当从图像金字塔中的每一层图像上提取特征点之后,都要先用四叉树技术对这些特征点进行管理
//该类中定义了四叉树创建的函数以及树中结点的属性
//bool bNoMore: 根据该结点中被分配的特征点的数目来决定是否继续对其进行分割
//DivisionNode():实现如何对一个结点进行分割
//vKeys:用来存储被分配到该结点区域内的所有特征点
//UL, UR, BL, BR:四个点定义了一个结点的区域
//lit:list的迭代器,遍历所有生成的节点
class ExtractorNode
{
public:
///用初始化列表来初始化本类内的成员变量
ExtractorNode():bNoMore(false){}
void DivideNode(ExtractorNode &n1, ExtractorNode &n2, ExtractorNode &n3, ExtractorNode &n4);
std::vector<cv::KeyPoint> vKeys;
cv::Point2i UL, UR, BL, BR;
std::list<ExtractorNode>::iterator lit;
bool bNoMore;
};
下面的函数实现利用四叉树来管理从金字塔中的每一层图像上提取的特征点
//vToDistributeKeys变量中存储的是从金字塔中某一层图像上提取的特征点
//minX, maxX, minY, maxY:是该层图像去除了边界的区域
//N: mnFeaturesPerLevel[i]表示该层图像上应该提取的特征点的个数
//level: 该图像处在金字塔上的层数
vector<cv::KeyPoint> ORBextractor::DistributeOctTree(const vector<cv::KeyPoint>& vToDistributeKeys, const int &minX,
const int &maxX, const int &minY, const int &maxY, const int &N, const int &level)
{
//常用的相机kinect v1的分辨率是:640*480 kinect v2的分辨率是:1920*1080
//为了尽量使得每一个结点的区域形状接近正方形所以图像的长宽比决定了四叉树根节点的数目
//如果使用kinect v1那么只有一个根结点,如果使用kinect v2那么就会有两个根结点
const int nIni = round(static_cast<float>(maxX-minX)/(maxY-minY));
//hX变量可以理解为一个根节点所占的宽度
const float hX = static_cast<float>(maxX-minX)/nIni;
//lNodes中存储生成的树结点
list<ExtractorNode> lNodes;
//vpIniNodes变量中存储的是结点的地址
vector<ExtractorNode*> vpIniNodes;
//vpIniNodes的大小先设置成根结点的个数
vpIniNodes.resize(nIni);
for(int i=0; i<nIni; i++)
{
ExtractorNode ni;
//四叉树是每次根据特定条件将一个结点分成四等分,四个区域左上(UL),右上(UR),
//左下(BL),右下(BR)
//左上角位置坐标
ni.UL = cv::Point2i(hX*static_cast<float>(i),0);
//右上角位置坐标
ni.UR = cv::Point2i(hX*static_cast<float>(i+1),0);
///左下角的位置坐标
ni.BL = cv::Point2i(ni.UL.x,maxY-minY);
///右下角的位置坐标
ni.BR = cv::Point2i(ni.UR.x,maxY-minY);
//vKeys的大小为在上面的这个根节点范围内总共提取的特征点的个数
ni.vKeys.reserve(vToDistributeKeys.size());
//将创建的根节点插入到list lNodes中
lNodes.push_back(ni);
////将lNodes变量中的最后存储的那个结点的地址存储到vector变量vpIniNodes中
//暂时还不知道这个变量做何用
//看都了吧vpIniNodes总是把最后插入到lNodes中的结点的地址拿走,然后要为
//该结点的vKeys成员变量内部添加属于该结点的特征点。
vpIniNodes[i] = &lNodes.back();
}
//Associate points to childs
//要一直记得vToDistributeKeys变量中存储的是该层图像中提取的特征点
//遍历在该层图像上提取的所有特征点
for(size_t i=0;i<vToDistributeKeys.size();i++)
{
const cv::KeyPoint &kp = vToDistributeKeys[i];
//将所有提取的特征点根据坐标位置将其分配到对应的根节点中去
//如果使用kinect b=v1那么所有的kp.pt.x都小于hX,所以所有的特征点都被分配到
//vpIniNodes的第0个元素中存储的结点指针所指向的空间中去了。
//到这里明白了这个四叉树的玩法了
//定义一个list变量,用来存储生成的树节点本身
//定义一个vector变量,用来存储结点的指针,这个指针可以指向该结点区域被分配的特征点的内存
//list是一个双向链表容器,可高效地进行插入删除元素
//vector是将元素置于一个动态数组中,vector可以随机存取元素,在头尾插入数据快,但是从中
//间插入数据很慢
//正是利用了list和vector的特点,使得我们即可以快速高效的插入删除结点,又可以随机的存取
//被分配到某一个结点区域的的特征点
//如何将这个list和vector联系起来共同维护这个四叉树呢?
