前言
什么是结构体?
定义:结构体是一系列数据的集合这些数据可能描述了一个物体,也可能是对一个问题的抽象。举个栗子,简单的说,对于人,人有名字,性别,年龄,身高,体重等个人信息,那么,我们在定义这种个体的时候,就不能说它能用一个字符或整型变量来定义。 这时候,就需要结构体闪亮登场了。
结构体内存对齐:元素是按照定义顺序一个一个放到内存中去的,但并不是紧密排列的。从结构体存储的首地址开始,每个元素放置到内存中时,它都会认为内存是按照自己的大小来划分的,因此元素放置的位置一定会在自己宽度的整数倍上开始。
为什么要内存对齐?
1.平台问题(移植问题):不是所有的硬件平台都能访问任意地址上的任意数据的,某些硬件平台只能在某些地质处取某些特定类型的数据,否则跑出硬件异常。
2.性能原因:数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要做两次内存访问,而对齐的内存只需要访问一次。
设置默认对齐数
法一:
#pragma pack(value) value为指定的对齐数。
#pragma pack() 取消指定对齐,恢复缺省对齐。
#pragam pack(1)的作用:告诉编译器按照1来进行内存对齐,即没有内存对齐!
很明显#pragma pack(n)作为一个预编译指令用来设置多少个字节对齐的。值得注意的是,n的缺省数值是按照编译器自身设置,一般为8,合法的数值分别是1、2、4、8、16。即编译器只会按照1、2、4、8、16的方式分割内存。若n为其他值,是无效的。
法二:vs中按Alt+f7 自行去编译器设置
如何知道结构体某个成员相对于结构体起始位置的偏移量?
使用offsetof宏来判断结构体中成员的偏移地址。使用offsetof宏需要包含stddef.h头文件,该宏定义如下:
#define offsetof(type,menber) (size_t)&(((type*)0)->member)
巧妙之处在于将地址0强制转换为type类型的指针,从而定位到member在结构体中偏移位置,编译器认为0是一个有效的地址,从而认为0是type指针的起始地址。
结构体的内存对齐规则
1.第一个成员在结构体变量偏移量为0的地址处。
2.其他成员变量要对齐到某个数字(对齐数)的整数倍的地址处。其中对齐数 = 编译器默认的对齐数与该成员大小的较小值。vs默认是8,linux默认是4。
3.结构体总大小为最大对齐数的整数倍。
4.如果嵌套了结构体的情况,嵌套的结构体对齐到自己最大对齐数的整数倍处,结构体的整体大小就是所有最大对齐数(含嵌套结构体的对齐数)的整数倍。
例1:
struct A
{
int a;
char b;
double c;
char d;
};
解析:
在windows系统32位平台上:
int占4个字节
char占1个字节
float占4个字节
double占8个字节
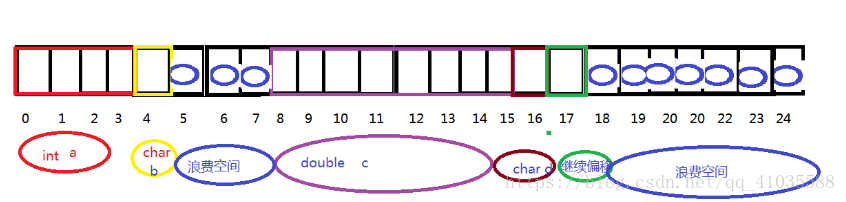
int a从0偏移开始,占四个字节,即占用0,1,2,3,现在可用偏移为4偏移,接下来存char b; 由于4是1的倍数,故而,b占用4偏移,接下来可用偏移为5偏移,接下来该存double c; 由于5不是8的倍数,所以向后偏移5,6,7,都不是8的倍数,偏移到8时,8是8的倍数,故而c从8处开始存储,占用8,9,10,11,12,13,14,15偏移,现在可用偏移为16偏移,最后该存char d ;因为16是1的倍数,故d占用16偏移,接下来在整体向后偏移一位,现处于17偏移,min(默认对齐参数,类型最大字节数)=8;因为17不是8的倍数,所以继续向后偏移18…23都不是8的倍数,到24偏移处时,24为8的整数倍,故而,该结构体大小为24个字节。
例2:
#include <stdio.h>
#include <Windows.h>
#pragma pack(8)
struct A{
int a;
char b;
double c;
};
int main()
{
printf("A:%d\n",sizeof(struct A));
system("pause");
return 0;
}
上面这道简单的结构体的大小是多少呢?有一部分人会响亮的答出:13.那么恭喜你,答错了。这道题的正确答案是16.接下来我为大家分析一下:首先我们设置的默认对齐数为8,在结构体A中,int a作为结构体的第一个成员,对齐数为0,占4个字节,char b为第二个成员,对齐数为自身大小1与默认对齐数8的较小者,则为1,1+4 = 5,是对齐数1的整数倍,合理。第三个成员的大小为8与默认对齐数8取较小者为8,则5+8=13,最后总的大小应该是结构体中最大对齐数8的整数倍,则13会补全为16.
