Hadoop学习
一.概述
1.Hadoop是一套开源、可靠、可伸缩的分布式机制
2.大数据生态系统中的基础框架,超过70%的技术或者产业是围绕Hadoop产生的
3.Hadoop提供了简单的编程模型来对大量数据进行分布式处理
4.Hadoop你能够一台服务器扩展到千台,每一台服务器能够提供计算和存储功能
5.Hadoop本身提供了探测和处理异常的机制
6.Hadoop的发行版本
a.Apache Hadoop:最基础、最原始的版本。相对而言,不熟和维护比较复杂,但是适合于初学者,因为它没有将细节隐藏,更适合于理解底层机制
b.CHD:要钱
c.HDP要钱
二.版本
1.Hadoop1.X:包含了Common、HDFS和MapReduce模块。现在市面上已经停止使用
2.Hadoop2.X:包含了Common、HDFS、MapReduce以及Yarn模块。从Hadoop2.7版本开始,还包含了Ozone模块。Hadoop2.X和Hadoop1.X全版本不兼容
3.Hadoop3.X:包含了Common、HDFS、MapReduce、YARN和Ozone模块。Hadoop3.X和Hadoop2.X全版本不兼容
三.模块
1.Hadoop Common:公共依赖模块
2.Hadoop Distributed File System(HDFS):分布式文件系统,解决存储问题
3.Hadoop YARN:负责任务调度和集的资源管理
4.Hadoop MapReduce:基于YARN的分布式计算系统
5.Hadoop Ozone:对象存储
四.安装模式
1.单机模式:在一台服务器上安装Hadoop,只能启动Hadoop和MapReduce模块
2.伪分布式:在一台服务骑上安装Hadoop,利用多个进程来模拟Hadoop集群环境,能够启动Hadoop的绝大部分主要服务
3.完全分布式:在集群中安装Hadoop,能够启动Hadoop中的所有的服务
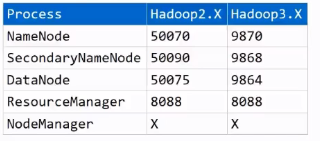
五.web访问端口
HDFS学习
一.概述
1.HDFS(Hadoop Distributed File System - Hadoop分布式文件系统)是Hadoop 提供的一套用于进行分布式存储的机制
2.HDFS是Doug Cutting根据Google的论文(GFS)来仿照实现的
二.基本结构
1.HDFS本身是一个典型的主从(M/S)结构:主节点是NameNode
2.HDFS会对上传的文件进行切分处理,切出来的每一个数据块Block
3.HDFS会对上传的文件进行自动备份。每一个备份称之为是一个副本(replication/replicas)。如果不指定,默认情况下,副本数量为3
4.HDFS仿照Linux设计了一套文件系统,允许将文件存储到不同的虚拟路径下,同时也设计了一套和Linux一样的权限策略。HDFS的根路径是/
二.Block
1.Block是HDFS中数据存储的基本形式,即上传到HDFS上的数据最终都会以Block的形式落地到DataNode的磁盘上
2.如果不指定,默认情况下,Block的大小事1342177288(即128M)。可以通过dfs.blocksize属性来调节,放在hdfs-site.xml文件中,单位是字节
3.如果一个文件不足Block的指定大小,那么这个文件是多大。例如一个文件是70M,那么对应的Block就是70M。属性dfs.blocksize指定的值实际上可以理解一个Block的最大容量
4.注意,在设计Block大小的时候,Block是维系在DataNode的磁盘上,要考虑Block在磁盘上的寻址时间以及传输时间(写入时间)的比例值。当寻址时间是传输时间的1%的时候,效率最高。而计算机在磁盘上的寻址时间大概在10ms左右,那么写入时间就是10ms/0,.01=1s。考虑到绝大部分的服务器使用的是机械磁盘,机械磁盘的写入速度一般120MB/s左右,此时一个Block大小是1s*120MB左右
5.HDFS会成为每一个Block来分配一个唯一的编号BlockID
6.切块的意义
a.能够存储超大文件
b.能够进行快速备份
三.NameNode
