文章目录
引言
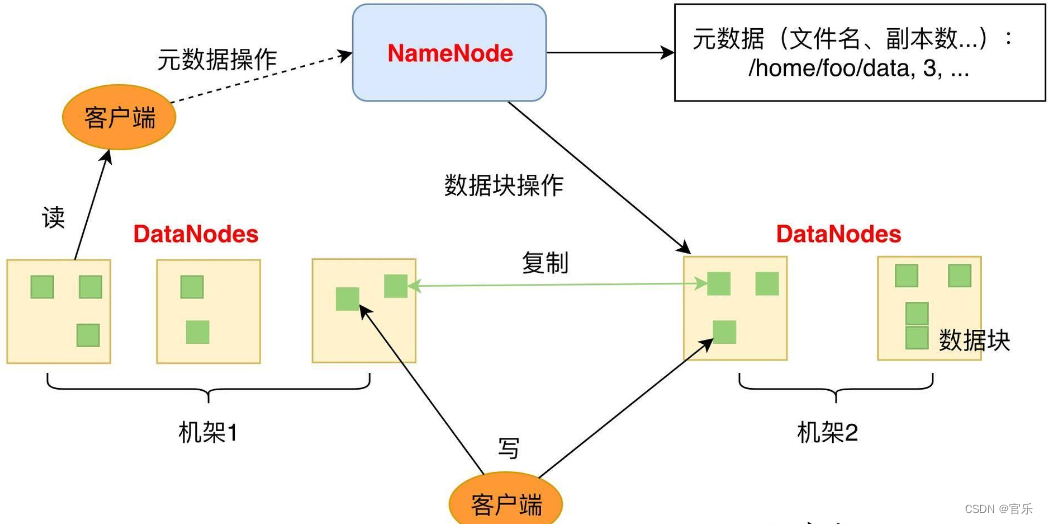
HDFS(Hadoop Distributed File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统。采用“客户机/服务器”(Client/Server)模式。
1. 基本特征
1.1 高容错性
HDFS设计快速自动进行错误检测和恢复的相应机制。若一个节点出现故障,会自动补充其他节点上的备份。
1.2 数据容量大
支持数百个节点,满足大数据需求。
1.3 可扩展性
水平扩展性强,根据需要对数据节点进行增删。
1.4 高吞吐量
数据传输率高,支持高并发大数据应用程序。
1.5 就近计算
客户请求尽量在数据节点上直接完成计算任务,方便降低数据传输负担,增加吞吐量。
2. 体系架构
2.1 NameNode
NameNode维护着整个文件系统的文目录树,包括文件/目录的元数据和每个文件对应的数据块列表,负责接收用户的操作请求。其主要任务如下:
(1)管理命名空间(Namespace);
(2)控制客户端对文件的读/写;
(3)执行常见文件系统的操作。
保存了FsImage和EditLog两个核心数据结构,其中FsImage用于维护文件系统树以及文件树中所有文件和目录的元数据;操作日志文件EditLog记录了所有针对文件的创建、删除、重命名等操作。NameNode在启动时会将FsImage文件的内容加载到内存中,然后执行EditLog中的各项操作,使得内存中的元数据保持最新。
2.2 DataNode
DataNode将HDFS数据以文件的形式存储在本地的文件系统的一个单独的文件中,不在同一目录下,并不知道有关HDFS文件的信息。
3. 存储机制
3.1 Block
HDFS中的数据以文件块Block的形式存储,为每次读写的最小单元。Hadoop2.0默认大小为128MB,可以通过配置hdfs-site.xml中的参数dfs.blocksize来修改块大小,需为2的k次方大小。
3.2 副本管理策略
采用多副本方式对数据进行冗余存储,将一个数据块的多个副本存储到不同的DataNode上,默认情况下每个块有三个副本,放置基本原则是保证并非所有的副本都在同一个机架(Rack)上。如:
第一个副本在client所在节点,第二个副本在同机架上的另一个节点,第三个副本放置在另一个机架的随机一个节点。
4.数据读写过程
4.1 数据的读取过程
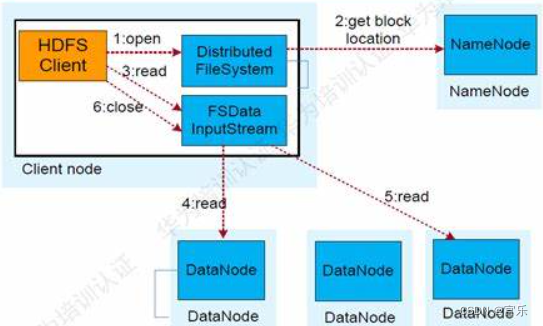
①打开文件。使用DistributedFileSystem对象的open()方法打开HDFS上的一个文件;
②获取数据块信息。通过RPC(远程过程调用)调用向NameNode发出请求,得到文件的位置信息,即数据块编号和所在DataNode地址;
