全部代码以及分析见GitHub:https://github.com/dta0502/douban-movie
我突然想看下有什么电影可以看。由于我偏爱剧情类电影,因此我用Python爬虫来爬取剧情类型的电影。
一、单个页面分析及爬取
1、页面分析
首先选择想要看的分类,如下图所示:
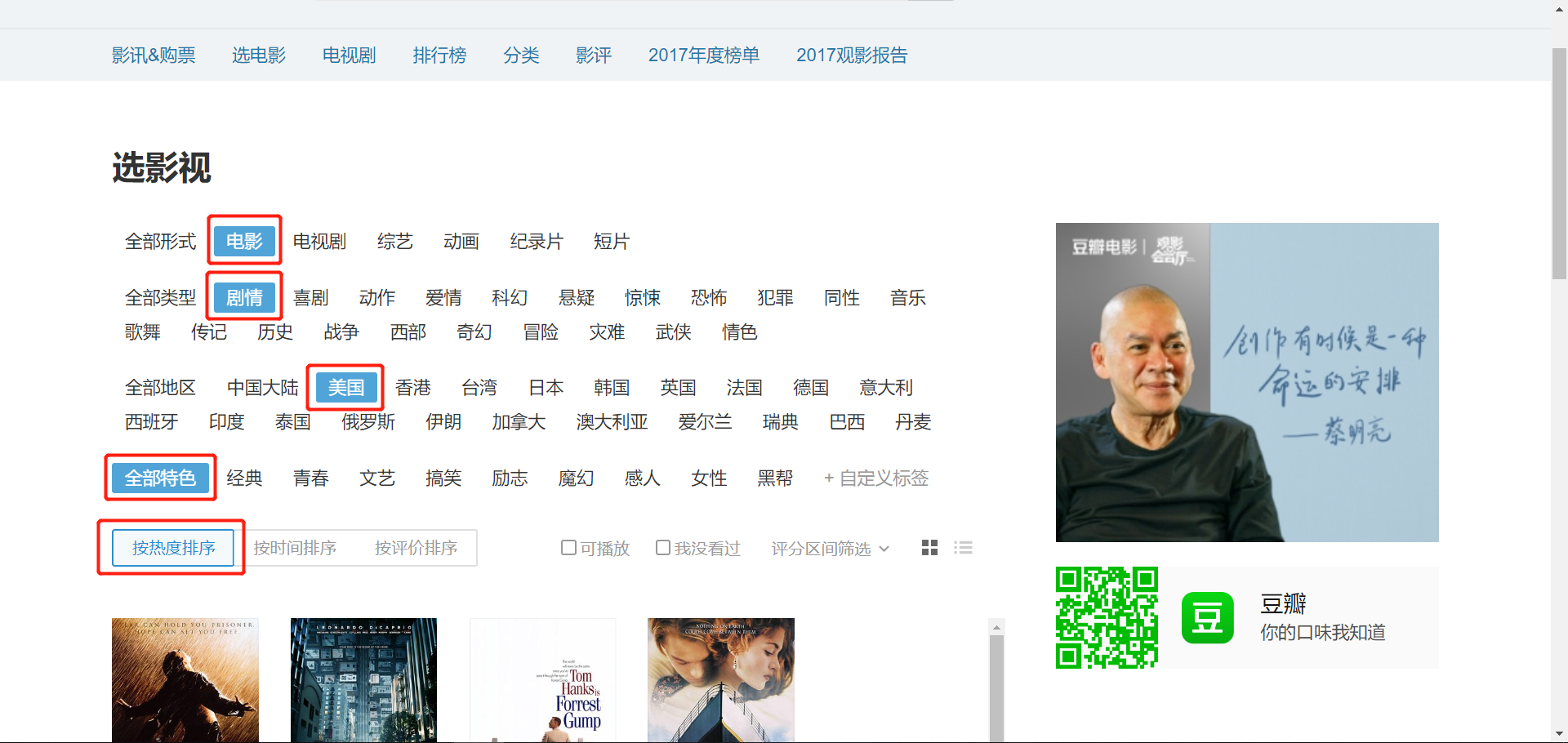
通过chrome的“检查”观察发现真实的URL为
https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=%E7%94%B5%E8%A7%86%E5%89%A7&start=0&genres=%E5%89%A7%E6%83%85&countries=%E7%BE%8E%E5%9B%BD- sort:按热度排序为T、按时间排序为R、按评分排序为S
- tags:类型
- countries:地区
- geners:形式(电影、电视剧…)
