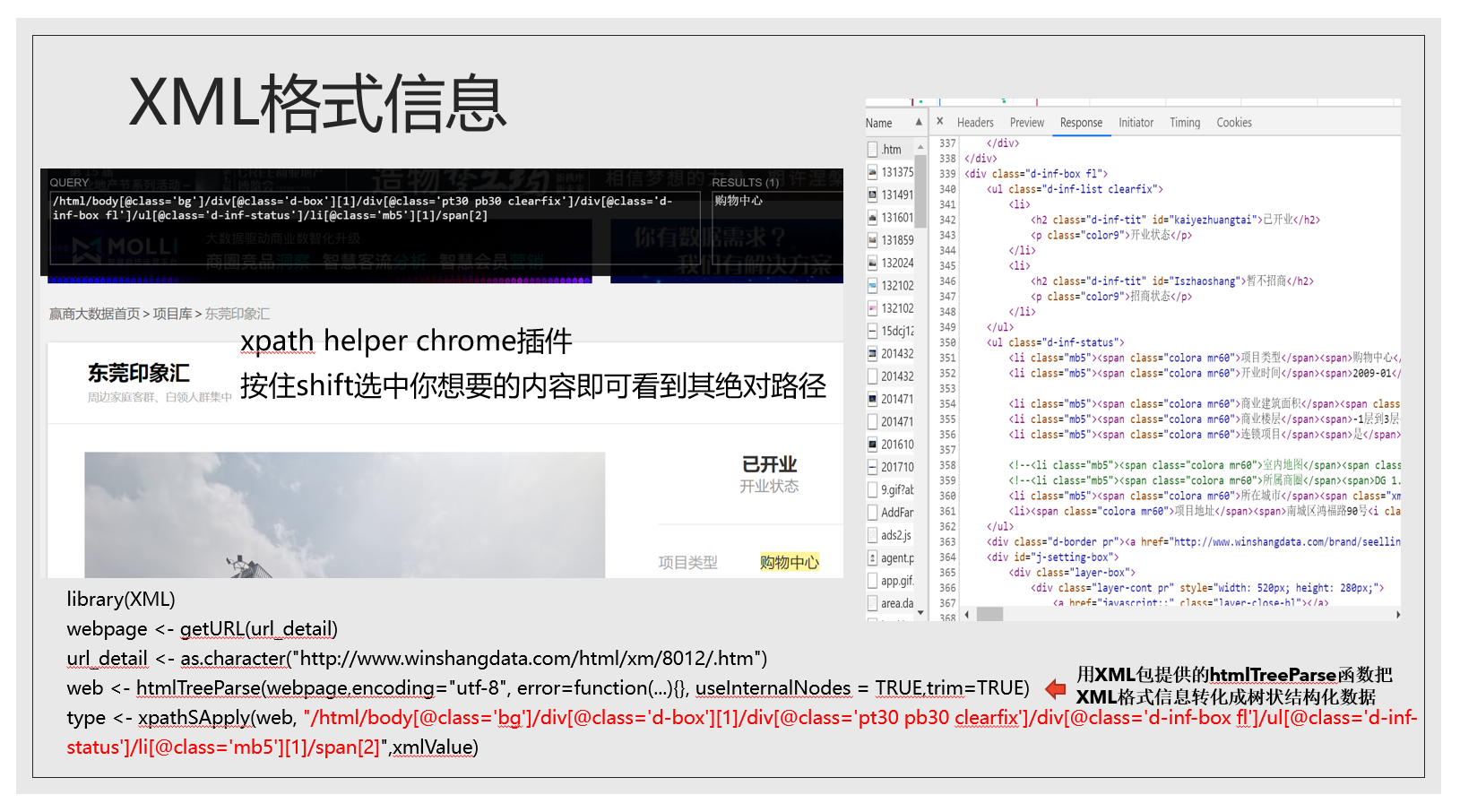
大家好,给大家做一个关于R语言爬虫的分享,很荣幸也有些惭愧,因为我是一个编程菜鸟,社团里有很多优秀的同学经验比我要丰富的多,这次分享是很初级的,适用于没有接触过爬虫且有一些编程基础的同学,内容主要有以下几个方面:背景知识,爬取方法,数据处理和存储以及我学习编程以来的经验和教训。

背景知识一:爬虫是什么
很简单,就是写一套程序,把自己伪装成一个浏览器不断地访问目标网站,批量下载下来上面的信息。

这张图是来自人民大学新闻系的官方公众号-RUC新闻坊,他们就是通过爬虫获取了信息,这些信息经过加工分析后就有了更大的价值。