1.NameNode是HDFS中的主(核心)节点。在Hadoop1.X中,NameNode只能有1个,容易存在单点故障;在Hadoop2.X中,NameNode最多允许存在2个;在Hadoop3.X中,不再限制NameNode的数量,也因此在Hadoop3.X的集群中,NameNode不存在单点故障
2.NameNode的作用:对外接受请求,记录元数据(大概可以将元数据理解为账本),管理DataNode
3.元数据(metadata)是用于描述的数据。在HDFS中,元数据实际上是用于描述文件的一些性质。在HDFS中,将元数据拆分成很多项,主要包含了一下几项
a.上传的文件名以及存储的虚拟路径,例如/log/a.log
b.文件对应的上传用户以及用户组
c.文件的权限,例如-rwxr-xr–
d.文件大小
e.Block大小
f.文件和BlockID的映射关系
g.BlockID和DataNode的映射关系
h.副本数量等
4.一条元数据大小大概在150B左右
5.元数据是维系在内存以及磁盘中
a.维系在内存中的目的是查询块
b.维系在磁盘中的目的是持久化
6.元数据在磁盘上的存储位置由hadoop.tmp.dir来决定,是放在core-site.xml文件中。如果不指定,默认情况下是放在/tmp下
7.和元数据相关的文件
a.edits:写操作文件。用于记录HDFS的写操作
b.fsimage:元映像文件。存储了NameNode对元数据的序列化形态(大概可以理解为元数据在磁盘上的持久化存储形式)
8.当NameNode接受到写操作(命令)的时候,会先将这个写操作(命令)记录到edits_inprogress文件中。记录成功之后,NameNode会解析这个命令,然后修改内存中的元数据。修改成功之后,会给客户端返回一个ACK信号表示成功。在这个过程中,会发现,fsimage文件中的元数据并没有发生边变化

9.随着运行时间的推移,edits_inprogress文件中记录的命令会越来越多,同时fsiage文件中的元数据和内存中的元数据差别也会越来越大。因此,当达到指定条件的时候,edits_inprogress这个文件会产生滚动,滚动生成一个edits文件,同时产生一个新的edits_inprogress文件。新来的写操作会记录到新的edits_inprogress文件中。滚动生成edits文件之后,NameNode会将edits文件中的命令再一一取出,解析之后修改fsimage文件中的元数据

10.edits_inprogress文件的滚动条件
a.空间:当edits_inprogress文件达到指定大小(默认是40000,即当edits_inprogress文件中记录的元数据达到40000条,可以通过属性dfs,namenode.checkpoint.txns来修改,放在hdfs-site.xml文件中)的时候,会自动滚动生成一个edits文件
b.时间:当距离上一次的滚动时间间隔达到指定大小(默认是3600s,可以通过属性dfs.namnode.checkpoint.period来修改,单位是秒,放在hdfs-site.xm;文件汇总)的时候,edits_inprogress文件也会产生滚动
c.重启:当NameNode被重新启动的时候,会自动触发edits_inprogress文件的滚动
d.强制:可以通过hdfs dfsadmin -rollEdits命令来强制滚动
11.查看edits文件:hdfs oev -i edits_000000000000002-000000000000009 -o edits.xml
12.在HDFS中,会将每一个写操作看作是一个事务,会给这个事务分配一个全局递增的编号,称之为事务id,简写为txid
13.在HDFS中,会将开始记录日志以及结束记录日志都看做是一个写操作,都会分配一个事务id。因此,每一个edits文件,基本上都是以OP_START_LOG_SEGMENT开头,都是以OP_END_LOG_SEGMENT结尾
14.查看fsimage文件hdfs oev -i fsimage_000000000000009 -o fsimage.xml
15.每一个fsimage文件都会伴随着产生一个.md5文件,这个文件是对fsimage文件进行校验的
16.需要注意的是,Hadoop在第一次启动之后的1min的时候,会自动触发一次edits_inprogress文件的滚动,之后就按照指定的时间间隔来进行滚动
