【题目描述】题目地址
设有 n个活动的集合 E={1,2,..,n}E=\{1,2,..,n\}E={1,2,..,n},其中每个活动都要求使用同一资源,如演讲会场等,而在同一时间内只有一个活动能使用这一资源。每个活动 iii 都有一个要求使用该资源的起始时间 sis_isi 和一个结束时间 fif_ifi,且 si<fis_i<f_isi<fi。如果选择了活动 iii ,则它在时间区间 [si,fi)[s_i,f_i)[si,fi) 内占用资源。若区间 [si,fi)[s_i,f_i)[si,fi) 与区间 [sj,fj)[s_j,f_j)[sj,fj) 不相交,则称活动 iii 与活动 jjj 是相容的。也就是说,当 fi≤sjf_i \leq s_jfi≤sj 或 fj≤sif_j \leq s_ifj≤si 时,活动 iii 与活动 jjj 相容。选择出由互相兼容的活动组成的最大集合。
【输入格式】
第一行一个整数 n;
接下来的 n 行,每行两个整数 si 和 fi。
【输出格式】
输出互相兼容的最大活动个数。
【样例输入】
4
1 3
4 6
2 5
1 7【样例输出】
2【数据范围与提示】
1≤n≤10001 \leq n \leq 10001≤n≤1000
【介绍一个好东西:贪心算法】
贪心算法(又称贪婪算法)是指,在对问题求解时,总是做出在当前看来是最好的选择。也就是说,不从整体最优上加以考虑,他所做出的是在某种意义上的局部最优解。
贪心算法不是对所有问题都能得到整体最优解,关键是贪心策略的选择,选择的贪心策略必须具备无后效性,即某个状态以前的过程不会影响以后的状态,只与当前状态有关。
【算法思路】
【思想】
贪心算法的基本思路是从问题的某一个初始解出发一步一步地进行,根据某个优化测度,每一步都要确保能获得局部最优解。每一步只考虑一个数据,他的选取应该满足局部优化的条件。若下一个数据和部分最优解连在一起不再是可行解时,就不把该数据添加到部分解中,直到把所有数据枚举完,或者不能再添加算法停止 [3] 。
-
建立数学模型来描述问题;
-
把求解的问题分成若干个子问题;
-
对每一子问题求解,得到子问题的局部最优解;
-
把子问题的解局部最优解合成原来解问题的一个解。
【算法特性】
贪婪算法可解决的问题通常大部分都有如下的特性:
-
随着算法的进行,将积累起其它两个集合:一个包含已经被考虑过并被选出的候选对象,另一个包含已经被考虑过但被丢弃的候选对象。
-
有一个函数来检查一个候选对象的集合是否提供了问题的解答。该函数不考虑此时的解决方法是否最优。
-
还有一个函数检查是否一个候选对象的集合是可行的,也即是否可能往该集合上添加更多的候选对象以获得一个解。和上一个函数一样,此时不考虑解决方法的最优性。
-
选择函数可以指出哪一个剩余的候选对象最有希望构成问题的解。
-
最后,目标函数给出解的值。
-
为了解决问题,需要寻找一个构成解的候选对象集合,它可以优化目标函数,贪婪算法一步一步的进行。起初,算法选出的候选对象的集合为空。接下来的每一步中,根据选择函数,算法从剩余候选对象中选出最有希望构成解的对象。如果集合中加上该对象后不可行,那么该对象就被丢弃并不再考虑;否则就加到集合里。每一次都扩充集合,并检查该集合是否构成解。如果贪婪算法正确工作,那么找到的第一个解通常是最优的。
【例题分析】
背包问题
有一个背包,背包容量是M=150kg。有7个物品,物品不可以分割成任意大小。要求尽可能让装入背包中的物品总价值最大,但不能超过总容量。
物品 A B C D E F G
重量 35kg 30kg 6kg 50kg 40kg 10kg 25kg
价值 10$ 40$ 30$ 50$ 35$ 40$ 30$
分析:目标函数:∑pi最大
约束条件是装入的物品总重量不超过背包容量:∑wi<=M(M=150)
⑴根据贪心的策略,每次挑选价值最大的物品装入背包,得到的结果是否最优?
