Hadoop HA 搭建:
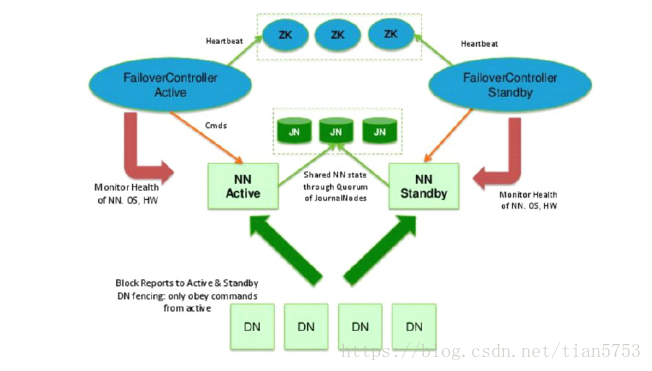
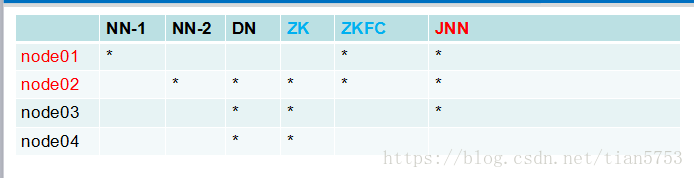
准备四台机器:
1.配置hdfs-site.xml 文件
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node1:8485;node2:8485;node3:8485/mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/ftian/hadoop/ha/jn</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>2.core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/var/sxt/hadoop/local</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:2181,node3:2181,node4:2181</value>
</property>配置完成后向node2,node3,node4分发 hdfs-site.xml,core-site.xml文件

3.配置zookeeper(node2)
把zoo_sample.cfg文件重新命名为zoo.cfg.
conf/zoo.cfg
dataDir=/var/sxt/zk
在zoo.cfg文件末尾加:
server.1=192.168.64.12:2888:3888
server.2=192.168.64.13:2888:3888
server.3=192.168.64.14:2888:3888
/var/sxt/zk
在zk文件下 执行:echo 1 > myid (在node2,node3,node4分别执行)
分发给node3,node4.
4.启动配置
1).zkServer.sh start(node2,node3,node4) 在node1上格式化 hdfs zkfc -formatZK
2).hadoop-daemon.sh start journalnode(node1,node2,node3)
3).node1
hdfs namenode –format
hadoop-deamon.sh start namenode
node2: hdfs namenode -bootstrapStandby
4).start-dfs.sh