**
1.我想要达到的效果
**
- 1.今天的目的是爬取豆瓣网热门电影的信息
- 2.根据评分给电影排序并输出
**
2.过程
**
- 1.获取豆瓣电影页面
- 2.使用lxml筛选标签得到热门电影的名称与分数
- 3.将名字与分数构成字典以list形式存储起来
- 4.根据分数将电影降序排序
#1.获取豆瓣电影页面
url = "https://movie.douban.com/cinema/nowplaying/shenzhen/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36",
"Cookie": "gr_user_id=17e1ca00-3a4a-4e75-a67c-019cd88c9b84; ll='118282'; bid=zSr4xU7p3dU; __utma=30149280.624623816.1504426147.1505924070.1556208525.4; __utmc=30149280; __utmz=30149280.1556208525.4.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmb=30149280.1.10.1556208525; __utma=223695111.94810675.1556208909.1556208909.1556208909.1; __utmb=223695111.0.10.1556208909; __utmc=223695111; __utmz=223695111.1556208909.1.1.utmcsr=douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/; ap_v=0,6.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1556208910%2C%22https%3A%2F%2Fwww.douban.com%2F%22%5D; _pk_ses.100001.4cf6=*; _vwo_uuid_v2=D192E9B4ABE16D2A474EFE401B535FFF8|ed1fed617a2245bd8f22797ac3b720fe; _pk_id.100001.4cf6=5bfc4314c016ad76.1556208910.1.1556208947.1556208910.; __yadk_uid=FEAGIZXhS1xotfvWYmrUqRMzikCqccYY",
"Referer": "https://movie.douban.com/"
}
response = requests.get(url=url, headers=headers)
html = response.content.decode('utf-8')
#2.使用lxml筛选标签得到热门电影的名称与分数
因为我是将网页以字符串的形式存储,所以直接使用etree.HTML解析即可
①获取每一个热映电影
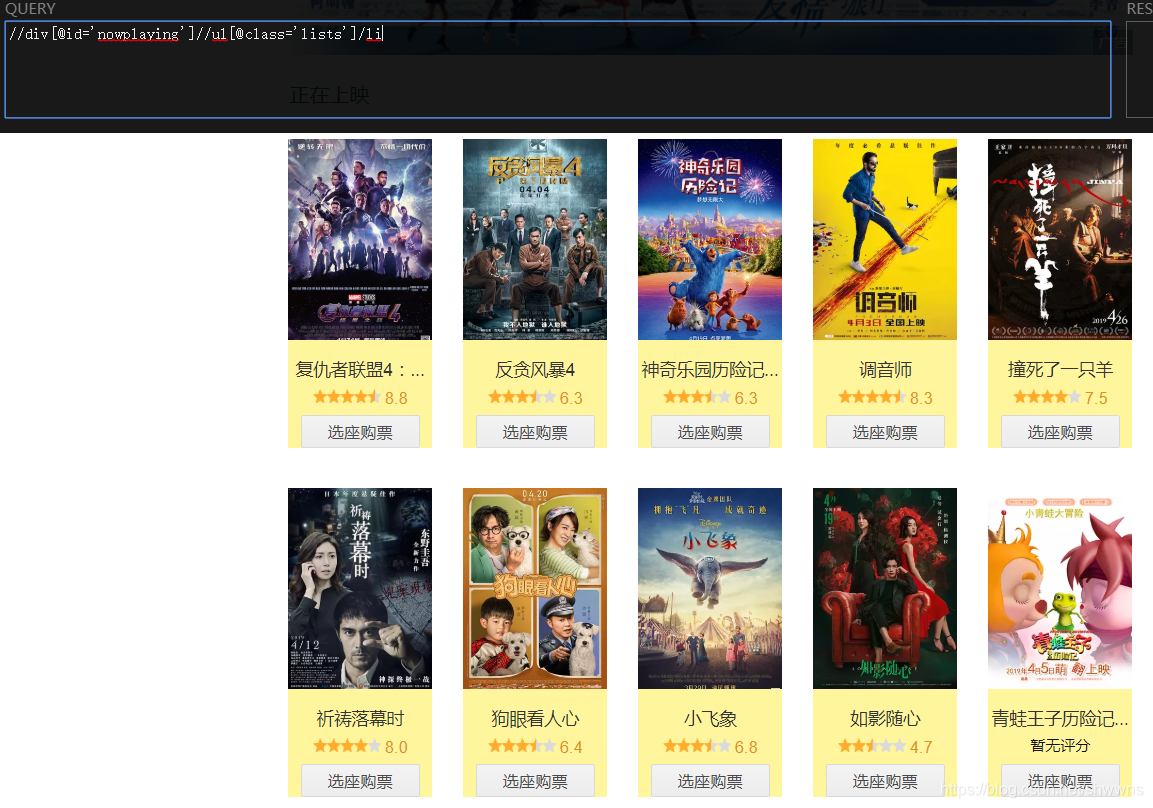
②获取标签

③获取评分

douban_Element = etree.HTML(html)
etree.tostring(douban_Element, encoding='utf-8').decode('utf-8')
lis = douban_Element.xpath("//div[@id='nowplaying']//ul[@class='lists']/li")
movie_detail = {}
movie_list = []
for li in lis:
#标题
title = li.xpath("./ul/li[position()=2]/a/@title")[0]
#评分
score = li.xpath("./ul/li[position()=3]//span[@class='subject-rate']/text()")
if len(score) == 0:
score = '0'
else:
score = score[0]
movie_detail = {
"title": title,
"score": score
}
movie_list.append(movie_detail)
#3.完成排序并输出
每次获取当前分数最高的电影,将其信息append进新的list,然后将其从当前列表中删除
直到当前列表不再存在元素
PS:这里我将暂无评分的电影分数定义为0了
movie_list_Sort = []
#找到旧list中当前score最大的那个字典,将其删除,并在新字典中加入对应的值 while len(movie_list) != 0:
tmp_score = -1.0 # 用来记录当前最大值
tmp_position = 0 # 用来记录当前字典在list的序号
i = 0
for movie in movie_list:
if float(movie.get('score')) > tmp_score:
tmp_score = float(movie.get('score'))
tmp_position = i
movie_detail = {
"title": movie.get('title'),
"score": movie.get('score')
}
i += 1
movie_list.pop(tmp_position)
movie_list_Sort.append(movie_detail)
for t in movie_list_Sort:
print(t)
#4.结果

可以看到众望期待的妇联4果然不失所望啊&-&