不过爬虫有难有易,有的网页专门开辟API接口直接为你提供你需要的信息,比如图片里的清博大数据;有的网页没有,比如图片里的链家,需要你费很大功夫把真正包含你需要的信息的网页找到。之后我会介绍如何应对这两种情况。
我们首先应对较难的情况,就是没有提供API接口的。我以链接为例,我们的目标就是爬下小区的经纬度。这个是访问链家小区的基本步骤

在正式爬虫之前还要了解一些关于网页的基本知识,幸运的是简单的爬虫不太需要掌握复杂的网页知识。网页由信息组成,大家只要知道我们需要从哪里找到我们要的信息以及这些信息是什么格式即可。
关于第一个问题:我们要的信息在哪里,我以链家网站为例
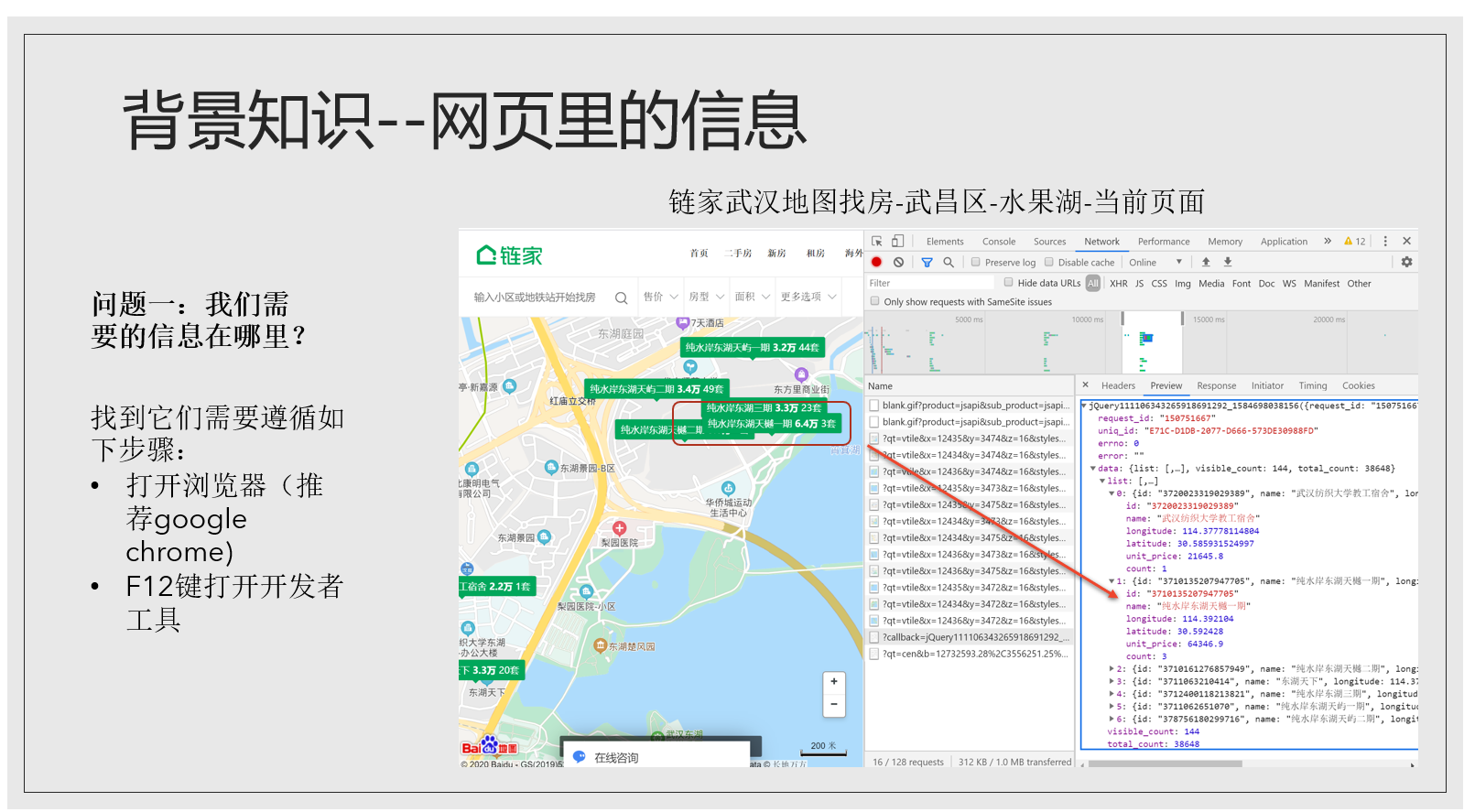
我把截图放大并标记了5个重要的位置:
