关于结构体内存对齐的问题,最直观的体现便是在计算结构体大小的问题上。
我们来看一个例子:
#include<stdio.h>
#include<stdlib.h>
int main()
{
struct s
{
char a;
int b;
double c;
}s;
printf("%d\n", sizeof(s));
system("pause");
return 0;
}
那么在没有考虑到结构体内存对齐之前,我们的常规思路应该是直接计算每个类型的大小,即1+4+8=13。但是我们看输出结果:
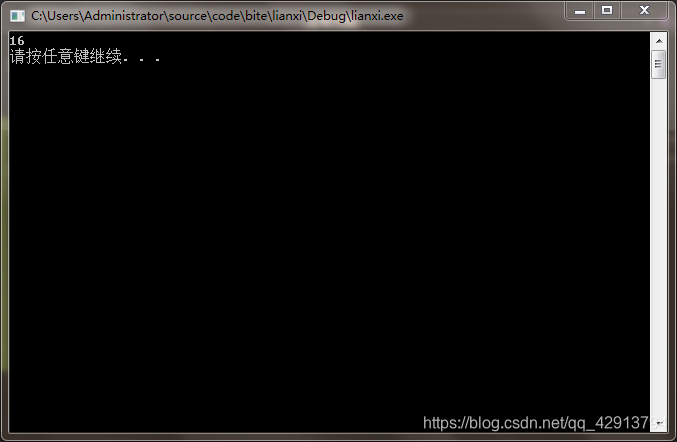
结果并不是13,而是16。为什么?
那么这就是为什么要有结构体内存对齐的原因了,我们先通过画图来剖析一下上述题目的结构体内存对齐产生的原因与过程。
我们在内存访问寻址时不能从任意处开始,所以我们在图里定义一些确定的访问位置。
如图,在无结构体内存对齐的情况下(也就是按1+4+8=13计算),cpu读取a的时候可以直接从内存里读取。而b占4个字节所以紧挨着a往下放,那么cpu第一次访问内存时要先把b在前面的3个字节读取出来,然后第二次访问时再把b的剩下的一个字节读取出来。那么cpu光把b变量读取就要访问内存两次,如果再内存中充满了巨大的变量数据,cpu就要频繁的访问内存,那么读取数据的性能就会大大下降,很大程度上耗费了时间。
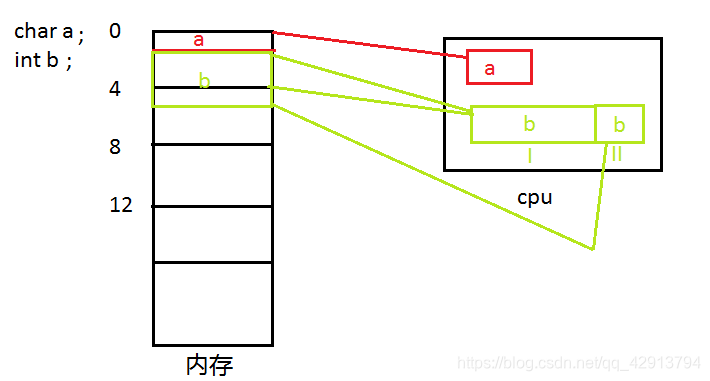
那么内存对齐出现的原因总结为如下两点:
- 平台原因(移植原因):不是所有硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
- 性能原因:数据结构(尤其是栈),应该尽可能地在自然边界上对齐。原因在于,为了未访问对齐的内存,处理器需要作两次内存访问;而对齐的内存仅需访问一次。
总的来说:结构体内存对齐的出现就是为了拿空间来换取时间
经过阅读一些书籍,我对结构体的内存对齐规则总结如下:
- 第一个成员在与结构体变量偏移量为0的地址处。如上述例子的变量a,就是从偏移量为0处开始存储。
- 其他成员要对齐到某个数字(对齐数)的整数倍的地址处。划重点:对齐是指,除了第一个变量,剩下的任何变量放入时的起始偏移量能整除对齐数。若不对齐,则让起始偏移量增加至最小能整除对齐数的数。
- 任何编译器都没有默认对齐数。
- 每一个成员都有一个对齐数(一般为该成员自身的类型大小)。
- 结构体大小为最大对齐数的整数倍。
- 如果有嵌套结构体的情况,嵌套结构体对齐到自己最大对齐数的整数倍处,结构体的整体大小就是所有所有最大对齐数(含嵌套进来的结构体的对齐数)的整数倍。
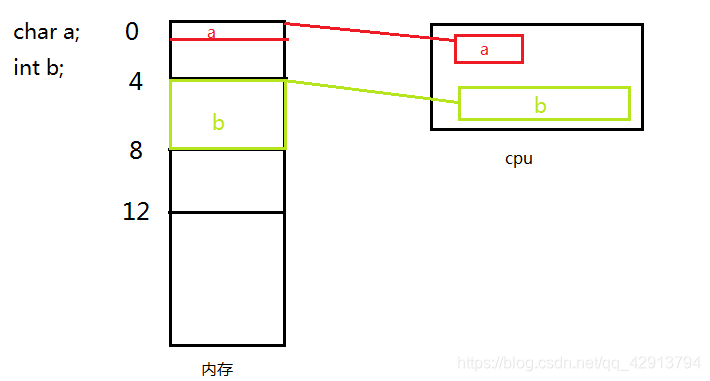
那么清楚了规则之后我们再来看这个题目就很明朗了。
如图:变量a占一个字节,所以可以被cpu直接读取写入,b占4个字节,所以b从起始偏移量为4的地方开始存储,这样在cpu读取b只需访问内存一次。
通常在设计结构体的时候,我们既要满足对齐,又要节省空间,所以我们要让占用空间小的成员尽量集中在一起。
例如:
struct s1
{
char c1;
int i;
char c2;
};
struct s2
{
char c1;
char c2;
int i;
};
在上面这段代码里,s1和s2类型的成员一模一样,但是s1和s2所占空间大小有了一定的区别。
