【图像分类】【深度学习】【轻量级网络】【Pytorch版本】MobileNets_V2模型算法详解
文章目录
前言
MobileNets_V2是由谷歌公司的Sandler, Mark等人在《MobileNetV2: Inverted Residuals and Linear Bottlenecks【CVPR-2018】》【论文地址】一文中提出的带线性瓶颈的反向残差设计的改进模型,相比于普通残差模块,反向残差模块则是中间维度大,两边维度小,保证精度的同时显著减少所需的操作数量和内存,适用于嵌入式移动设备。
MobleNet_V2讲解
MobleNet_V1网络【参考】结构虽然轻盈,但是只是单纯地使用卷积层进行堆叠,没有引入类似于ResNet【参考】的shortcut连接,因此没有充分利用图像的信息,所以其准确率表现不佳;并且论文中提到,在实际使用中,发现深度可分离卷积的某些卷积核参数为0,部分卷积核在训练过程中失效了。
深度可分离卷积(Depthwise Separable Convolution) 结构中的深度卷积层(Depthwise Convolutional) 的卷积核数量取决于上一层的通道数,MobleNet_V1训练得到的很多无效的卷积核,因此,MobleNet_V2在深度卷积层前添加了一层 点卷积(Pointwise Convolution) 进行升维,再通过深度卷积进行卷积,最后通过点卷积进行降维,变成了一个两端细,中间粗的结构,弥补了MobleNet_V1中训练不足导致卷积核失效的情况。
反向残差结构(Inverted Residuals)
ResNet中证明残差结构(Residuals) 有助于构建更深的网络从而提高精度,MobileNetV2中以ResNet的残差结构为基础进行优化,提出了反向残差(Inverted Residuals) 的概念。
深度卷积层提取特征限制于输入特征维度,若采用普通残差块会将输入特征图压缩,深度卷积提取的特征会更少,MobileNets_V2将输入特征图扩张,丰富特征数量,进而提高精度。
普通残差结构的过程:高维输入->1x1卷积(降维)–>relu激活–>3x3卷积(低维)–>relu激活–>1x1卷积(升维)->残差相加->relu激活。

反向残差结构的过程: 低维输入->1x1点卷积(升维)-> relu激活->3x3深度卷积(低维)->relu激活->1x1点卷积(降维)->与残差相加。
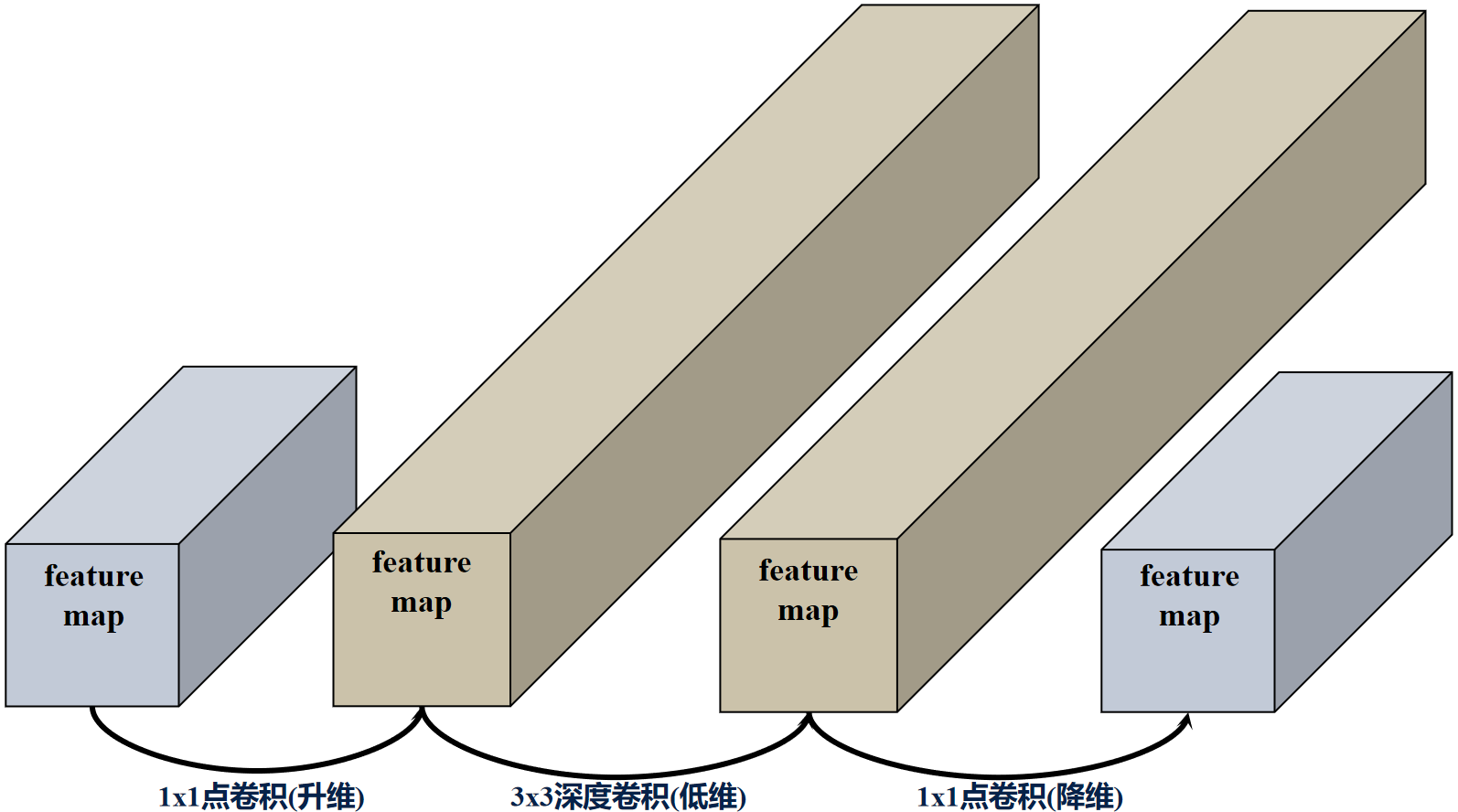
论文中MobileNets_V2的反向残差结构如下图所示:

t代表膨胀比(通道扩展系数),K代表输入维度,K’输出维度,s代表步长。
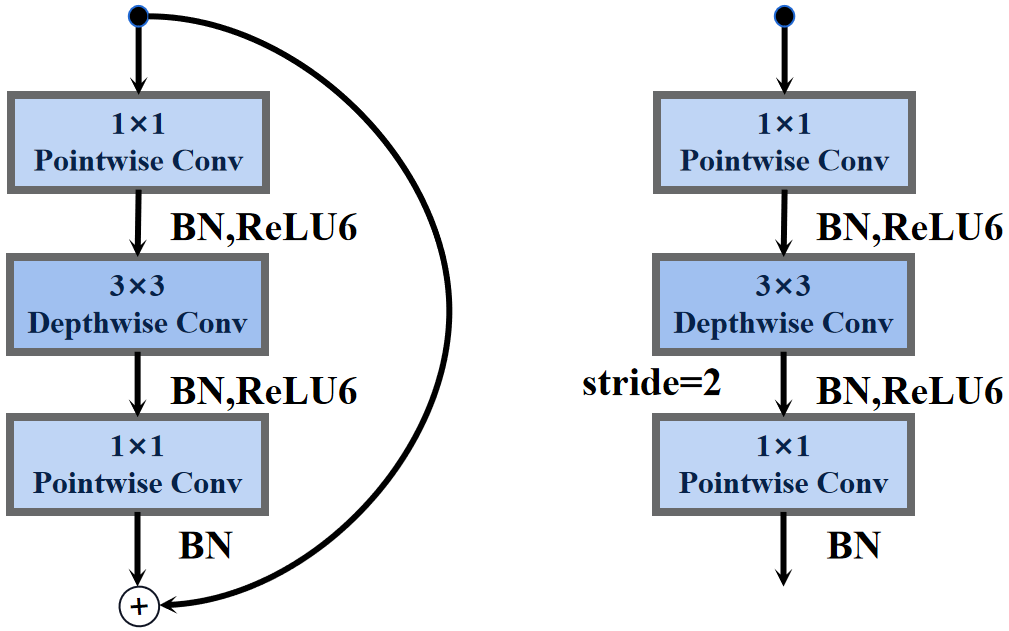
MobileNets_V2的反向残差结构分为俩种,当stride=2时,反向残差结构取消了shortcut连接。
兴趣流形(Manifold of interest)
这个部分还是有点意思的,理解后也不难,博主根据论文和其他资料尽量简单的给出了个人见解
