本文将介绍以下内容:
一、什么是内存对齐?
二、结构体大小如何计算?
三、为什么存在内存对齐?
四、如何修改默认对齐数?
五、笔试题练习
正文
一、什么是内存对齐?
首先,内存对齐是属于编译器的“管辖”范围,编译器为程序中的每个数据单元安排在适当的位置上。但是在 c 语言中我们是被允许干预内存对齐的,也就是说我们可以一定程度上的控制如何内存对齐。
内存对齐是为了硬件计算起来效率更高而设计的
我们通过一些例子来理解下什么是内存对齐:(以下程序皆在vs2013下运行)
例1:
typedef struct s1
{
char a;
int b;
char c;
} s1;
printf("%d\n", sizeof(s1));
运行结果是12。
typedef struct s1
{
char a;
char b;
char c;
} s1;
printf("%d\n", sizeof(s1));
运行结果是3。
typedef struct s1
{
char a;
short b;
char c;
} s1;
printf("%d\n", sizeof(s1));
运行结果是6。
typedef struct s1
{
char a;
double b;
char c;
} s1;
printf("%d\n", sizeof(s1));
运行结果是24。
从例1直观的来看,感觉好像是低字节的元素在向高字节对齐。我们继续往下看!!!
例2:
typedef struct s2
{
char a;
char b;
int c;
} s2;
printf("%d\n", sizeof(s2));
运行结果是8。
例3:
typedef struct s3
{
double d;
char c;
int i;
} s3;
printf("%d\n", sizeof(s3));
运行结果是16。
例 2 应该是将两个 char 凑成一个4字节的 int,所以计算出来是8。
例 3 应该是将 char 和 int 凑成了一个 8字节的double,所以计算出来是16。
这看起来也是往低字节往高字节的元素对齐。那么看下一个例子!!
例4:
typedef struct s3
{
double d;
char c;
int i;
} s3;
typedef struct s4
{
char c1;
struct s3 s3;
double d;
} s4;
printf("%d\n", sizeof(s4));
运行结果是32。
注意:这里结果发生了变化,如果按照我们上面的推论,那么这个计算出来应该是往 s3 这个结构体上对齐,s3 是16个字节,那么按理应该是 48 才对,看起来这并不是无休止的往最大的字节元素对齐。那么我们就来看看结构体的大小到底应该如何计算?
二、结构体大小如何计算?
我们先来看看结构体的对齐规则:
- 第一个成员在与结构体变量偏移为 0 的地址处。
- 其他成员变量要对齐到对齐数的整数倍
对齐数 = 编译器默认的一个对齐数 与 该成员中最大的变量 两者之间较小的那个
提一下:vs中默认的对齐数是 8
Linux下默认的对齐数是 4 - 结构体总大小为最大对齐数(每一个成员变量都有一个对齐数)的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体对齐到自己的最大对齐的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
看了这些规则,我们来一条条分析:
第一条很好理解,简单来说,结构体第一个成员的地址和结构体的地址是一样的。但是意义不一样,第一个成员的地址是给结构体的地址加上一个 0 得到的就是第一个成员的地址。
主要是第二条看起来比较绕口,但是仔细分析也是很好理解,这时候可以看我们的例子,在例2中,结构体中最大的成员是 int ,而vs默认的对齐数是8,我们选两者中较小的一个作为对齐数,那么就是取 4 作为对齐数。
再看例 3 中,结构体成员最大的是 double 有 8 个字节,而vs的默认对齐数也是 8 ,所以取 8 作为对齐数。
再看例 4 中,结构体成员中最大的是结构体 s3 ,是 16 个字节,而vs默认对齐数是8,取两者较小的作为对齐数,所以就取的是 8 作为对齐数,s3 的大小还是 16 个字节,其他成员变量向 8 对齐。
三、为什么存在内存对齐?
大部分的参考资料都是这样解释的:
1、平台原因(移值原因):
不是所有的硬件平台都能访问任意地址上的任意数据的,某些硬件平台只能在某些地址处取特定类型的数据,否则抛出硬件异常。
2、性能原因:
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。
原因在于,为了访问未对齐的内存,处理器需要作出两次内存访问,而对齐的内存仅需要一次访问,也就是下面的解释。
cpu在取数据的时候一般都是 4 个字节或 8 个字节的取,如果没有内存对齐这回事那么取数据就会出现下面的情况
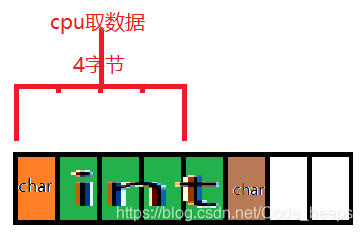
没有内存对齐的话,取出来的数据就是一个 char 和 3/4 个 int,不是一个完整的 int,为了取出一个完整的 int 还得再取一次,这样就很僵硬了。
但是当我们把 char 补成四个字节,那么每次就可以取出来完整的数据了,cpu 再去解析也就方便了很多。所以说内存对齐是为了硬件计算起来效率更高设计的。
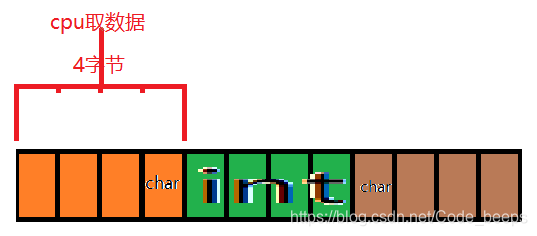
总的来说,结构体的内存对齐是用 空间 换 时间 的做法
四、如何修改默认对齐数?
借助预处理指令 #pragma pack()
#pragma pack(2) :将默认对齐数修改为2。默认对齐数一旦修改,那么结构体计算的大小也就发生了相应的变化。
#pragma pack() :取消设置的默认对齐数,还原为默认对齐数。
五、笔试题练习
提问:写一个宏,计算结构体中某变量相对于首地址的偏移,并给出说明?
答:
typedef struct s1
{
char a;
int b;
char c;
} s1;
#define OFFSET(a, b) ((char*)(&b) - (char*)(&a))
int main()
{
s1 s;
printf("成员 b 相对于首地址的偏移量为:%d\n", OFFSET(s, s.b));
system("pause");
return 0;
}
如果直接用两个指针进行相减,减出来肯定有问题,因为这里的指针是带类型的,所以我们需要将指针强转为char*进行相减,那么计算出来的就是字节数。
