结构体内存对齐
什么是结构体内存对齐
结构体不像数组,结构体中可以存放不同类型的数据,它的大小也不是简单的各个数据成员大小之和,限于读取内存的要求,而是每个成员在内存中的存储都要按照一定偏移量来存储,根据类型的不同,每个成员都要按照一定的对齐数进行对齐存储,最后整个结构体的大小也要按照一定的对齐数进行对齐。
对齐规则:
- 第一个成员在与结构体变量偏移量为0的地址
- 其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。
- 对齐数=编译器默认的一个对齐数 与 该成员大小的较小值。
- linux 中默认为4
- vs 中的默认值为8
- 结构体总大小为最大对齐数的整数倍(每个成员变量除了第一个成员都有一个对齐数)
如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐数的整数倍,结构体的整体大小就是所有最大对齐数的整数倍(含嵌套结构体的对齐数)
特点
每个成员的偏移量%自己的对齐数=0;
结构体整体大小%所有成员最大对齐数=0;
结构体的对齐数是自己内部成员的对齐数中的最大对齐数
举例说明
//平台VS2013下(默认对齐数为8)
//练习一
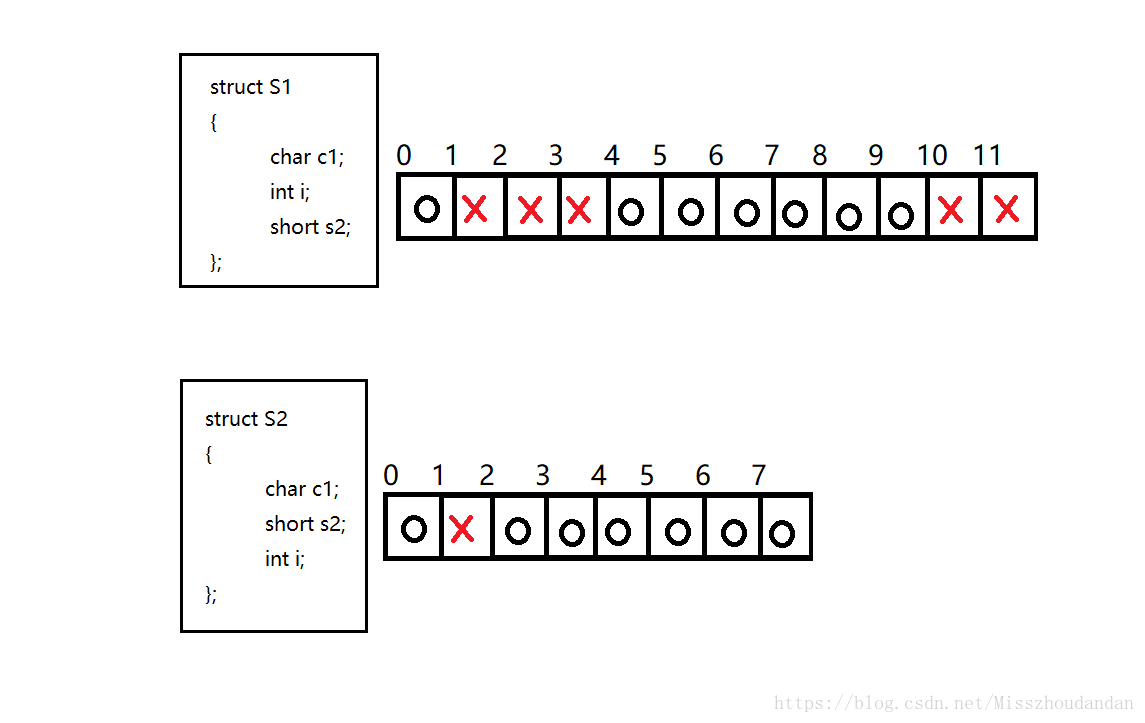
struct S1
{
char c1;
int i;
short s2;
};
printf("%d\n", sizeof(struct S1));//12
//练习二
struct S2
{
char c1;
short s2;
int i;
};
printf("%d\n", sizeof(struct S2));//8案例一分析
char 类型占1个字节,编译器默认对齐数为8,则该变量对齐数为1,实际偏移量为0
int 类型占4个字节,编译器默认对其数为8,则该变量对其数位4,偏移量应该为4的倍数,实际偏移量为4
short类型占2个字节,编译器默认对齐数为8,则该变量对其数2,偏移量应该为2的倍数,实际偏移量为8
结构体整体的对齐数为所有成员的对齐数中最大的一个,对齐数为4
结构体整体大小,按照上面数据占据空间大小,计算得结构体大小10字节。
按照对其规则,应该对齐到4的倍数,实际大小为12字节
案例二分析
char 类型占1个字节,编译器默认对齐数为8,则该变量对齐数为1,实际偏移量为0
short类型占2个字节,编译器默认对齐数为8,则该变量对其数2,偏移量应该为2的倍数,实际偏移量为2
int 类型占4个字节,编译器默认对其数为8,则该变量对其数位4,偏移量应该为4的倍数,实际偏移量为4
结构体整体的对齐数为所有成员的对齐数中最大的一个,对齐数为4
结构体整体大小,按照上面数据占据空间大小,计算得结构体大小8字节。
按照对其规则,应该对齐到4的倍数,实际大小为8字节
图形分析
为什么存在内存对其
平台移植型好
不是所有的硬件平台都能访问任意地址上的数据;某些硬件平台只能只在某些地址访问某些特定类型的数据,否则抛出硬件异常,及遇到未对齐的边界直接就不进行读取数据了。
cpu处理效率高

从上图可以看出,对应两种存储方式,若CPU的读取粒度为4字节,
- 那么对于一个int 类型,若是按照内存对齐来存储,处理器只需要访存一次就可以读取完4个字节
- 若没有按照内存对其来读取,如上图所示,就需要访问内存两次才能读取出一个完整的int 类型变量
- 具体过程为,第一次拿出 4个字节,丢弃掉第一个字节,第二次拿出4个字节,丢弃最后的三个字节,然后拼凑出一个完整的 int 类型的数据。