例3:
#include <stdio.h>
#include <Windows.h>
#pragma pack(4)
struct A{
int a;
char b;
int c[10];
char *d;
};
int main()
{
printf("A:%d\n",sizeof(struct A));
system("pause");
return 0;
}
这次我们将默认对齐数设置为4,重新看一道题。在结构体A中,int a为第一个成员,对齐数为0,自身大小为4字节,不需要对齐,第二个成员为char b,对齐数为自身大小1与默认对齐数4的较小者1,4+1 = 5,5是对齐数1的整数倍,合理。第三个成员为int c[10],对齐数为自身大小40与默认对齐数4的较小者4,5+40=45,45不是对齐数4的整数倍,所以补齐到能整除4,45+3=48可以整除,最后一个成员为char *d,为一个指针,对齐数为自身大小4与默认对齐数4的较小者4,48+4=52,52可以整除最大对齐数4,则最终的答案为:52.
#include <stdio.h>
#include <Windows.h>
#pragma pack(4)
struct A{
int a;
char b;
int c[10];
char *d;
}obj;
struct B{
int a1;
char b1;
double c1;
struct A obj;
struct A *objp;
struct A objarr[2];
char *d1;
};
int main()
{
printf("A:%d\n",sizeof(struct A));
printf("B:%d\n",sizeof(struct B));
system("pause");
return 0;
}
这次我们看个稍微难点的,结构体内嵌套结构体的例子。我们设置的默认对齐数为4,所以struct A与上一个例子一样,A占52个字节。主要看struct B,首先第一个成员int a1对齐数为0,大小为4个字节,第二个成员为char b1,对齐数为自身大小1与默认对齐数4的较小者1,4+1=5,5能够整除对齐数1,合理。第三个成员为double c1,对齐数为自身大小8与默认对齐数4的较小者4,5+8=13,13不能整除对齐数4,补齐到13+3=16,。第四个成员为struct A obj,对齐数为自身大小52余默认对齐数4的较小者,16+52=68,68能够整除4,合理。第五个成员为struct Aobjp,对齐数为自身大小4与默认对齐数4的较小者4,68+4=72,72能够整除4,合理。第六个成员为struct A objarr[2],对齐数为自身大小522与默认对齐数4的较小者4,72+52*2=176,176可以整除4,合理。最后一个成员为char *d1,对齐数为自身大小4与默认对齐数4的较小者4,176+4=180,180可以整除最大对齐数4,则最终答案为:180.
为什么有大小端? 什么是大小端?如何测试某台机器是大端还是小端?应用场景?
- 为什么出现这个东西?
在各种计算机体系结构中,对于字节、字等的存储机制有所不同 - 定义:
大端存储模式:数据的低位保存在高地址中,而数据的高位保存在低地址中。
小端存储模式:数据的低位保存在低地址中,而数据的高位保存在高地址中。
在内存中,地址是从低到高依次存储的(上下,左右) - 测试方法:
1.强制转换法
//设计程序来判断当前机器的的大小端
void Check()
{
int a = 1;//int为整型4个字节,且1为小值,存在最低位
printf("%d\n", (*(char*)&a));//char*为一个字节的指针类型指向a的第一个字节的地址,(*(char*)&a)取出的是a的最低位的数字
}
//若*(char*)取出的值为1,则说明低位1就存在低地址中,为小端,否则为大端。
2.用移位运算法
void Check()
{
unsigned short a = 1;
a>>8;
printf("%d",a);
}
3.用联合
void Check()
{
union A
{
char a;
int i;
}A;
A d;
d.i = 1;
printf("%d",d.a);
}
- 应用场景
字符转换
代码移植
网络通信
(例如):
不同计算机体系之间的通信,数据对方能否正确理解?
需要双方约定,或者有规范来遵守。因为遵守TCP传输规范,可以保持通信双方开发的独立,而不必要和对方约定什么字节序的问题。双方只在通信的线路上保持数据的准确就可以了。
在通信的发起方:使用htons(windows和linux下都有这个函数)就可以转化好了,当然如果本来的机器存储就是大端的就不转换了。
在通信的接收方:依据接收时数据是大端,和自己的计算机体系来决定怎么保存这个数据。
TCP/IP 协议规范?
在网络上传输数据时,由于数据传输的两端可能对应不同的硬件平台,采用的存储字节顺序也可能不一致,因此 TCP/IP 协议规定了在网络上必须采用网络字节顺序(也就是大端模式) 。