17.NameNode通过心跳机制来管理DataNode:DataNode会定时(默认是3s,通过属性dfs.heartbeat.interval来决定,单位是秒,放在hdfs-site.xml文件中)给Namenode发送心跳。如果超过指定的时间,NameNode没有收到DataNode的心跳,那么NameNode就会认为这个DataNode已经lost(丢失),此时NameNode会将这个DataNode上的数据数据复制一份备份到其他节点上来保证整个集群中的副本数量
18.心跳的超时时间是由属性dfs.namenode.heartbeat.recheck-interval来决定。如果不指定,默认是300000,单位是毫秒,即300s=5min。但是在计算超时的时间=2dfs.namenode.heartbeat.recheck-interval-interval+10dfs.heartbeat.interval来决定,所以如果不指定,实际超时时间为25min+103s = 10min30s
19.心跳信号主要包括
a.clusterid:集群编号
①在HDFS中,当NameNode被格式化(hadoop namenode -format)的时候,会自动计算产生一个clousterid。每次nameNode被格式化,都会自动重新计算产生一个新的clusterid
②当HDFS集群启动之后,NameNode就会等待DataNode的心跳。当NameNode第一次收到DataNode的心跳之后,会将clusterid在心跳响应中返回给DataNode
③当DataNode收到心跳响应之后,会将clusterid获取并记录到本地的磁盘中,之后DataNode和NameNode之间的每一次通信(包括心跳)都会携带这个clusterid
④NameNode在收到DataNode的请求之后,会先校验clusterid是否一致,如果不一致,则会放弃这个请求;如果一致,才会处理这个请求
⑤如果NameNode被重新格式化,就会导致DataNode和NameNode之间无法进行通信
b.当前DataNode的节点状态(预服役、服役、预退役)
c.当前DataNode上存储的Block的校验信息
20.安全模式
a.当NameNode被重启之后,会自动进入安全模式
b.在安全模式中,NameNode会先自动触发edits_inprogress文件的滚动,滚动完成之后,会触发fsimage文件的更新。fsiamge文件更新完成之后,NameNode会将fsimage文件中的元数据加载到内存中,加载完成之后,会等待DataNode的心跳
c.若果没有DataNode的心跳,那么说明NameNode被重启过过程中,DataNode也出现了故障,此时NameNode就需要将DataNode上的数据备份到其他节点上来保证集群中的副本数量;如果NameNode收到了DataNode的心跳,会校验DataNode上的Block信息。如果校验失败,那么NameNode会试图恢复这个DataNode上的数据,恢复完成之后会再次校验,如果校验失败,则重新恢复重新校验;如果又校验失败,那么NameNode则再次重新恢复重新校验循环;如果校验成功,则NameNode自动退出安全模式
21.之所以存在安全模式,实际上是HDFS集群保证数据的完整性
22.在安全模式中,HDFS集群只能读(下载)不能写(上传)
23.在实际过程中,如果在合理时间内,HDFS集群依然没有退出安全模式,则说明数据已经产生了不可挽回的丢失,此时需要考虑强制退出安全模式
24.常见命令

四.DataNode
1.DataNode是HDFS的从节点,主要用于存储数据,数据会以Block形式落地到磁盘上
2.数据在磁盘上的存储位置同样由hadoop.tmp.dir属性来决定
3.DataNode会为每一个Block生成一个blk_xxx.meta文件,这个meta文件实际上是blk文件的校验文件爱你
4.DataNode的状态:预服役、服役、预退役、退役、丢失
5.DataNode通过心跳机制向NameNode来注册信息
五.SecondaryNameNode