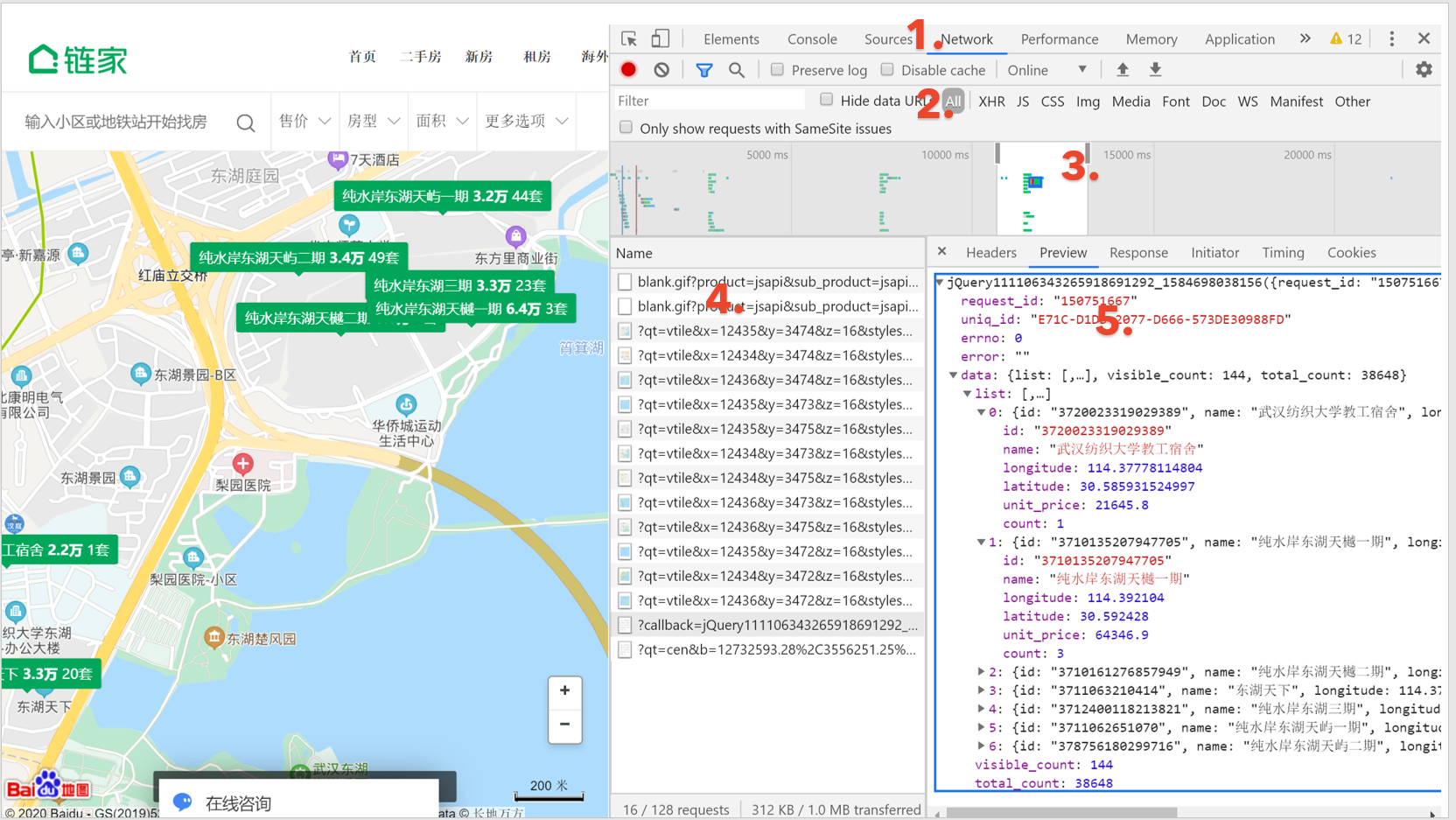
开发者工具的顶部有一些标签,1这里标记的network标签对于爬虫来说是最重要的,其它像Elements,Console等我们不太需要去看。2这里标记的是网页的数据格式标签。我这张图选的是ALL,就是包括所有的文件格式。我爬过的网站中XHR,JS,DOC格式的文件比较多。 3这里是时间轴,你的每一次点击都会显示在时间轴上,比如链家的地图有放缩的功能,每次放缩会出现新的小区信息。当你只需要某一次放缩出现的信息时,时间轴就派上用场,你可以选定那次放缩对应的时间区域,就像我图中显示的那样只有中间这一小部分时间段内的信息会出现在4所标记的信息栏里面。