③读取请求。客户端向FSDataInputStream发出读取数据的read()请求;
④读取数据。DFSInputStream选择最近的数据块进行读取并返回给客户端,读取完成后关闭相应的DataNode链接;
⑤读取数据。DFSInputStream依次选择最近的DataNode节点,读取并返回,直到最后一个数据块读取完毕(若遇到某个DataNode失效,会自动选择下一个包含此数据块的DataNode进行读取);
⑥关闭文件。客户端读取完所有的数据块后,调用FSDataInputStream的close()方法关闭文件;
4.2 数据的写入过程
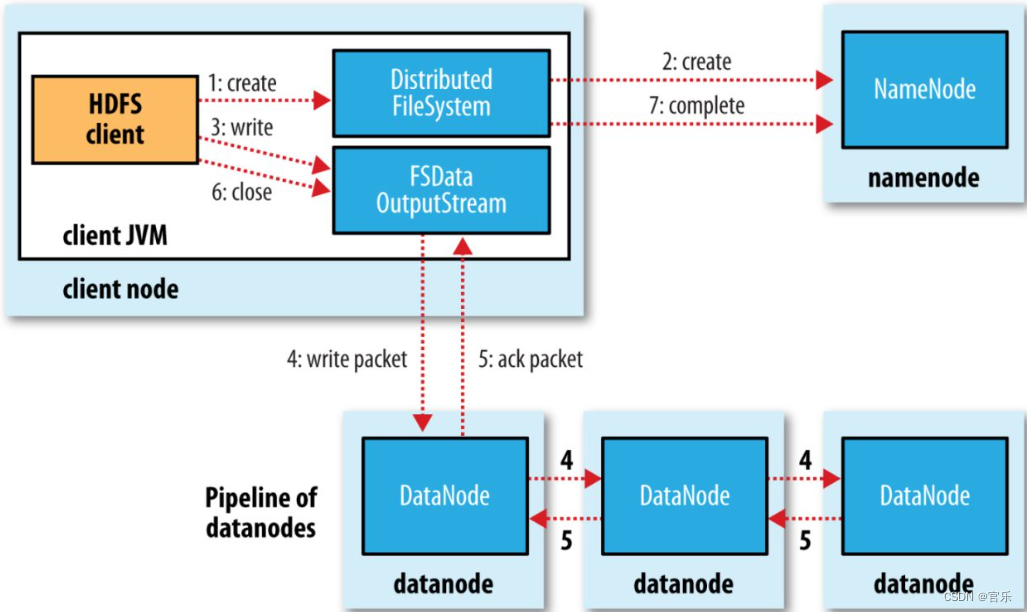
①创建文件请求。客户端调用FileSystem对象的create()方法来创建文件;
②创建文件元数据。用RPC(远程过程调用)调用名称节点,在文件系统的命名空间中创建一个新的文件;
③写入数据。通过FSDataOututStream对象,开始写入数据;
④写入数据包。由DFSOutputStream将数据分成块,写入data queue。data queue由Data Streamer读取,并通知名称节点分配数据节点,以存储数据块(每块默认复制三块)。分配的数据节点放在一个数据流管道(pipeline) 里。Data Streamer将数据块写入pipeline中的第一个数据节点,第一个数据节点将数据块发送给第二个数据节点,即边存边写;
⑤接收确认包。DFSOutputStream为发出去的数据块保存了ack queue,等待pipeline中的数据节点告知数据已写入成功;
⑥关闭文件。数据全部写入后调用close(),将所有的数据块写入pipeline中的数据节点,并等待ack queue返回成功;
⑦写操作完成。通知名称节点写入完成;
5.Java API编程
//从URL读取HDFS文件
public class HDFSURLReader{
static{
//此处设置文件系统配置为URL流,仅执行一次
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
}
public static void main(String[] args){
InputStream stream = null;
String hdfssurl = "hdfs://192.168.18.130:9000/data/input.txt");
try{
//打开远程HDFS文件系统的文件
stream = new URL(hdfsurl).openStream();
//输出文件内容到标准输出(默认为屏幕)
IOUtils.copyBytes(stream, Ststem.out, 1024, false);
}catch(IOException e){
