由于之前用urlib和request发现只能获取静态网页数据,目前爬取动态网页有两种方法,
(1)分析页面请求
(2)Selenium模拟浏览器行为(霸王硬上弓),本文讲的就是此方法
一、安装selenium
- 首先下载selenium
进入pip.exe目录
(一般在python安装目录Scripts文件夹下,如..\Python34\Scripts)
运行安装命令:pip install selenium
2.下载geckodriver
geckodriver为Selenium Firefox 官方Webdriver
在如下路径可下载
https://github.com/mozilla/geckodriver/releases
下载解压后将geckodriver.exe文件放在python可执行文件python.exe同一目录之中
ps:需要对应Firefox 45以上版本,selenium需要3以上版本
二、测试代码:python版本:3.4.3,python IDE:pycharm4.0.4
#coding=utf-8
from selenium import webdriver
from selenium.common.exceptions import StaleElementReferenceException
'''
from bs4 import BeautifulSoup
import requests
from selenium.common.exceptions import NoSuchElementException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By #按照什么方式查找,By.ID,By.CSS_SELECTOR
from selenium.webdriver.common.keys import Keys #键盘按键操作
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait #等待页面加载某些元素
from time import sleep
'''
#将webdriver获取的WebElements类型数据转换为列表存储
def elementsToList(WebElements):
data = []
#print('类型:' + type(WebElements).__name__)
if(type(WebElements).__name__ != "list"):
print("WebElements参数数据类型错误")
return data
try:
for element in WebElements:
#if(element)
#print(element.text)
data.append(element.text)
#print(element.text)
except StaleElementReferenceException as e:
print('页面发生了重载,之前定位的元素失效,错误信息%s:' % e)
return data
#获取网页指数行情信息
def getIndexInfo(url):
browser = webdriver.Firefox()
#browser = webdriver.Chrome()
#url = 'http://quote.eastmoney.com/center/gridlist.html#global_euro'
browser.get(url)
current_page = 0
next_page = 1
while(current_page != next_page): #当下一页码数不等于上一页码数则判断到了最后一页
# print(browser.page_source)
# print(browser.current_url)
#browser.implicitly_wait(30) #隐私等待
# 获取当前页数号码
current_page = browser.find_element_by_class_name('paginate_button.current')
print('当前页:', current_page.text)
# 获取下一页按钮位置
element = browser.find_element_by_id('main-table_next') # 或者用这个方式查找 element = browser.find_element_by_class_name('next.paginate_button')
#获取行情字段信息
indexname_elements = browser.find_elements_by_class_name('global-index-name') # 指数名称
price_elements = browser.find_elements_by_class_name('listview-col-Close') # 最新价
change_elements = browser.find_elements_by_class_name('listview-col-Change') # 涨跌额
changeprecent_elements = browser.find_elements_by_class_name('listview-col-ChangePercent') # 涨跌幅
open_elements = browser.find_elements_by_class_name('listview-col-Open') # 开盘价
high_elements = browser.find_elements_by_class_name('listview-col-High') # 最高价
low_elements = browser.find_elements_by_class_name('listview-col-Low') # 最低价
preclose_elements = browser.find_elements_by_class_name('listview-col-PreviousClose') # 昨收价
amplitude_elements = browser.find_elements_by_class_name('listview-col-Amplitude') # 振幅
updatetime_elements = browser.find_elements_by_class_name('listview-col-LastUpdate') # 最新更新时间
# 获取各行情字段列表
indexname_list = elementsToList(indexname_elements)
price_list = elementsToList(price_elements)
change_list = elementsToList(change_elements)
changegpercent_list = elementsToList(changeprecent_elements)
open_list = elementsToList(open_elements)
high_list = elementsToList(high_elements)
low_list = elementsToList(low_elements)
preclose_list = elementsToList(preclose_elements)
amplitude_list = elementsToList(amplitude_elements)
updatetime_list = elementsToList(updatetime_elements)
#合并为列表形式
index_info = list(zip(indexname_list, price_list, change_list, changegpercent_list, open_list, high_list, low_list, preclose_list, amplitude_list, updatetime_list))
for index in index_info:
print('指数行情:', index)
# 点击下一页
element.click()
# 获取下一页页码号数
next_page = browser.find_element_by_class_name('paginate_button.current')
print('下一页:', next_page.text)
browser.close() # 关闭该页面
browser.quit() # 浏览器退出
#url = 'http://quote.eastmoney.com/center/gridlist.html#global_america' # 美洲股市
#url = 'http://quote.eastmoney.com/center/gridlist.html#global_euro' #欧洲股市
url = 'http://quote.eastmoney.com/center/gridlist.html#global_asia' # 亚洲股市
try:
getIndexInfo(url)
except Exception as e:
print('错误信息:%s' % e)
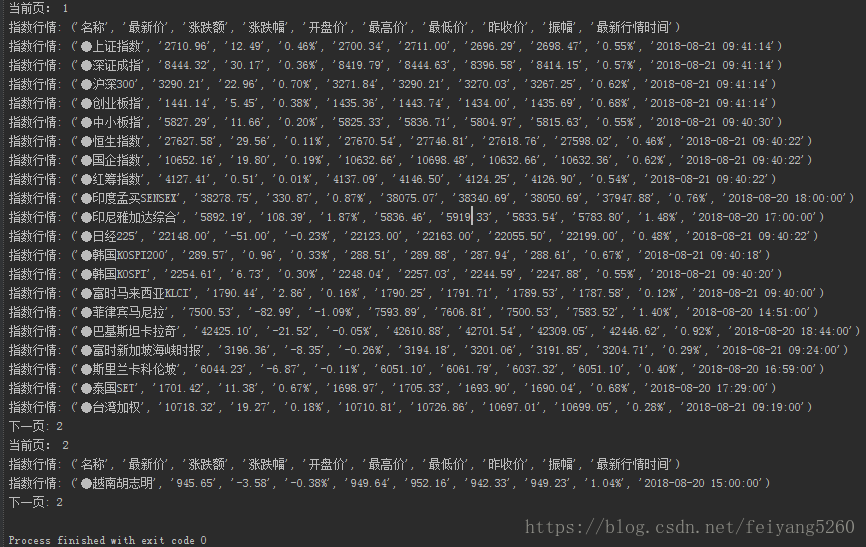
运行结果如下:
总结
用selenium模拟网页点击获取多页数据方法效率较慢,且对于多页数据,经常出现如下错误,
错误信息:
Message: The element reference of <td class=" listview-col-Change"> is stale; either the element is no longer attached to the DOM, it is not in the current frame context, or the document has been refreshed
页面发生了重载,之前定位的元素失效,需重新定位元素(方法自行百度)
建议动态爬取多页数据时不用Selenium,用分析页面请求方法,此方法待进一步实验研究......