兴趣流形是指在特征空间(特征图)中,与特定任务或概念相关的数据样本的聚集区域。它是数据样本在特征空间中的分布结构,其中包含了与任务相关的有用信息,兴趣流形可以理解为数据在特征空间中形成的低维嵌入结构。具体来说,卷积层的所有独立的通道输出的特征图的像素值,这些像素值中编码的信息实际上位于某个流形中,而流形又可嵌入到低维子空间(部分特征图)中,这是因为并不是每一个像素对于表征输入图像而言都是不可或缺的,可能只有一部分像素,就足够表征这些输入图像在该层的某种感兴趣信息。
简单来说就是兴趣流形就是指输出特征图中与任务相关的部分特征图的部分特征像素值的总和。
这就会有产生一种直觉,可以通过减小卷积层的维数来减小特征空间的维数,因为兴趣流形只占特征空间的一部分,希望尽可能的减少其余无关的特征空间。根据这种直觉,MobileNets_V1通过不断降低特征空间的维度直到流形充满整个空间,来达到压缩模型的目的。
但是卷积神经网络中特征空间是需要经过非线性激活层(relu),也就是降低的是激活特征空间的维度,因此兴趣流形并没有不断聚合而充满整个特征空间,而是丢失了一部分兴趣流形,从而导致模型的检测准确率降低。
特征空间经过非线性变换ReLU激活会导致为负的输入全部变为零,导致失去保存的信息,当ReLU使得某一个输入通道崩塌时(这个通道中有很多特征像素值都变成了负值),就会使当前通道丢失很多信息,但是如果有很多卷积核,也就是生成了很多通道,那么在当前通道丢失的信息就会有可能在其他通道找回来,如下图展示了嵌入在高维空间中的低维兴趣流形经过ReLU激活的情况。

线性瓶颈层(Linear Bottlenecks)
线性瓶颈层的主要作用是通过降低维度来提取数据的主要特征,从而减少计算量和模型复杂度,同时保持输入数据的重要信息,通常由一个线性变换操作组成,例如全连接层或卷积层,其输出维度远小于输入维度,并且不引入非线性变换。假设兴趣流形是低维的,插入线性瓶颈层可以防止非线性破坏太多信息,因为线性瓶颈层使用线性层而非ReLU激活层。因此在反向残差结构的1×1点卷积降维后并没有ReLU激活层。
很多论文证明在残差块相加之前不做非线性激活会使得检测的准确率提高,读者可以去看resnet的残差结构其实最后一层也是线性瓶颈层,是在残差块相加之后才做的非线性激活。
MobleNet_V2模型结构
下图是原论文给出的关于MobleNet_V2模型结构的详细示意图:

t是通道扩展系数;c是通道数; n是组成员数;s是步长。
MobileNets_V2在图像分类中分为两部分:backbone部分: 主要由普通卷积层、反残差结构组成,分类器部分:由池化层(汇聚层)和1×1卷积层(全连接)层组成 。
在分类任务中,分类器的1×1卷积层作用等价于全连接层,因此很多demo就用全连接代替1×1卷积层的作用了
MobleNet_V2 Pytorch代码
普通卷积块: 3×3卷积层+BN层+ReLU6激活函数
# 普通卷积块
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
# 保持输入输出特征图尺寸一致的padding
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
反向残差结构: 1×1点卷积层+BN层+ReLU6激活函数+3×3深度卷积层+BN层+ReLU6激活函数+1×1点卷积层+BN层