所以4也就顺便介绍了,可以看到4的区域里有很多文件,名字都很长,有qt开头的,也有callback开头的,这里我们需要的小区信息在callback开头的文件里。5就是文件所包含信息的展示区域。图片里选中了preview标签,也就是预览的意思,我们在这里预览了文件里的信息。
到此为止我们就回答了第一个问题:信息在哪里
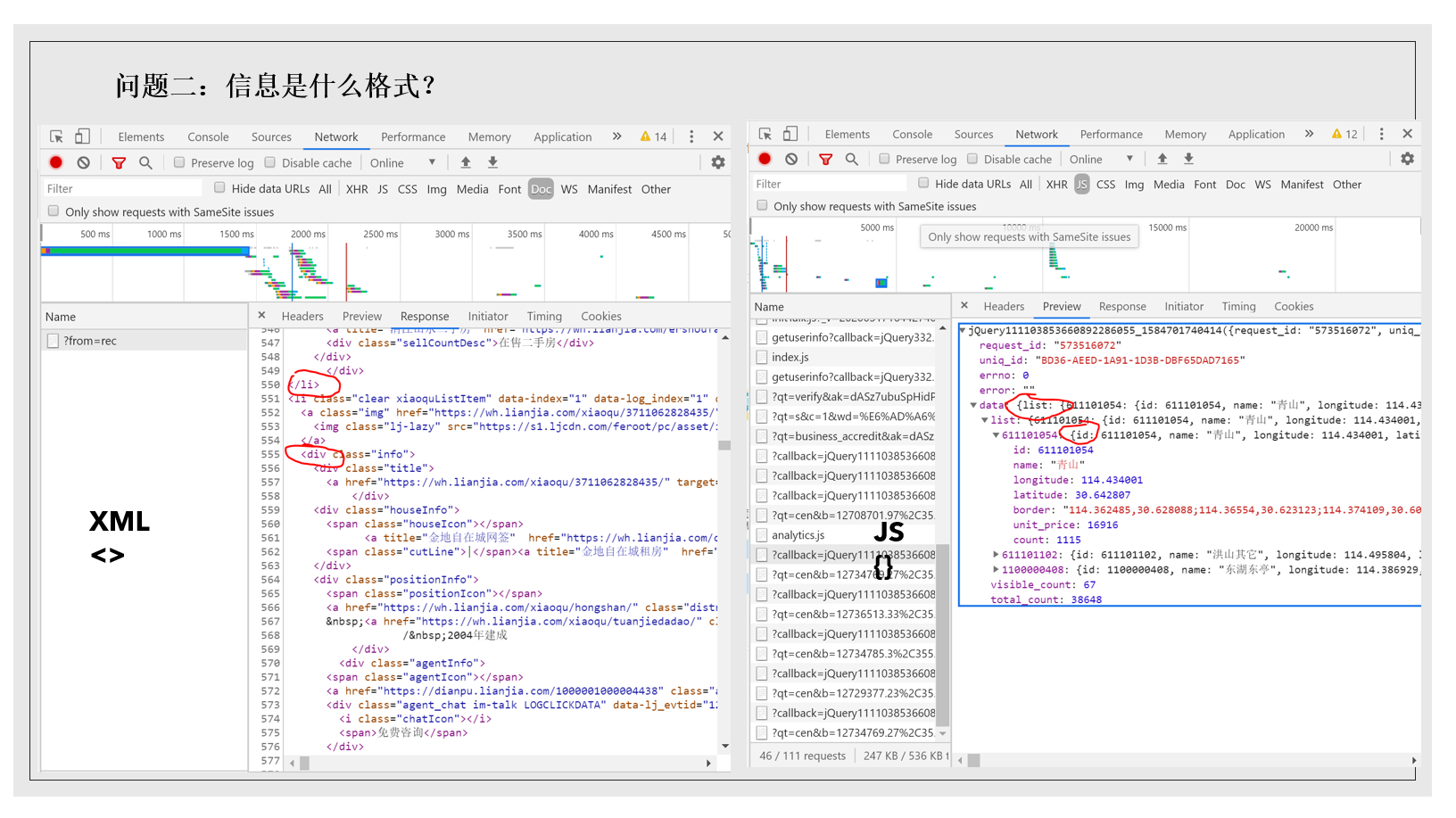
第二个问题是信息的格式。
为什么信息的格式这么重要?因为格式决定了我们处理它们的方式。有两个格式很重要:XML和JSON,下面两张图左边是XML格式,右边是JSON格式,XML呈现阶梯状,用尖括号包起来,JSON则是以花括号为标志。
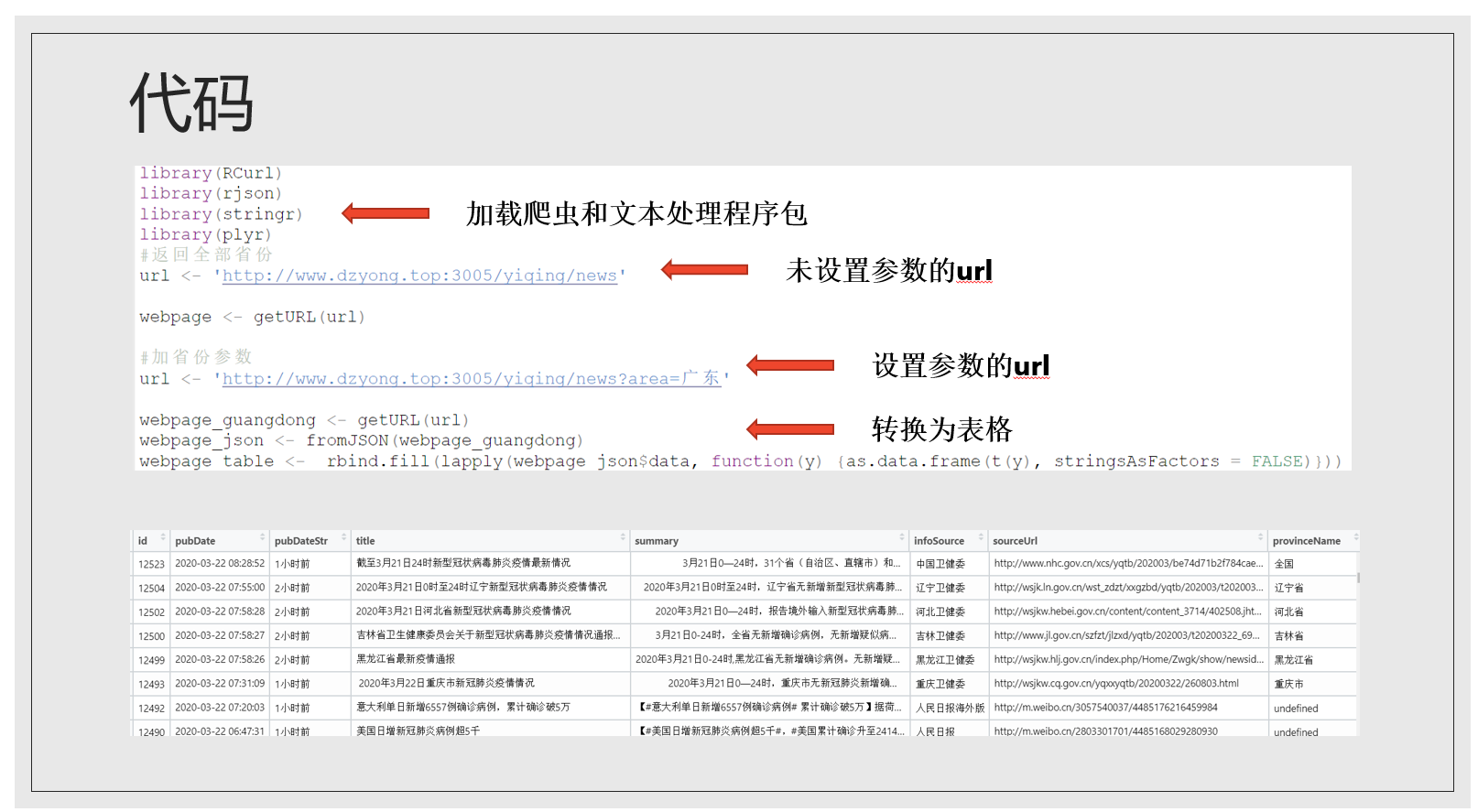