- start:“加载更多”
如下图所示:
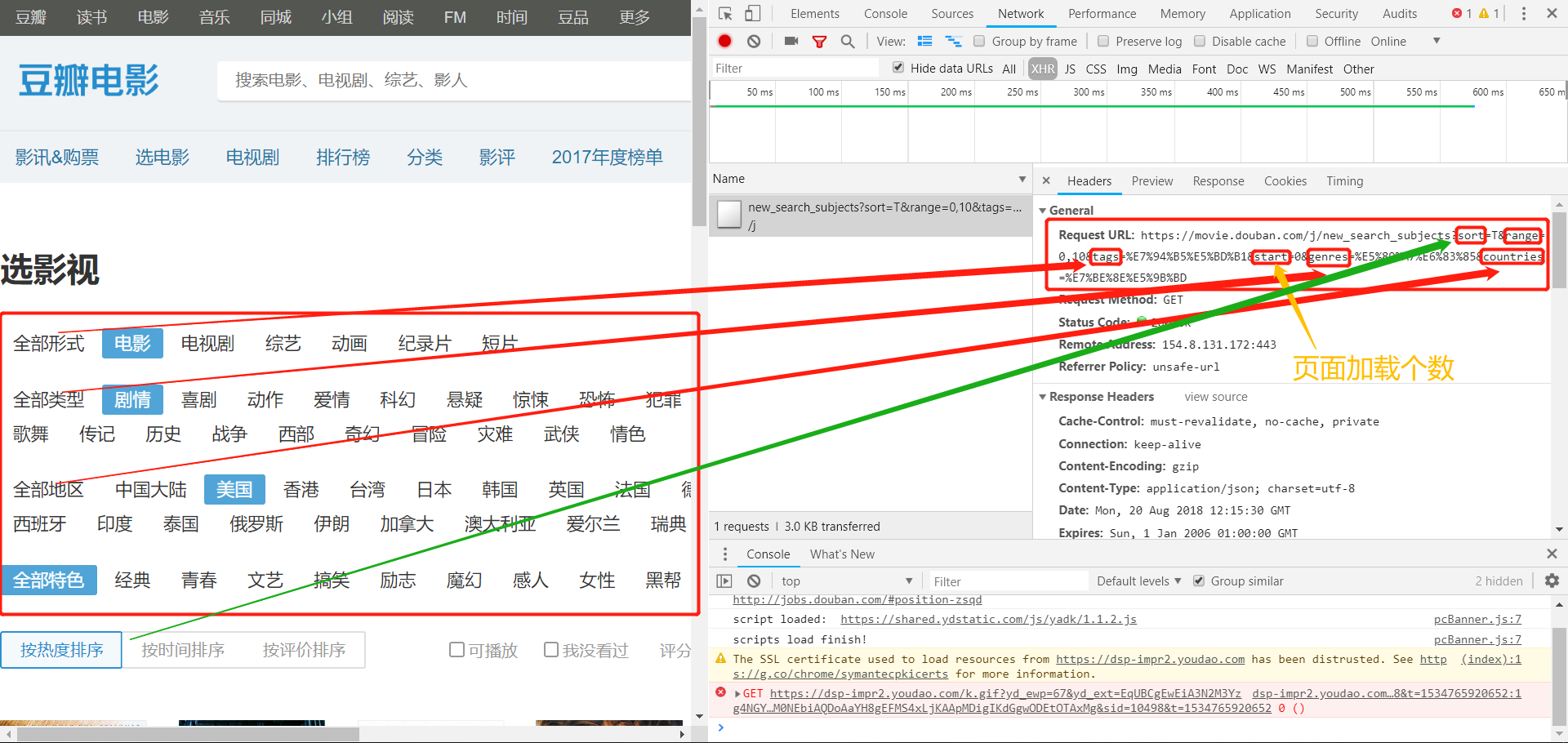
“加载更多”分析
1) 首先要能看网页发回来的JSON数据,步骤如下:
- 打开chrome的“检查”工具
- 切换到network界面
- 选择XHR
- 在页面上点击“加载更多”后会看到浏览器发出去的请求
- Preview界面可以看到接受到的JSON数据
全部过程如下图所示:
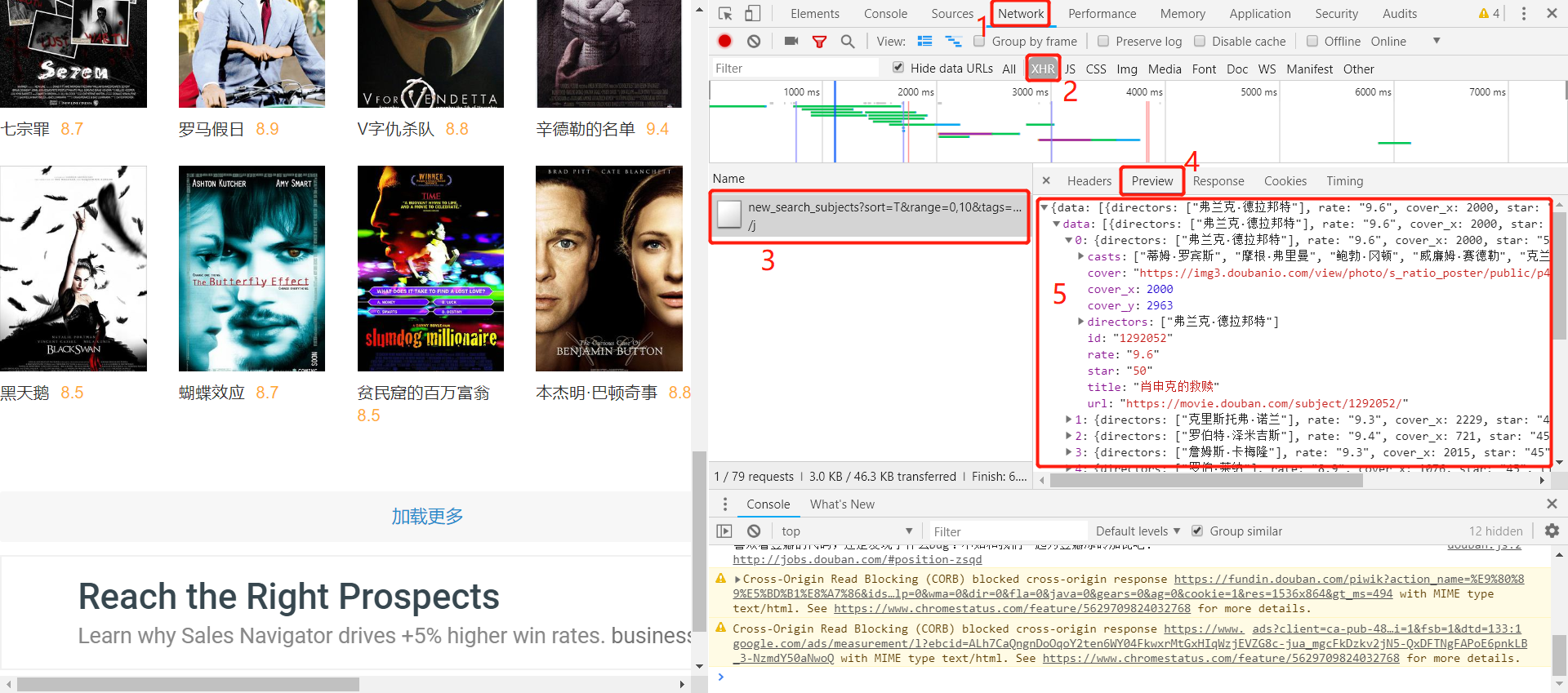
下面是上述过程的URL:
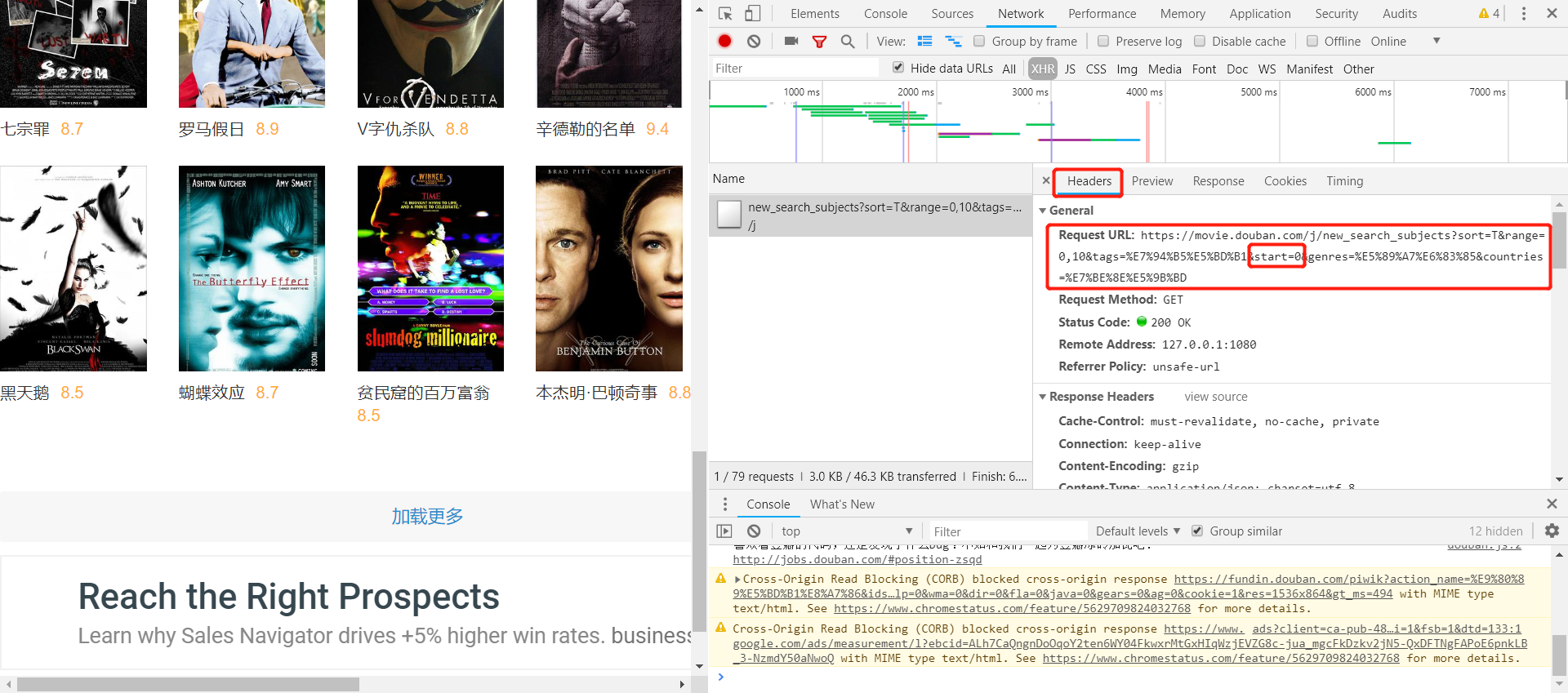
2) 现在我们可以来看下点击“加载更多”这个过程的URL的变化
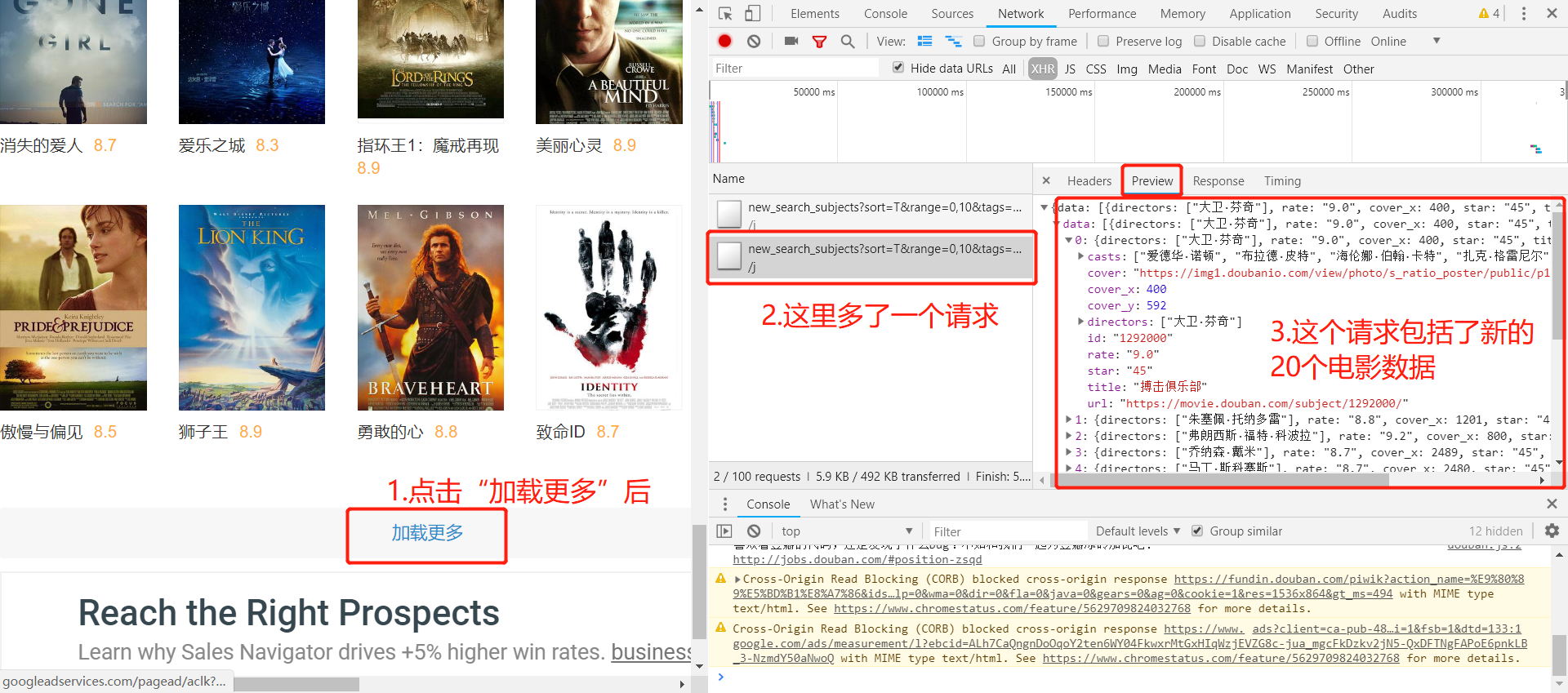
下图是点击加载更多加载出来的JSON数据:
下图是上述过程的URL:
