豆瓣电影排名网址:https://movie.douban.com/top250?start=0&filter=
在进去豆瓣电影排名后,打开浏览器的检查功能分析爬取页面源代码,在写请求代码之前,首先我们得找出网页的请求头部。
](https://img-blog.csdnimg.cn/20190118195142570.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3dlaXhpbl80MTcwNDE4Mg==,size_16,color_FFFFFF,t_70)
请求头部中的’User-Agent’,是一个特殊的字符串头,可以使服务器识别客户使用的操作系统及版本,浏览器版本等信息。在做爬虫时加上该信息,可以伪装为浏览器,不加则会被认出为爬虫的风险。
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
接下来,对网页Elements代码进行分析,在未知爬取信息所在的时候,先用鼠标在body上下滑动,在所要爬取信息部分有阴影的时候停下。效果如下:
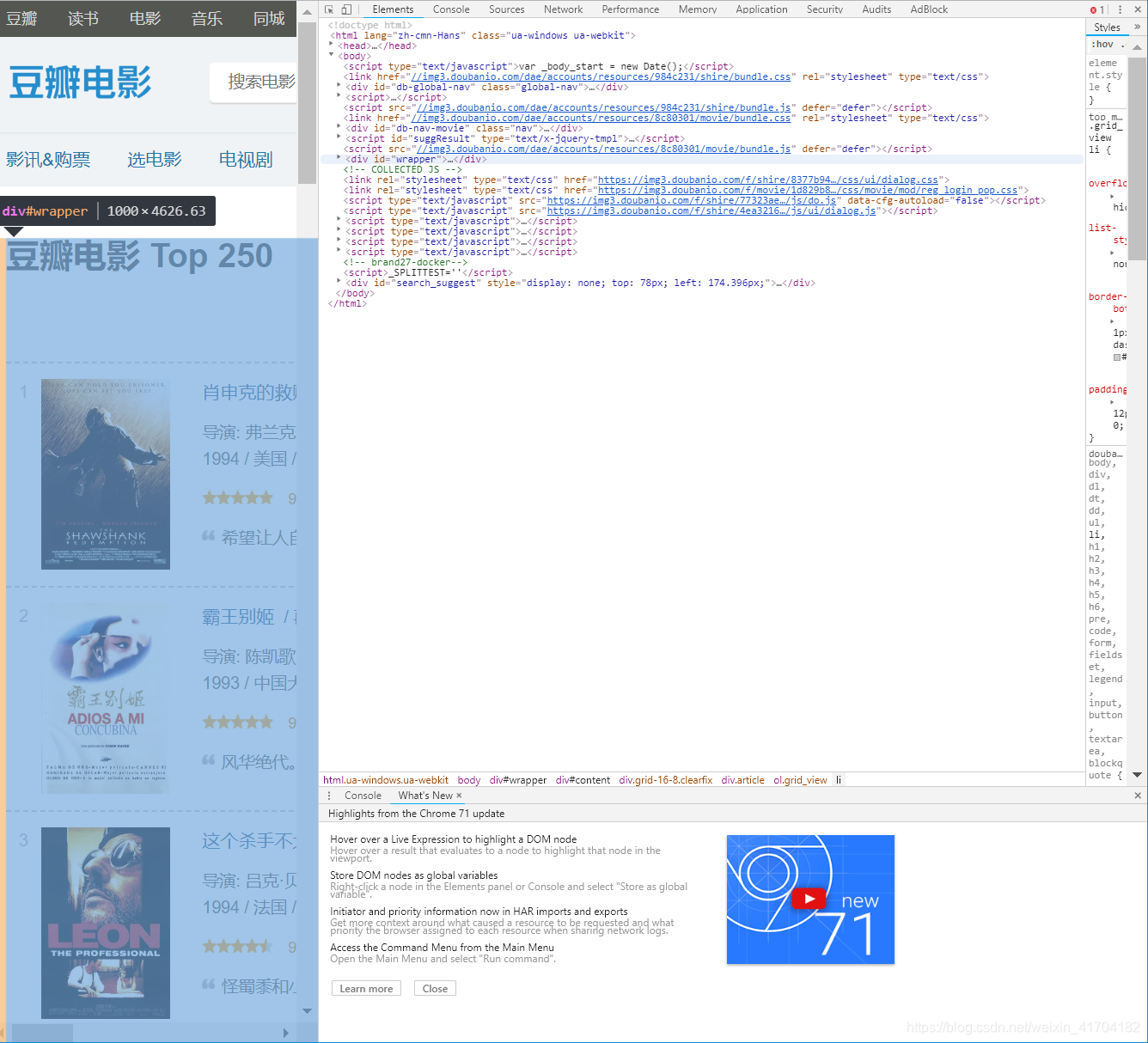
像上一步那样,不断滑动鼠标,最后可以找到所要爬取信息的位置在ol节点中,一般的电影排名或歌曲排名信息都会在ol或ul节点上。
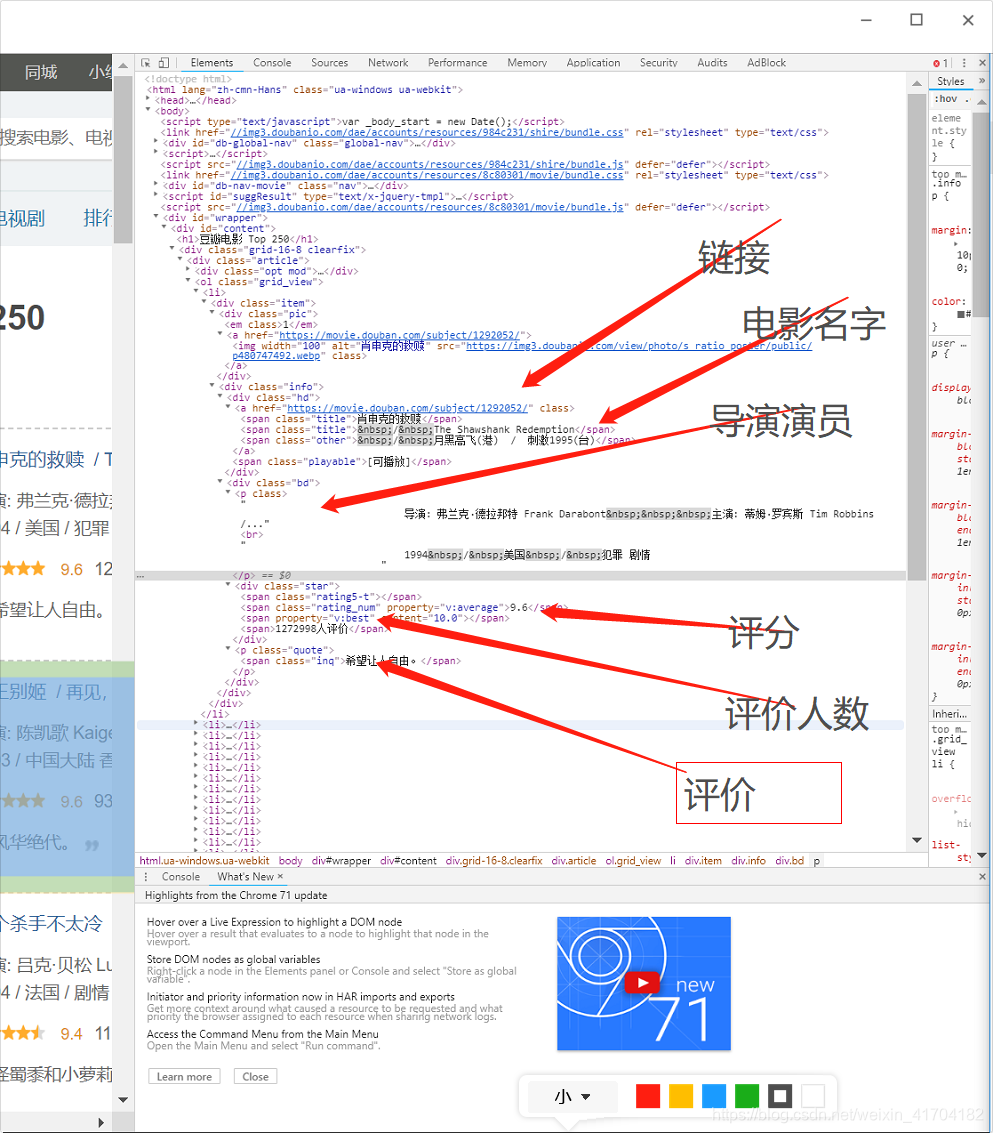
在本次爬虫中,我们只要爬取电影排名中的排名、电影名字、参与人员、评分、评价人数、和评价等信息,所要先找出它们所在的节点,在用CSS选择器选取节点
#利用CSS选择器调用select函数获取排名节点
nums=soup.select('em')
#利用CSS选择器调用find_all函数获取电影名字节点
titles=soup.find_all('div',class_='hd')
#获取电影导演和演员节点
actors=soup.find_all('p',class_='')
#获取链接节点
links=soup.select('ol li div a')
#获取评分节点
rating_nums=soup.find_all('span',class_='rating_num')