背景知识讲完就开始爬虫了。大家有的用python有的用R,R爬虫需要加载程序包,常用的有Rcurl,httr,rvest,rjson等,python我知道beautifulsoup比较有名。两种编程语言在函数语法上有区别,但爬虫的思路框架是一样的,我以R和刚才的链家网站为例。我们的目标是爬取武汉小区的经纬度。爬虫第一步是伪装成浏览器,我们在访问链家网站时首先要输入网址,然后点击地图找房-武昌区-再到武昌区里的水果湖板块,才能看到这个板块里的所有小区,如果通过程序的话,可以直接进入小区的界面,但前提是找到小区界面所在的网址,它和浏览器地址栏里的大网址已经不一样了。在前面我们找到了小区信息所在的文件,所以关键就是找到这个文件所在的网址。大家看到这时ppt上的这张图的network标签已经切换成headers标签,headers标签里就有这个callback文件的网址。

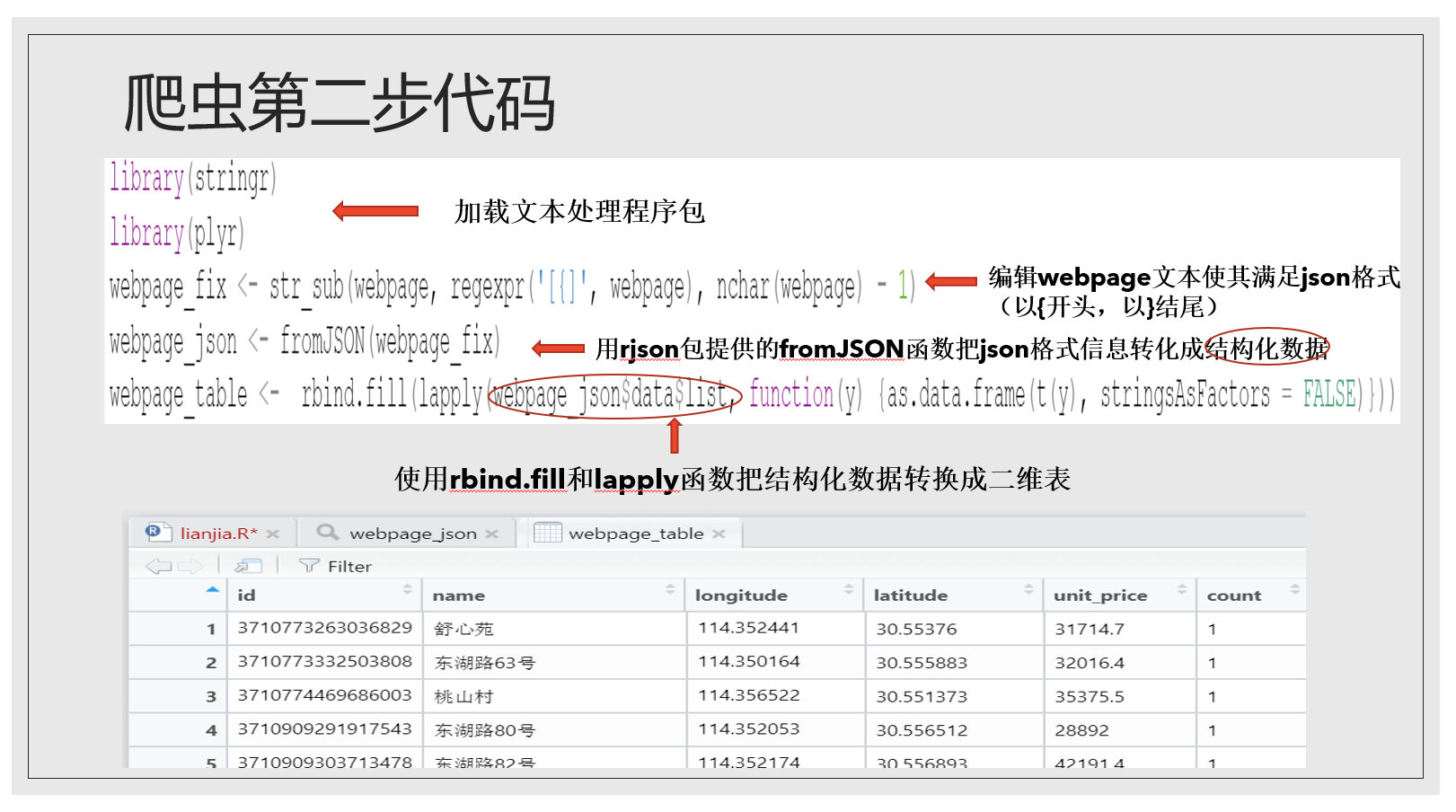
下面是伪装成浏览器部分的代码。
getURL就是请求网页信息的函数,它使用了我们上面提供的URL和request headers获取了callback文件里的小区信息并把它传递到webpage这个变量中。

这就是webpage里的信息,非常眼花缭乱,可以看到我们要的经纬度、小区名都在里面,我们想把它整理成清晰的形式,就像下面这个二维表。怎么做?

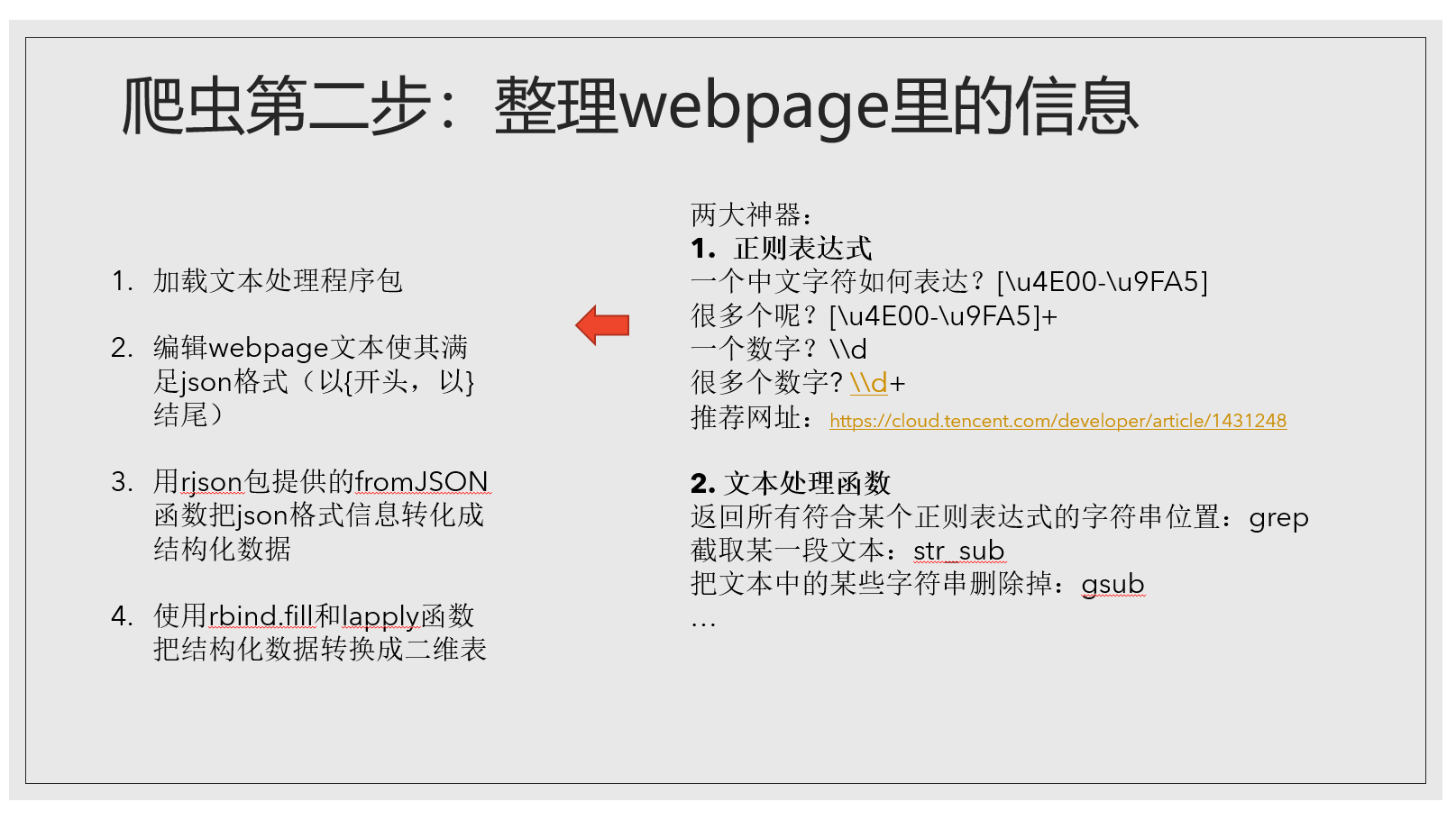
这里文本处理程序闪亮登场!