⑵每次挑选所占重量最小的物品装入是否能得到最优解?
⑶每次选取单位重量价值最大的物品,成为解本题的策略。
值得注意的是,贪心算法并不是完全不可以使用,贪心策略一旦经过证明成立后,它就是一种高效的算法。
贪心算法还是很常见的算法之一,这是由于它简单易行,构造贪心策略不是很困难。
可惜的是,它需要证明后才能真正运用到题目的算法中。
一般来说,贪心算法的证明围绕着:整个问题的最优解一定由在贪心策略中存在的子问题的最优解得来的。
对于例题中的3种贪心策略,都是无法成立(无法被证明)的,解释如下:
⑴贪心策略:选取价值最大者。
反例:
W=30
物品:A B C
重量:28 12 12
价值:30 20 20
根据策略,首先选取物品A,接下来就无法再选取了,可是,选取B、C则更好。
⑵贪心策略:选取重量最小。它的反例与第一种策略的反例差不多。
⑶贪心策略:选取单位重量价值最大的物品。
反例:
W=30
物品:A B C
重量:28 20 10
价值:28 20 10
根据策略,三种物品单位重量价值一样,程序无法依据现有策略作出判断,如果选择A,则答案错误。
【注意:如果物品可以分割为任意大小,那么策略3可得最优解】
对于选取单位重量价值最大的物品这个策略,可以再加一条优化的规则:对于单位重量价值一样的,则优先选择重量小的!这样,上面的反例就解决了。
但是,如果题目是如下所示,这个策略就也不行了。
W=40
物品:A B C
重量:25 20 15
价值:25 20 15
附:本题是个DP问题,用贪心法并不一定可以求得最优解,以后了解了动态规划算法后本题就有了新的解法。
【备注】
贪心算法当然也有正确的时候。求最小生成树的Prim算法和Kruskal算法都是漂亮的贪心算法。
贪心法的应用算法有Dijkstra的单源最短路径和Chvatal的贪心集合覆盖启发式
所以需要说明的是,贪心算法可以与随机化算法一起使用,具体的例子就不再多举了。其实很多的智能算法(也叫启发式算法),本质上就是贪心算法和随机化算法结合——这样的算法结果虽然也是局部最优解,但是比单纯的贪心算法更靠近了最优解。例如遗传算法,模拟退火算法。
【应用】
如把3/7和13/23分别化为三个单位分数的和
【贪心算法】
设a、b为互质正整数,a<b 分数a/b 可用以下的步骤分解成若干个单位分数之和:
步骤一: 用b 除以a,得商数q1 及余数r1。(r1=b - a*q1)
步骤二:把a/b 记作:a/b=1/(q1+1)+(a-r1)/b(q1+1)
步骤三:重复步骤2,直到分解完毕
3/7=1/3+2/21=1/3+1/11+1/231
13/23=1/2+3/46=1/2+1/16+1/368
以上其实是数学家斐波那契提出的一种求解埃及分数的贪心算法,准确的算法表述应该是这样的:
设某个真分数的分子为a,分母为b;把b除以a的商部分加1后的值作为埃及分数的某一个分母c;将a乘以c再减去b,作为新的a;将b乘以c,得到新的b;如果a大于1且能整除b,则最后一个分母为b/a;算法结束;或者,如果a等于1,则,最后一个分母为b;算法结束;否则重复上面的步骤。
备注:事实上,后面判断a是否大于1和a是否等于1的两个判断可以合在一起,及判断b%a是否等于0,最后一个分母为b/a,显然是正确的。
【再来一波】
贪心算法
贪心算法简介:
贪心算法是指:在每一步求解的步骤中,它要求“贪婪”的选择最佳操作,并希望通过一系列的最优选择,能够产生一个问题的(全局的)最优解。
贪心算法每一步必须满足一下条件:
1、可行的:即它必须满足问题的约束。
2、局部最优:他是当前步骤中所有可行选择中最佳的局部选择。
