需要的工具有:pycharm,datagrip,robo 3t
1.获取财富网的ulr

因为爬取多个页面,需要将页面k变成字符串类型,最终拼接成新的fulurl
2.导入所需要的第三方库

3.为了反爬虫,我们添加header,其中header中含有多个浏览器内核,我只添加了两个,每次循环random随机选择一个

4.在第一步获取了fulurl之后,检查网页源码,我们需要爬取 等字段,然后我们创建一个csv文件,并将字段写进去。
等字段,然后我们创建一个csv文件,并将字段写进去。

接下来我发送请求,用BeautifulSoup解析,然后通过find_all去找到字段所在标签

通过find_all返回后的t是一个list,其中list里包含所有要爬取的内容。
5.接下来对list进行遍历,把每条标签取出来,通过contents去掉标签,取出标签里面内容。

在爬取过程中发现字段“标题”中含有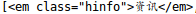 ,需要将这条剔除
,需要将这条剔除

通过把“标题”单独提取出来,然后判断长度,标准数据长度是1,所以等于1可以继续爬取之后字段。
接下来分别对字段选取,其中对应的变量分别是a2,b2,c4,c8,d3。
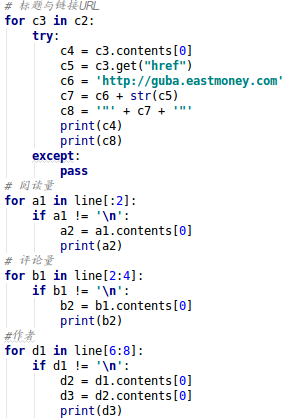
其中在获取url时候,我们通过get方法获取标签中的href属性,但是url含有逗号,csv中是以逗号分别下一行,所以需要在url加上双引号。

接下来将爬取的数据写入csv文件中,最后将整段代码封装成函数。
6.爬取数据如下:
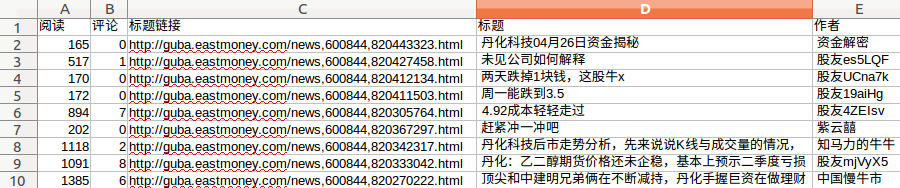
爬取了10000条,只截取了其中10条
7.接下来将数据存入postgresql中,也可以直接在爬数据的时候导入,而我是在爬好的csv文件中导入的。需要用到psycopg2

打开文件读取所有行并返回列表,其中第一行是"阅读,评论,标题链接,标题,作者",所以我们选择第一行以后的数据。

首先通过connect方法链接数据库,创建cursor以访问数据库,然后创建表其中字段"阅读,评论"中包含 所以将以integer换成varchar。
所以将以integer换成varchar。

另外这里需要说明一下,我们要将数据变成tuple类型导入到postgresql中,而csv读取出来的数据是list类型。最后用split以逗号对其分割,用sql语句插入数据库中。

统计存入多少条数据。
最后提交当前事务,关闭数据库。

上图是数据库中的数据。
8.接下来将数据存入mongodb中

需要用到的模块就是pymongo,思路和postgresql基本上一样,但是mongodb需要以dict类型导入进去。

上图是导入数据库之后的数据。