# 反向残差结构
class InvertedResidual(nn.Module):
# expand_ratio是膨胀率
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
# 升维后的维度
hidden_channel = in_channel * expand_ratio
# 特征图形状保持一致才能shortcut
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv 维度数==组数
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
# 特征图形状保持一致
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
完整代码
from torch import nn
import torch
from torchsummary import summary
def _make_divisible(ch, divisor=8, min_ch=None):
if min_ch is None:
min_ch = divisor
'''
int(ch + divisor / 2) // divisor * divisor)
目的是为了让new_ch是divisor的整数倍
类似于四舍五入:ch超过divisor的一半则加1保留;不满一半则归零舍弃
'''
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# 假设new_ch小于ch的0.9倍,则再加divisor
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
# 卷积组: Conv2d+BV+ReLU6
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
# 保持输入输出特征图尺寸一致的padding
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
# 反向残差结构
class InvertedResidual(nn.Module):
# expand_ratio是膨胀率
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
# 升维后的维度
hidden_channel = in_channel * expand_ratio
# 特征图形状保持一致才能shortcut
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv 维度数==组数
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
# 特征图形状保持一致
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
# 反残差结构
block = InvertedResidual
# alpha控制网络通道数
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
'''
网络配置参数:
t是通道扩展系数
c是通道数
n是组成员数
s是步长
'''
inverted_residual_setting = [
# t, c, n, s
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# 用反残差结构搭建网络
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
# 每个反残差模块组的第一个反残差块的stride根据指定要求s设置,其余的默认都是1
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
features.append(ConvBNReLU(input_channel, last_channel, 1))
self.features = nn.Sequential(*features)
# 构建分类器
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# 权重初始化
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
# mobilenetV2 1.0为例
# N x 3 x 224 x 224
x = self.features(x)
# N x 1280 x 7 x 7
x = self.avgpool(x)
# N x 1280 x 1 x 1
x = torch.flatten(x, 1)
# N x 1280
x = self.classifier(x)
# N x 100
return x
# mobilenetV2 0.25
def MobileNetV2x25():
return MobileNetV2(alpha=0.25, round_nearest=8)
# mobilenetV2 0.50
def MobileNetV2x50():
return MobileNetV2(alpha=0.5, round_nearest=8)
# mobilenetV2 0.75
def MobileNetV2x75():
return MobileNetV2(alpha=0.75, round_nearest=8)
# mobilenetV2 1.00
def MobileNetV2x100():
return MobileNetV2(alpha=1.0, round_nearest=8)
if __name__ == '__main__':
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = MobileNetV2x100().to(device)
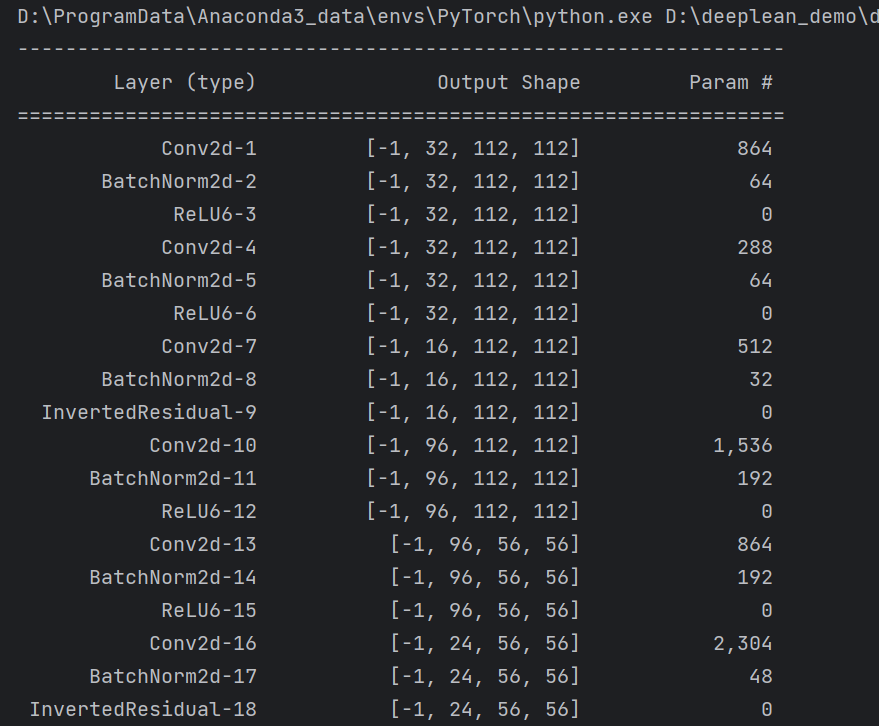
summary(model, input_size=(3, 224, 224))
summary可以打印网络结构和参数,方便查看搭建好的网络结构。
总结
尽可能简单、详细的介绍了反残差结构的原理和卷积过程,讲解了MobileNets_V2模型的结构和pytorch代码。