vpIniNodes[kp.pt.x/hX]->vKeys.push_back(kp);
}
list<ExtractorNode>::iterator lit = lNodes.begin();
//遍历已经生成的所有节点
while(lit!=lNodes.end())
{
//如果判断在一个结点里面只有一个特征点
if(lit->vKeys.size()==1)
{
//将该结点的bNoMore属性设置为true,表示不再对这个结点进行分割
lit->bNoMore=true;
lit++;
}
//如果判断这个结点中没有被分配到任何的特征点那么就将这个结点删除
else if(lit->vKeys.empty())
lit = lNodes.erase(lit);
else
lit++;
}
//lNodes中的结点和 vpIniNodes中的结点指针是同步的,只有在 vpIniNodes中存储的结点中存储了
//特征点,才能根据特征点的数目来决定如何处理这个结点
//那如果在lNodes中删除一个没有特征点的结点,那么在 vpIniNodes中对应的这个地址也会被销毁吗?
bool bFinish = false;
int iteration = 0;
vector<pair<int,ExtractorNode*> > vSizeAndPointerToNode;
vSizeAndPointerToNode.reserve(lNodes.size()*4);
while(!bFinish)
{
iteration++;
//lNodes中已经存储的结点的数目
int prevSize = lNodes.size();
lit = lNodes.begin();
int nToExpand = 0;
vSizeAndPointerToNode.clear();
while(lit!=lNodes.end())
{
///如果结点内被分配的特征点的数目只有1个则不继续分割这个结点
if(lit->bNoMore)
{
// If node only contains one point do not subdivide and continue
lit++;
continue;
}
else
{
// 如果结点中被分配到的特征点数大于1则要继续分割
ExtractorNode n1,n2,n3,n4;
//在下面在介绍这个函数
//概括来说就是将上面这个结点分成了四个结点,并且已经完成了特征点的分配,以及特征
//个数的检测设定好每个节点的bNoMore的值
lit->DivideNode(n1,n2,n3,n4);
// Add childs if they contain points
if(n1.vKeys.size()>0)
{
//如果新分割出来的第一个结点中被分配的特征点的个数大于0那么就将这个结点
//插入到list的头部
lNodes.push_front(n1);
//如果这个心结点中被分配的特征点的个数大于1,那么接下来要被分割的结点的数目
//就得加1了
if(n1.vKeys.size()>1)
{
nToExpand++;
//变量vSizeAndPointerToNode中存储的是每一个结点的地址以及该结点中被分配到的特征点的个数。 vSizeAndPointerToNode.push_back(make_pair(n1.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
//对新分配出的第二个结点进行同上面相同的测试和操作
if(n2.vKeys.size()>0)
{
//在list的头部插入元素
lNodes.push_front(n2);
if(n2.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n2.vKeys.size(),&lNodes.front()));
//每插入一个结点就要更新list的开始结点的位置
lNodes.front().lit = lNodes.begin();
}
}
if(n3.vKeys.size()>0)
{
lNodes.push_front(n3);
if(n3.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n3.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n4.vKeys.size()>0)
{
lNodes.push_front(n4);
if(n4.vKeys.size()>1)
{
nToExpand++;
vSizeAndPointerToNode.push_back(make_pair(n4.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
lit=lNodes.erase(lit);
continue;
}
}
// Finish if there are more nodes than required features
// or all nodes contain just one point
//当创建的结点的数目比要求的特征点还要多或者,每个结点中都只有一个特征点的时候就停止分割