#获取评价人数节点
evaluate_numbers=soup.find_all('div',class_='star')
#获取评价节点
evaluates=soup.find_all('span',class_='inq')
上面我们只是选取了信息所在的节点,并没有对提取里面的文本信息,接下来对节点里面的信息进行清洗。
- 排行信息
'排行':num.get_text(),
- 电影名字信息(在源代码中我们可以看到,一部电影不止一个名字,在这里,我们只选取他的中文名字)
'电影名字':title.get_text().split('\n')[2],
- 链接信息
'链接':link.get('href'),
- 导演演员信息
'导演人员':actor.get_text().strip(),
- 评分信息
'评分':rating_num.get_text().strip(),
- 评价人数信息
'评价人数':evaluate_number.get_text().split('\n')[4],
- 评价内容信息
'评价内容':evaluate.get_text()
单页排名信息爬取
def get_top(url):#获取单页电影排名
respose=requests.get(url,headers=headers)
soup=BeautifulSoup(respose.text,'lxml')
#利用CSS选择器调用select函数获取排名节点
nums=soup.select('em')
#利用CSS选择器调用find_all函数获取电影名字节点
titles=soup.find_all('div',class_='hd')
#获取电影导演和演员节点
actors=soup.find_all('p',class_='')
#获取链接节点
links=soup.select('ol li div a')
#获取评分节点
rating_nums=soup.find_all('span',class_='rating_num')
#获取评价人数节点
evaluate_numbers=soup.find_all('div',class_='star')