IOUtils.colseStream(stream);// 关闭文件
}
}
}
6.HDFS的高可靠性机制
6.1 心跳机制
HDFS通过心跳来检测DataNode是否出错。每个DataNode节点周期性地向NameNode发送心跳信号,而NameNode通过心跳信号检测来确认DataNode是否出错,若检测近期不再发送心跳信号的DataNode,会将其标记为“宕机”,不会将新的I/O请求发送给他们。宕机引起副本数量低于预期时,NameNode会启动复制操作。
6.2 Secondary NameNode
Secondary NameNode(2NN)主要用于将NameNode的EditLog合并到FsImage文件中,即对元数据定期更新和备份。防止EditLog文件过大时,重启会花费较长时间。详细过程如下:
①Secondary NameNode通知NameNode切换EditLog文件;
②Secondary NameNode通过网络从NameNode下载FsImage和EditLog;
③Secondary NameNode将FsImage载入内存,然后开始合并EditLog日志;
④Secondary NameNode将新的FsImage发回给NameNode;
⑤NameNode用新的FsImage替换旧的FsImage;
6.3 HDFS NameNode HA的高可用机制
HDFS NameNode HA(High Availability)HDFS NameNode高可用机制,用以解决NameNode单点故障问题。
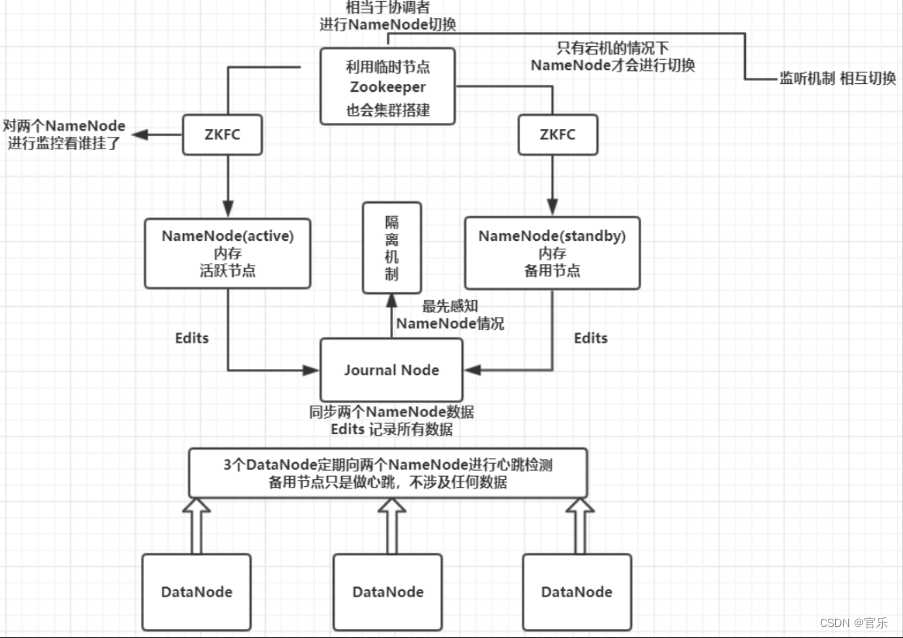
1)ZooKeeper集群:为主备切换控制器提供主备选举支持;
2)主备切换控制器(Active/Standby ZKFailoverController,ZKFC):及时检测NameNode的健康状况,会话管理,在主NameNode发生故障时借助ZooKeeper自动地主备选举和切换;
3)主备NameNode(Active/Standby NameNode):Active NameNode负责所有客户端操作,Standby NameNode充当slave,负责维护状态信息,以便在需要时实现快速切换;
4)共享存储系统(JournalNode 集群):同步Active/Standby NameNode的状态。利用称为“JournalNode”的一组独立进程通信,使得Standby NameNnode从中读取EditLog并应用到自己的命名空间,实现状态同步;
5)DataNode:DataNode会同时向主备NameNode报告数据块的位置信息,但只接收来自主NameNode的读写命令;
总结
以上就是关于HDFS的内容,欢迎大家在评论区补充。
参考《Hadoop大数据原理与运用》徐鲁辉