if((int)lNodes.size()>=N || (int)lNodes.size()==prevSize)
{
bFinish = true;
}
//如果现在生成的结点全部进行分割后生成的结点满足大于需求的特征点的数目,但是不继续分割又
//不能满足大于N的要求时
//这里为什么是乘以三,这里也正好印证了上面所说的当一个结点被分割成四个新的结点时,
//这个结点时要被删除的,其实总的结点时增加了三个
else if(((int)lNodes.size()+nToExpand*3)>N)
{
while(!bFinish)
{
prevSize = lNodes.size();
//这里将已经创建好的结点放到一个新的容器中
vector<pair<int,ExtractorNode*> > vPrevSizeAndPointerToNode = vSizeAndPointerToNode;
vSizeAndPointerToNode.clear();
//根据结点中被分配都的特征点的数目对结点进行排序
//这里为何要排序,我们想要的结果是想让尽可能多的特征点均匀的分布在图像上
//如果前面的特征分布相对均匀的结点中的特征点数目已经达到了指标那么就可以将
//后面那些分布密集的特征点去掉了。
sort(vPrevSizeAndPointerToNode.begin(),vPrevSizeAndPointerToNode.end());
for(int j=vPrevSizeAndPointerToNode.size()-1;j>=0;j--)
{
ExtractorNode n1,n2,n3,n4;
vPrevSizeAndPointerToNode[j].second->DivideNode(n1,n2,n3,n4);
// Add childs if they contain points
if(n1.vKeys.size()>0)
{
lNodes.push_front(n1);
if(n1.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n1.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n2.vKeys.size()>0)
{
lNodes.push_front(n2);
if(n2.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n2.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n3.vKeys.size()>0)
{
lNodes.push_front(n3);
if(n3.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n3.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
if(n4.vKeys.size()>0)
{
lNodes.push_front(n4);
if(n4.vKeys.size()>1)
{
vSizeAndPointerToNode.push_back(make_pair(n4.vKeys.size(),&lNodes.front()));
lNodes.front().lit = lNodes.begin();
}
}
lNodes.erase(vPrevSizeAndPointerToNode[j].second->lit);
//如果多有的结点还没有被分割完就已经达到了大于N的要求那么就直接跳出循环
if((int)lNodes.size()>=N)
break;
}
if((int)lNodes.size()>=N || (int)lNodes.size()==prevSize)
bFinish = true;
}
}
}
// Retain the best point in each node
vector<cv::KeyPoint> vResultKeys;
vResultKeys.reserve(nfeatures);
//遍历创建的所有结点
for(list<ExtractorNode>::iterator lit=lNodes.begin(); lit!=lNodes.end(); lit++)
{
//获取每个结点下的特征点
vector<cv::KeyPoint> &vNodeKeys = lit->vKeys;
cv::KeyPoint* pKP = &vNodeKeys[0];
float maxResponse = pKP->response;
//在每个结点中找到那个最强壮的特征点进行保存
for(size_t k=1;k<vNodeKeys.size();k++)
{
if(vNodeKeys[k].response>maxResponse)
{
pKP = &vNodeKeys[k];
maxResponse = vNodeKeys[k].response;
}
}
//只将每个结点下最强壮的的特征点保存
vResultKeys.push_back(*pKP);
}
return vResultKeys;
}