#获取评价节点
evaluates=soup.find_all('span',class_='inq')
for num,title,link,actor,rating_num,evaluate_number,evaluate in zip(nums,titles,links,actors,rating_nums,evaluate_numbers,evaluates):
data={#获取节点文本
'排行':num.get_text(),
'电影名字':title.get_text().split('\n')[2],
'链接':link.get('href'),
'导演人员':actor.get_text().strip(),
'评分':rating_num.get_text().strip(),
'评价人数':evaluate_number.get_text().split('\n')[4],
'评价内容':evaluate.get_text()
}
print(data)
由于每页中只有25部电影信息,所以要想获取全部的信息时,就必须跳到下一页。
每页URL在其他部分相同,知识在start={ }相差25,而且有10个页面,所以:
for i in range(11):#多页爬取排名
urls={'https://movie.douban.com/top250?start={}&filter='.format(i*25)}
for url in urls:
get_top(url)
完整代码
import requests
from bs4 import BeautifulSoup#导入所需库
#请求头部
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:58.0) Gecko/20100101 Firefox/58.0'}
def get_top(url):#获取单页电影排名
respose=requests.get(url,headers=headers)
soup=BeautifulSoup(respose.text,'lxml')
#利用CSS选择器调用select函数获取排名节点
nums=soup.select('em')
#利用CSS选择器调用find_all函数获取电影名字节点
titles=soup.find_all('div',class_='hd')
#获取电影导演和演员节点
actors=soup.find_all('p',class_='')
#获取链接节点
links=soup.select('ol li div a')
#获取评分节点
rating_nums=soup.find_all('span',class_='rating_num')
#获取评价人数节点
evaluate_numbers=soup.find_all('div',class_='star')
#获取评价节点
evaluates=soup.find_all('span',class_='inq')
for num,title,link,actor,rating_num,evaluate_number,evaluate in zip(nums,titles,links,actors,rating_nums,evaluate_numbers,evaluates):
data={#获取节点文本
'排行':num.get_text(),
'电影名字':title.get_text().split('\n')[2],
'链接':link.get('href'),
'导演人员':actor.get_text().strip(),
'评分':rating_num.get_text().strip(),
'评价人数':evaluate_number.get_text().split('\n')[4],
'评价内容':evaluate.get_text()
}
print(data)
if __name__ == '__main__':
for i in range(11):#多页爬取排名
urls={'https://movie.douban.com/top250?start={}&filter='.format(i*25)}
for url in urls:
get_top(url)
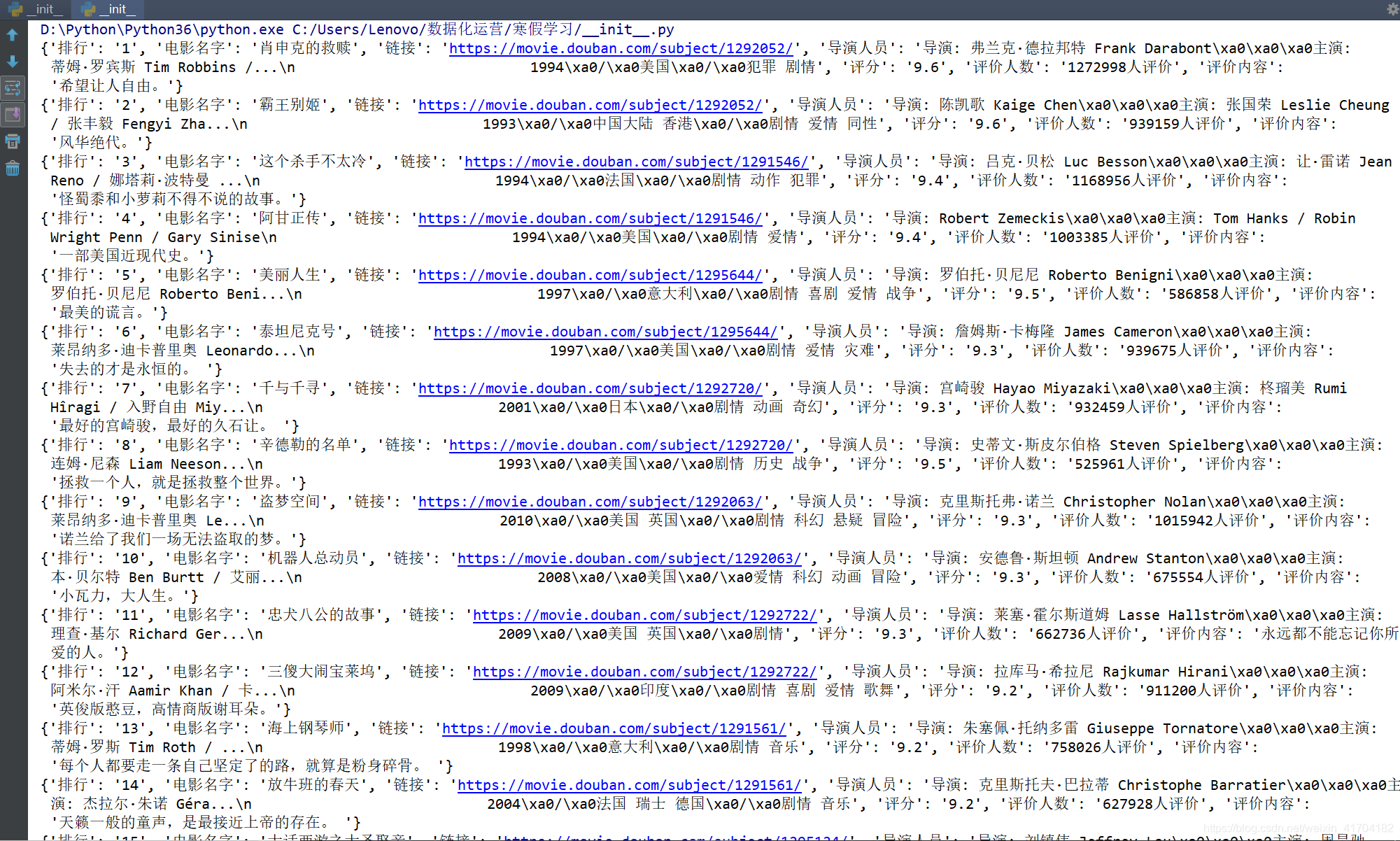
爬取结果