文本处理里大家需要了解正则表达式和一些基本的文本处理函数。学习R语言的文本处理强烈推荐这个网址的文章,讲得很清晰。我只列举了几个正则表达式和函数,如果大家感兴趣想多了解一些可以看那个文章。整理webpage信息的步骤我列举了出来…
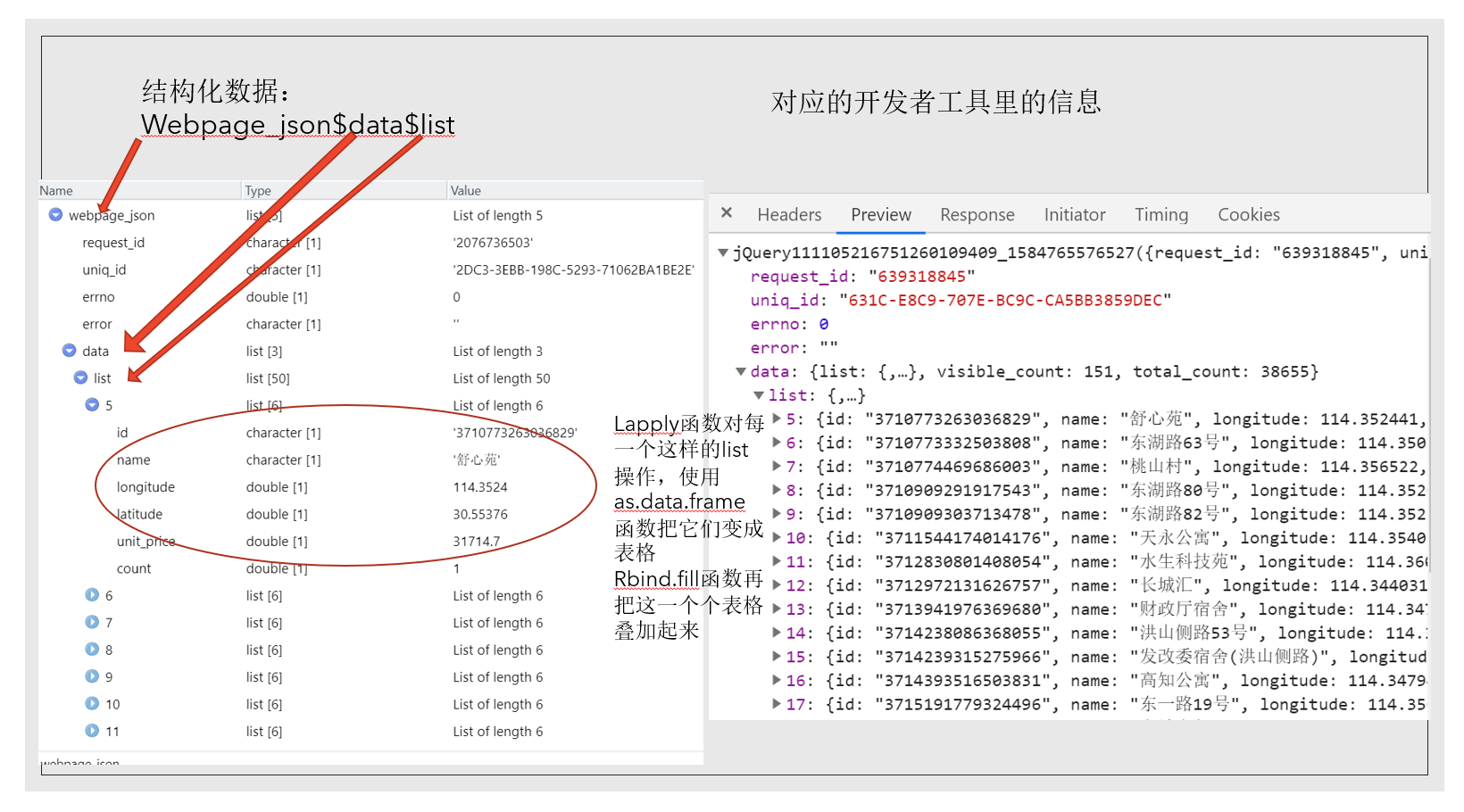
到此为止我们已经爬取下来武昌区水果湖板块的部分小区信息,链家的例子就暂且讲解到这里。目前我们只将了使用GET方式处理JSON格式信息的情况,但还有post方式和XML格式信息的情况没有讲,我这里只把部分代码放在这里,感兴趣的同学可以了解一下。