经过上面的操作,我们已经将图像金字塔中的某一层图像上提取的特征点优化完毕了。
//再来看看结点时如何被分割成四个新的结点的
//这个成员函数的参数是四个引用,所以函数返回值是void,C++中的引用就好比与C语言中的指针
void ExtractorNode::DivideNode(ExtractorNode &n1, ExtractorNode &n2, ExtractorNode &n3, ExtractorNode &n4)
{
//static_cast就相当于C语言中的强制类型转换
//在分割结点之前要先计算出每一个新结点的四个角点坐标
//halfX和halfY分别是已创建结点的x方向的和y方向的中间位置
const int halfX = ceil(static_cast<float>(UR.x-UL.x)/2);
const int halfY = ceil(static_cast<float>(BR.y-UL.y)/2);
//设定四个子结点的边界
n1.UL = UL;
n1.UR = cv::Point2i(UL.x+halfX,UL.y);
n1.BL = cv::Point2i(UL.x,UL.y+halfY);
n1.BR = cv::Point2i(UL.x+halfX,UL.y+halfY);
//将每个新结点的用来存储特征点的向量的capacity设置为母结点中所有的特征点的个数
n1.vKeys.reserve(vKeys.size());
n2.UL = n1.UR;
n2.UR = UR;
n2.BL = n1.BR;
n2.BR = cv::Point2i(UR.x,UL.y+halfY);
n2.vKeys.reserve(vKeys.size());
n3.UL = n1.BL;
n3.UR = n1.BR;
n3.BL = BL;
n3.BR = cv::Point2i(n1.BR.x,BL.y);
n3.vKeys.reserve(vKeys.size());
n4.UL = n3.UR;
n4.UR = n2.BR;
n4.BL = n3.BR;
n4.BR = BR;
n4.vKeys.reserve(vKeys.size());
//Associate points to childs
//根据特征点的坐标来将特征点分配到不同的新结点区域
for(size_t i=0;i<vKeys.size();i++)
{
const cv::KeyPoint &kp = vKeys[i];
if(kp.pt.x<n1.UR.x)
{
if(kp.pt.y<n1.BR.y)
n1.vKeys.push_back(kp);
else
n3.vKeys.push_back(kp);
}
else if(kp.pt.y<n1.BR.y)
n2.vKeys.push_back(kp);
else
n4.vKeys.push_back(kp);
}
//最后根据每个结点中分得的特征点的数目来设定bNoMore变量的真假
if(n1.vKeys.size()==1)
n1.bNoMore = true;
if(n2.vKeys.size()==1)
n2.bNoMore = true;
if(n3.vKeys.size()==1)
n3.bNoMore = true;
if(n4.vKeys.size()==1)
n4.bNoMore = true;
}
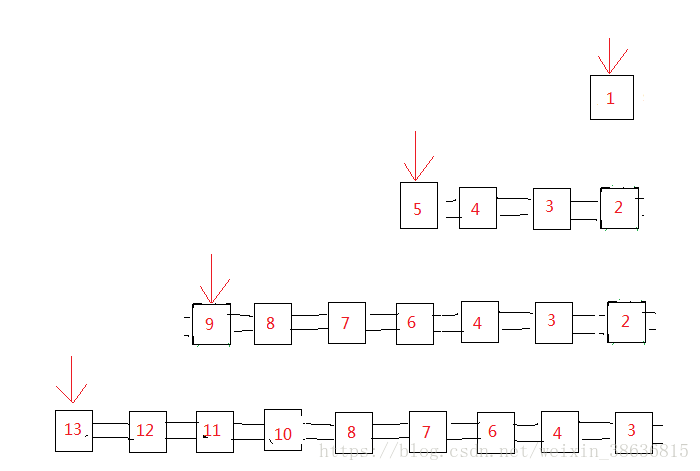
接下来捋一捋四叉树的数据模型
假设一个四叉树的形状是这样的,看看他在内存中是如何存储和管理结点的

在ORB-SLAM中是定义了一个list用来存储四叉树中的结点 std::vector<ExtractNode> lNodes;
如果一个结点满足被分割的条件那么将他新分割出来的四个结点依次从头部插入到list,每插入一个新的结点就让list的迭代器指向list中的第一个元素,四个新结点插入完毕之后将母结点删除
然后是从list头部开始依次遍历所有结点,判断哪个节点要被继续分割,如果需要继续分割则按照上面的方法完成新结点的存储和母结点的删除,因为每插入一个结点都会让迭代器指向新插入的结点,所以每次都是从list的头部开始遍历,所以刚被分割出来的结点如果满足分割条件会被紧接着继续分割,而最早生成的结点要越晚被分割。
接下来谈一谈为什么要将四叉树应用到ORB-SLAM中,听别人说是为了管理图像中提取的特征点,那这个四叉树到底在特征点的管理中起到了什么作用呢?
记得很清楚的一点是在上面的程序中,有一个环节是将创建好的结点按照结点中包含的特征点的个数从小到大来对结点进行排序,然后是优先对那些包含特征点相对较少的结点进行分割,因为结点中包含的特征点少,分割的次数也就少了,并且倘若还没有遍历完所有的结点得到的特征点的个数就已经达到了每层图像提取特征点的要求,那么就不必对那些包含特征点多的结点进行分割了,一个是分割起来费劲,再者,这个结点中包含比同等层次的结点要多的特征点,说明这里面的特征点有“集会滋事”的嫌疑, 毕竟我们希望最终得到的特征点尽可能的均匀的分布在图像中。
接下来,就要对从上面每个结点中挑选出response最大的作为这个结点的代表保留下来,我想的这样一来,万一留下的特征点的数目没有达标怎么办呢? 欲知后事如何,请听下次分晓。