1.SecondaryNameNode不是NameNode的热备份,但是SecondaryNameNode能够一定程度上对元数据做到备份,但不是全部 - SecondaryNameNode主要是负责edits_inprogress文件的滚动和fsimage文件的更新
2.在集群中,如果存在SecondaryNameNode,那么edits_inprogress文件的滚动和fsimage文件的更新是由SecondaryNameNode来完成;如果没有SecondaryNameNode,那么edits_inprogress文件的滚动和fsimage文件的更新就会由NameNode自己来完成
3.到目前为止,HDFS集群只支持两种结构
a.1个NameNode+1个SecondaryNameNode+n个DataNode
b.n个Name(Hadoop2.X中是2个,Hadoop3.X中是n个,1个Active+多个standy状态)+n个DataNode
4.在HDFS集群中,NameNode如果只有1个,那么NameNode宕机之后,整个集群就无法对外提供服务,所以必须对NameNode来进行备份,避免单点故障,所以在集群中,要考虑使用上述的第二种方案
六.机架感知策略
1.在HDFS中,机架感知策略默认是不开启的。如果需要开启机架感知策略,那么需要hadoop-site.xm;文件中添加如下配置
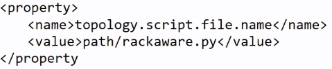
2.上述配置的value中,需要指定一个脚本文件的存储路径。脚本文件可以使用Python或者Shell等常见脚本语言来实现
3.在这个脚本中,需要定义一个Map。Map的键是主机名或者IP,Map的值是用户指定的机架名。只要保证值一致,那么就表示值对应的键放在同一个机架上
4.由于这个机架式通过Map映射来完成的,所以本质上是一个逻辑机架,也因此可以将不同物理机架上的节点配置在同一个逻辑机架上。在实际开发过程中,为了方便管理,往往是将同一物理机架上的节点配置在同一逻辑机架上
七.副本放置策略
1.在HDFS中,支持多副本策略,这样能够有效的保证数据的可靠性。如果不指定,默认情况下,副本数为3.通过属性dfs.replication来修改,放在hdfs-site.xml文件中
2.在HDFS中,如果没有开启机架感知策略,那么默认也不会开启副本放置策略,那么此时多个副本是放在相对空闲的节点上
3.如果启用了机架感知策略,那么对应的,HDFS也会启用副本放置策略
a.第一个副本:如果是集群内上传,则谁上传就放在谁身上;如果是集群外上传,则谁空闲就放在谁身上
b.第二个副本:放在和第一个副本相同的机架的节点上。实际过程中,会考虑将同一个物理机架上的节点配置在同一个逻辑机架上,此时机架内传输会比跨机架传输要快一些
c.第三个副本:放在和第二个副本不同机架的节点上,保证不会因为一个机架整体出现故障导致数据产生丢失
d.更多副本:谁空闲放在谁身上
八.常见命令

九.垃圾回收机制
1.在HDFS中,回收机制默认是不开启的,此时删除命令会立即生效,且该操作此时不可逆
2.配置回收站策略,配置在cores-site.xml中

3.回收站默认存放位置为/user/root/.Trash/Current/
4.如果需要将文件从回收站中还原回来,那么使用hadoop fs -mv命令即可
十.写(上传)流程
1.客户端发起RPC请求到NameNode,请求上传文件
2.当NameNode收到请求之后,会先进行校验
a.校验是否有指定路径 - FileNotFoundExecption
b.校验是否有写入权限 - AccessControlExecption
c.校验是否有同名文件 - FileAlreadyExistException
3.如果校验失败,则直接报错;如果校验成功,则NameNode会给客户端返回信息号表示允许上传
4.当客户端收到信息之后,会再次给NameNode来发送请求,请求获取一个Block的存储位置
5.NameNode收到请求之后,会将这个Block的存储位置(实际上是DataNode的IP或者主机名,默认情况下会返回3个存储位置 - 副本数量为3)返回给客户端
6.客户端收到存储位置之后,会从这些地址中选取一个较近(实际上是网络拓扑距离)的地址,发送请求,请求建立pipeline(管道,实际上是基于NIO Channel)用于传输数据;第一个Block所在节点会给下一个Block所在的节点发送请求,请求建立pipeline;依次类推,直到最后一个请求应达成功