下面再看API的例子,许多个人、政府机构等都为新冠肺炎开发了API数据接口,政府如山东省、贵州省都有数据开放平台,还有之前的清博大数据都是需要注册账号申请接入的,比较麻烦,所以我这里就以一个个人开发的接口为例。访问这个网站,可以看到它特地标注了是GET请求,我们刚刚爬取链家数据也是get请求。
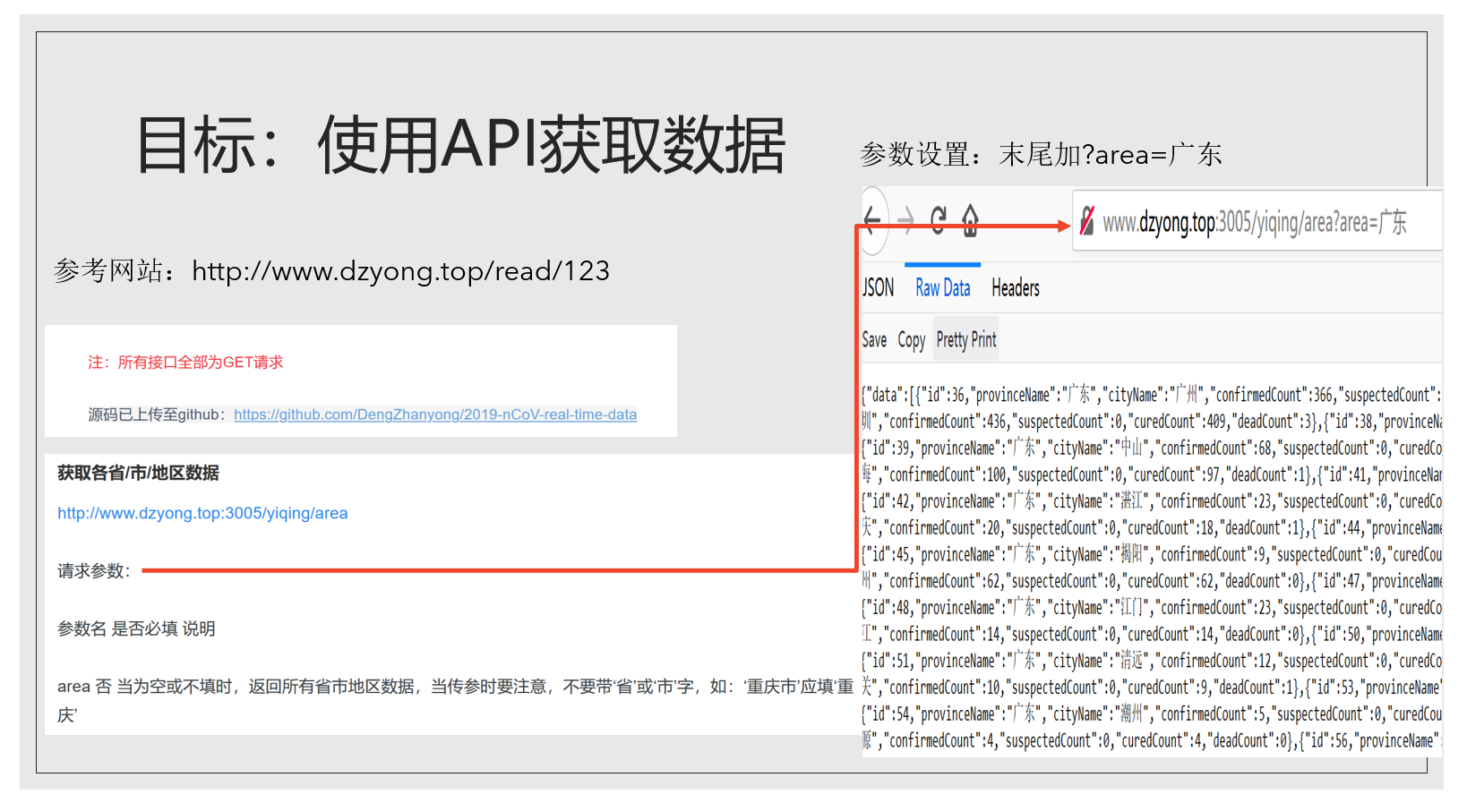
post请求和XML格式我就不细讲了。