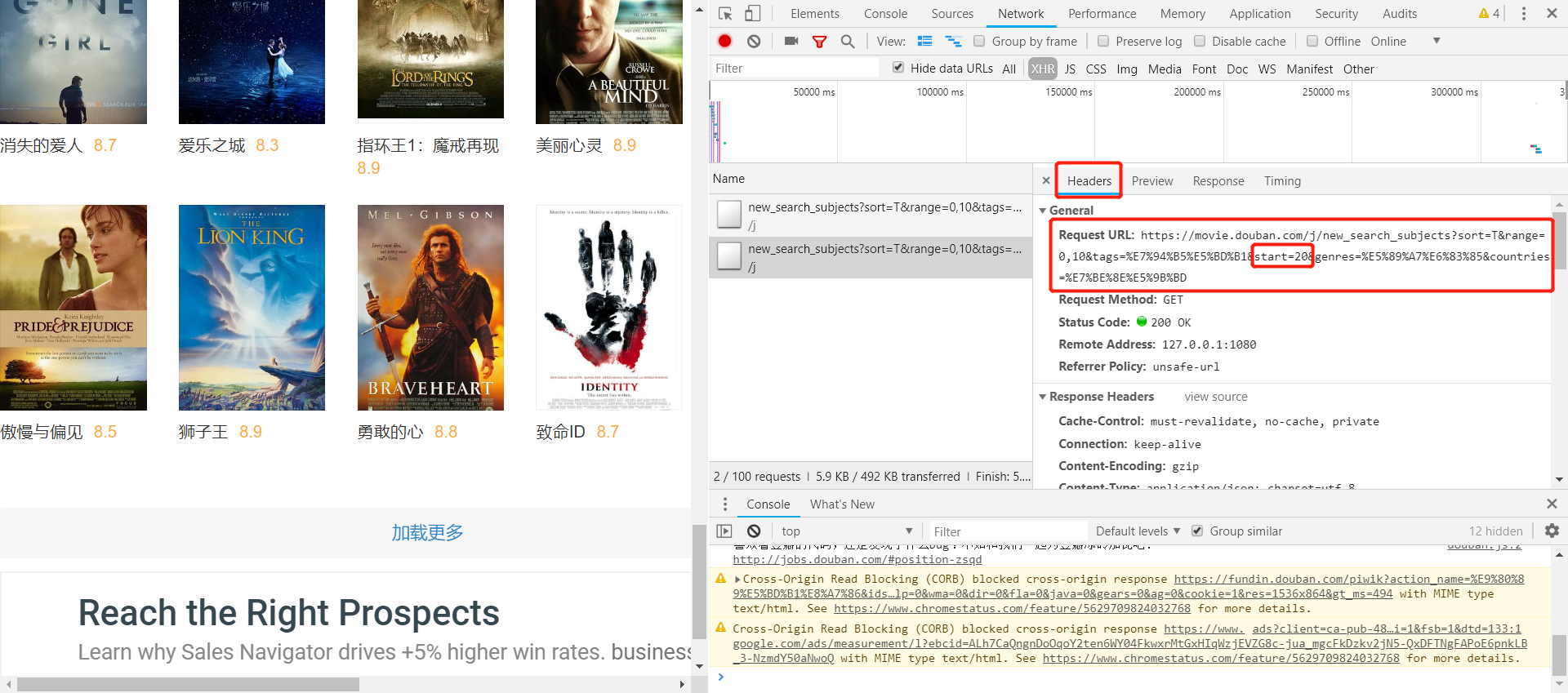
这里可以发现,每次点击“加载更多”,每次会增加显示20个电影,真实URL中的start这个参数从0-20-40…变化,发送回来最新加载出来的20个电影的JSON数据,了解了这些以后,下面就可以用代码实现抓取了。
2、Python爬取(baseline model)
导入库
import requests
from lxml import etree
import json
import pandas as pd页面爬取
url = "https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=20&genres=%E5%89%A7%E6%83%85&countries=%E7%BE%8E%E5%9B%BD"
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}
