集的容量。
五、泛化误差
指的是学习到的模型对未知数据的预测能力,事实上泛化误差就是所学到模型的期望风险。
泛化误差上界:
学习方法的泛化能力分析往往是通过研究泛化误差的概率上界进行的,简称为泛化误差上界。泛化误差上界通常具有以下性质:1、它是样本容量的函数,当样本容量增加时,泛化误差上界趋于0;它是假设空间容量的函数,假设空间容量越大,模型就越难学,泛化误差上界就越大。