7.建立好管道应答成功之后,客户端会将当前的B lock进行封包,将Packet写入第一个节点;写完之后,第一个Block所在的节点写入第二个节点,依次类推
8.当这个Block的所有副本写完之后,客户端会再次给NameNode发送请求,请求获取下一个Block的存储位置,重复5,6,7,8四个步骤,直到所有的Block全部写完
9.当客户端写完所有的Block之后,会给NameNode发送一个请求,请求关闭文件(关流)。文件一旦关闭,数据就不能修改

十一.读(下载)流程
1.客户端发起RPC请求道NameNode,请求下载文件位置
2.NameNode收到请求之后,会先进行校验
a.校验是否有读取权限 - AccessControlException
b.校验是否有指定文件 - FileNotFoundException
3.如果校验失败,会直接报错;如果校验成功,则NameNode就会给客户端返回一个信号表示允许读取
4.客户端收到信号指挥,会再次发送请求给NameNode,请求获取第一个Block的存储位置
5.NameNode收到请求之后,会查询元数据,然后将这个Block的存储地址(默认情况下是3个)返回给客户端
6.客户端收到地址之后,会从这些地址中选取一个较近的地址来读取这个Block
7.读取完这个Block之后,客户端会对这个Block进行checkSum校验。如果校验失败,说明这个Block产生了变动,此时客户端会从剩余的地址中重新选取一个地址重新读取校验;如果校验成功,则客户端会再次给NameNode发送请求,请求获取下一个Block的存储位置,重复5,6,7,三个步骤,直到读取完所有的Block
8.当客户端读取完最后一个Block之后,会给NameNode发送一个结束信号。NameNode收到信号之后会关闭这个文件

十二.删除流程
1.客户端发起RPC请求道NameNode,请求删除文件
2.NameNode收到请求之后,会先进行校验
a.校验是否有读取权限 - AccessControlException
b.校验是否有指定文件 - FileNotFoundException
3.如果校验失败,则直接报错;如果校验成功,则NameNode会将这个写请求记录到edit_inprogress文件中,记录成功之后,会修改内存中的元数据;修改完成之后,NameNode会给客户端返回ACK信号表示删除成功。需要注意的是,此时文件中并没有真正从HDFS上移除,仅仅是修改了元数据
4.NameNode给客户端返回信号之后,就会等待DataNode的心跳。NameNode在收到DataNode的心跳之后,会在心跳响应中要求DataNode删除对应的Block
5.DataNode在收到心跳响应之后,会按照NameNode的要求,去磁盘上删除文件对应的Block。注意,此时文件才真正的从HDFS上移除
十三.总结HDFS的特点
1.能够存储超大文件。在HDFS集群中,只要节点数量足够多,那么一个文件无论是多大都能够进行存储 - HDFS会对文件进行切块处理
2.快速的应对检测故障。在HDFS集群中,运维人员不需要频繁的监听每一个节点,可以通过监听NameNode来确定其他节点的状态 - DataNode会定时的给NameNode来发送心跳
3.具有高容错性。在HDFS中,会自动的对数据来保存多个副本,所以不会因为一个或者几个副本的丢失就导致数据产生丢失
4.具有高吞吐量。吞吐量实际上指的是集群在单位时间内读写的数据总量
5.可以相对在廉价的机器上来进行横向扩展
6.不支持低延迟的访问。在HDFS集群中,响应速度一般是在秒级别,很难做到在毫秒级别的响应
7.不适合存储大量的小文件。每个小文件都会产生一条元数据,大量的小文件就会产生大量的元数据。元数据过多,会占用大量内存,同时会导致查询效率变低
8.简化的一致性模型。在HDFS中,允许对文件进行一次写入多次读取,不允许修改,但是允许追加写入
9.不支持超强事务甚至不支持事务。在HDFS中,因为数据量较大,此时不会因为一个或者几个数据块出现问题就导致所有的数据重新写入 - 在数据量足够大的前提下,允许出现容错差