3、不可取消:即选择一旦做出,在算法的后面步骤就不可改变了。
贪心算法案例:
1.活动选择问题
这是《算法导论》上的例子,也是一个非常经典的问题。有n个需要在同一天使用同一个教室的活动a1,a2,…,an,教室同一时刻只能由一个活动使用。每个活动ai都有一个开始时间si和结束时间fi 。一旦被选择后,活动ai就占据半开时间区间[si,fi)。如果[si,fi]和[sj,fj]互不重叠,ai和aj两个活动就可以被安排在这一天。该问题就是要安排这些活动使得尽量多的活动能不冲突的举行。例如下图所示的活动集合S,其中各项活动按照结束时间单调递增排序。
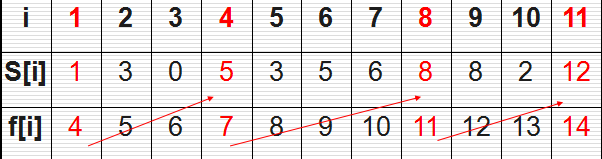
用贪心法的话思想很简单:活动越早结束,剩余的时间是不是越多?那我就早最早结束的那个活动,找到后在剩下的活动中再找最早结束的不就得了?
虽然贪心算法的思想简单,但是贪心法不保证能得到问题的最优解,如果得不到最优解,那就不是我们想要的东西了,所以我们现在要证明的是在这个问题中,用贪心法能得到最优解。
【那么介绍完贪心算法,看回题目】
思路:这道题的思路还是蛮清楚的,就是有一个开始时间Xmin和结束时间Xmax,将这两个连成线,在这里尽可能找出多的不重复的线段,成为最后的解,这道题就是典型的贪心,每次都选择最早的结束时间,一直循环下去,直到最后一个结束点,其实就是一直考虑自己的最优下一步,而不去考虑全局的下一步。但是要注意,因为是一直找最小的结束时间,所以我们可以想到要排序,那么又因为开始时间和结束时间是紧紧相连的,所以我们只能用结构体排序,然后接下来看代码。
【代码实现:在代码里面解释的很清楚了】
#include<cstdio>
#include<cstring>
#include<algorithm>
using namespace std;
struct node
{
int x,y;
}a[1005];
/*用结构体排序,使得x和y同步,如果是用数组排就会出现一些毛病,就是两个分开排的时候会有错误,比如说
x y 按数组 x y x y 按结构体 x y
2 4 排序之后 1 1 2 4 排序之后 3 1
3 1 2 2 3 1 这里的 4 2
4 2 3 3 那么明显 4 2 结构体 1 3 那么这样就是一一对应
1 3 4 4 是错误的 1 3 按y排 2 4 就一定是正确的
*/
bool cmp(node n1,node n2)
{
return n1.y<n2.y; //返回的是结束时间的升序排列
}
int main()
{
int n; scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d%d",&a[i].x,&a[i].y);//输入开始时间和结束时间
sort(a+1,a+n+1,cmp); //结构体排序
int t=a[1].y; //最小结束的时间
int ans=1; //因为从2开始枚举
for(int i=2;i<=n;i++)
{
if(a[i].x>=t) //a[i].x表示开始位置,如果开始位置在结束位置之后或者重合就成立
//否则在前面那一段里面,自然就无法进行
{
ans++; //成立就增加一种方案
t=a[i].y; //将t设为结束位置,继续循环
}
}
printf("%d\n",ans);
return 0;
}这道题对于贪心这个模块而言是一道经典的题目,也是一道算简单的题目,反正只要记住,不要考虑后果,尽情for循环就是贪心的标志了,因为贪心不求全局,只求自己开心就好。难度系数大概为3。