data = requests.get(url,headers = headers).textJSON数据转换为Python中的字典
Python中json.loads和json.dumps对比:
- json.dumps 将Python中的字典转换为字符串
- json.loads 将字符串转换为Python中的字典
dicts = json.loads(data)
dicts字典格式转换为Pandas DataFrame格式
df = pd.DataFrame(dicts["data"])
df.head()删除DataFrame中不需要的列。
df.drop("cover_x",axis = 1,inplace = True)
df.drop("cover_y",axis = 1,inplace = True)
df.head()二、一次性爬取多个url
根据上面的分析,现在已经完成了爬取单页面20本电影的功能,下面实现下一次性抓取500本电影数据。
import requests
from lxml import etree
import json
import pandas as pdheaders = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36"}下面采用了一个循环,循环改变URL中的start数值(0-20-40…-480),单次循环爬取20本电影的数据,转换为Pandas DataFrame格式,然后和之前得到的数据进行拼接。
for i in range(0,481,20):
url = "https://movie.douban.com/j/new_search_subjects?sort=T&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={页面}&genres=%E5%89%A7%E6%83%85&countries=%E7%BE%8E%E5%9B%BD".format(页面 = i)
data = requests.get(url,headers = headers).text
dicts = json.loads(data)
df = pd.DataFrame(dicts["data"])
if i == 0:
total_df = df
else:
total_df = pd.concat([total_df,df],axis = 0)下面把包含500本电影数据的DataFrame变量写入csv文件。
total_df.to_csv('movie-0.csv', sep = ',', header = True, index = False)第一个参数是说把dataframe写入到movie-0.csv文件中,参数sep表示字段之间用’,’分隔,header表示是否需要头部,index表示是否需要行号。
全部代码以及分析见GitHub:https://github.com/dta0502/douban-movie